fsync はなぜ時間がかかるのか
fsync について調べたことをまとめます。特に、最新の研究も含めて、ジャーナリングやメタデータの整合性について書いていこうと思います。
読んでいただけると、ファイルシステムが裏でどのようにデータを永続ストレージへ書き出しているかについての理解が少しだけ深まるかもしれません。
勉強していた時に、もう少し細かく挙動を説明してくれる資料があればいいなぁと強く思ったのを覚えていて、今回この記事を書いてみようと思いました。これから勉強される方の参考になればと思います。
いざ書き始めると前提とする情報があまりに多かったので、別の記事にして背景を最初にまとめることにしました。内容についてわかりにくいと思われましたら、適宜過去の記事を参照いただけましたら理解の助けになるかもしれません。
fsync
fsync は指定したファイルのデータの永続性を保証するために利用されるシステムコールです。
Linux の Man page of fsync によると、fsync は以下のように説明されています。
int fsync(int fd) fsync() は、ファイルディスクリプター fd で参照されるファイルの、メモリー内で存在する修正されたデータ (つまり修正されたバッファーキャッシュページ) を、ディスクデバイス(またはその他の永続ストレージデバイス) に転送 (「フラッシュ」) し、これにより、システムがクラッシュしたり、再起動された後も、変更された全ての情報が取り出せるようになる。「フラッシュ」には、ライトスルー (write through) や (存在する場合には) ディスクキャッシュのフラッシュも含まれる。この呼び出しは転送が終わったとデバイスが報告するまでブロックする。またファイルに結びついた メタデータ情報 (stat(2) 参照) もフラッシュする。
fsync は他のファイル入出力のシステムコールと比較して時間がかかり、ソフトウェア性能のボトルネックになりがちです。fsync が速くなると、設定によりますが、データベースのようなシステムは高速になるケースが多くあります。
今回は、内部で何が起きているため時間がかかるのか、ということについて見ていきます。
大まかなスピード
時間がかかる、というのがどの程度であるかということについて、ある程度の感覚をつかむために、簡単に実験をしてみました。
Linux 5.3 で、ext4 という Ubuntu 等でデフォルトで使われているファイルシステムについて、一般的なコスト重視の SSD Crucial SSD 240GB (CT240BX500SSD1Z) を使って fsync にかかる時間を測りました。
手元の環境では、ファイルに 4KB のデータを書き込んで fsync を呼ぶと約 638 us かかりました。
一方、4 KB を書き込む write システムコールは、1.14 us 程度でした。時間あたりの書き込み量や、書き込む位置によりますが、時間に関するスケール感でいうと、write システムコールは fsync と比べるとかなり短い時間で済みます。
機能が異なるので、fsync と write システムコールにかかる時間を比較することに特に意味はありませんが、スピードの感覚として、fsync は比較的時間のかかる処理であるということは言えるかと思います。
fsync の概観
以下の図は、ファイルの書き込み処理の流れをおおまかに示しています。図の詳細については、過去の記事を必要に応じてご参照ください。
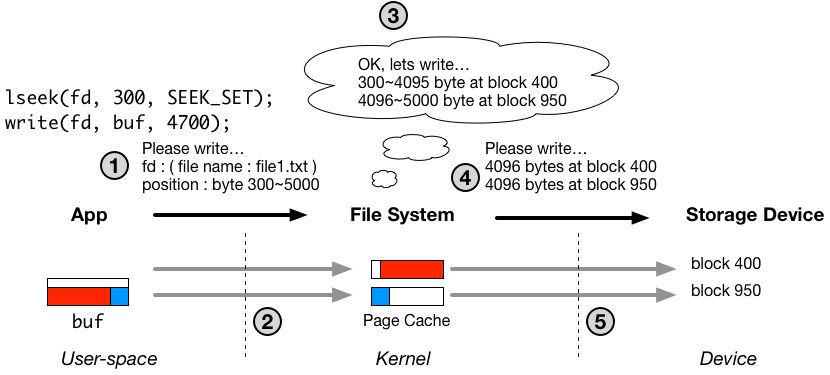
write システムコールが 1.14 us で完了できたのは、過去の記事にある通り、図中の1と2番の処理だけがシステムコール内部で行われ、3、4、5の部分は非同期なスレッドで行われるからです。番号1、2の処理は、主にユーザー空間からカーネル空間へのメモリコピーなので、そこまで時間はかかりません。
一方、fsync の実質的な機能は、明示的に、図中の3から5までの処理を行うように書き込みスレッドにリクエストする(もしくは自分で3から5までの処理を行う)ことです。fsync は、リターンするタイミングでファイルの永続性を保証するために、ディスクへの書き込みを含む3から5までの処理が完了するまで待機する必要があるため時間がかかります。
図では簡略化されていますが、3から5の間には複雑な処理が含まれており、この記事ではそこについて掘り下げていこうと思います。
ストレージデバイスにおける永続性の保証
fsync の速度はディスクのハードウェア特性、特に永続性に関する点に起因するところが多分にあります。
永続ストレージデバイス内の揮発性キャッシュメモリ
現在、一般的に広く使われている HDD や SSD は、永続的な保存領域とは別に、内部的に揮発性メモリでできたキャッシュを持っており、デバイスドライバを通じて送られてきたデータはまず、そのキャッシュに置かれます。それらのストレージデバイスは、キャッシュに置かれたデータを適宜、永続的なデータの保存領域へ移動させていきます。
一般的に、キャッシュへの書き込みは、デバイスの永続的な保存領域への書き込みに比べてかなり高速なため、キャッシュは書き込みの遅延を低減することに大きく貢献します。
しかし、想像がつかれたかと思いますが、ただデータがストレージデバイスのキャッシュに乗っただけでは、転送されたデータが永続的になるわけではありません。
データがキャッシュに乗った状態で、例えば停電が発生し、ディスクへの給電が止まった場合、キャッシュ上にあったデータは、キャッシュが揮発性メモリでできているため消えてしまいます。
永続領域への書き込み順の不確実さ
ディスクを扱うことの難しさの原因の一つに、キャッシュから永続的なデータ保存領域へのデータの移動が、データが転送されてきた順番によらないということがあります。
つまり、ディスクのブロック番号1、2、3番に向けて書き込むべきデータが、1、2、3の順番通りキャッシュに到着したとしても、ディスクは、必ずしも1、2、3、の順番で永続的な保存領域に移動させるとは限らないということです。
ディスクのキャッシュのフラッシュリクエスト
ディスクには、先述の通り2点、
- ディスクは内部にキャッシュを保持しており、ディスクのキャッシュに届いたデータがすぐに永続的になるわけではない
- ディスクがキャッシュから、永続的な保存領域へデータを移動させる場合の順番は、データがキャッシュに届いた順番と同じとは限らない
のような不確実性がハードウェアの特性としてあります。
HDD や SSD のようなストレージデバイスは、このような不確実さにソフトウェア側から対応が可能なように、デバイスのキャッシュ上のデータを、永続的なデータ保存領域へ移動させることを明示的にリクエストできる、フラッシュコマンドを実装しています。
重要な特性として、ストレージデバイス上のキャッシュから、永続保存領域へのデータの移動はとても時間がかかります。なので、フラッシュコマンド自体の発行から完了までの時間も必然的に長くなります。
実は、このフラッシュコマンドが、fsync に時間がかかる大きな要因となっています。以降、なぜ、ファイルシステムがディスクのキャッシュをフラッシュしなければならないのかについて書いていきます。
クラッシュ後の整合性
ファイルシステムにとって、クラッシュ後(例えば想定していない停電後)に、ディスク上に保存されたデータが破損しないということは最重要の機能要件の一つです。特に、そのためには、クラッシュ後のメタデータの整合性が重要になります。
なぜ、メタデータの整合性と fsync が関係あるのかというと、メタデータのディスクへの書き込みが fsync の中で行われるからです。
fsync の内部では、ディスクへの書き込み最中にシステムがクラッシュしてもメタデータの整合性が担保できるような書き込み方法を実装しています。
一般的に、データの整合性を担保する書き込み手法として、ジャーナリングもしくは、ファイルシステムのディスク上のレイアウトをログ構造にする、という2通りの方法が用いられています。
それらの仕組みでは、一つのデータをディスクに書き込むだけで、ストレージデバイス上のキャッシュのフラッシュリクエストを複数回発行する必要があり、そのフラッシュリクエストが fsync に時間がかかる主な要因になっています。
ジャーナリング
今回は、ジャーナリングという仕組みがどのようなもので、なぜストレージデバイスのキャッシュのフラッシュが必要なのかについて見ていきます。
メタデータのディスクへの書き出し
ファイルシステムは、ファイル自体のデータだけでなく、ファイルという抽象化のために必要な様々なメタデータをディスク上に保存しています。
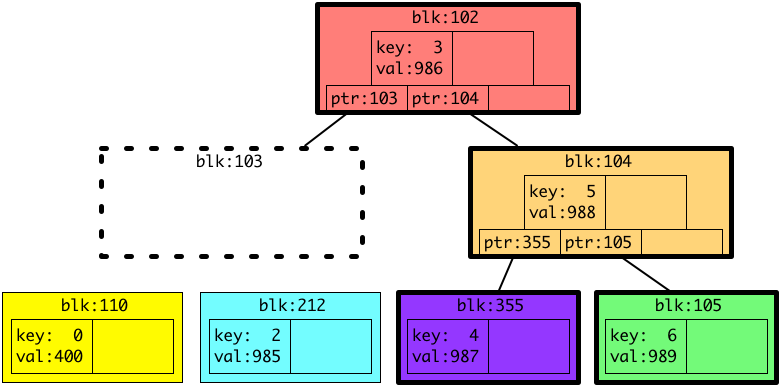
以下の図は、メタデータの例として、あるファイルのディスク上のデータの位置を保持するためのB木です。以下の図の説明を含めたメタデータにつきましては、以前の記事で触れておりますので、よろしければご参照ください。
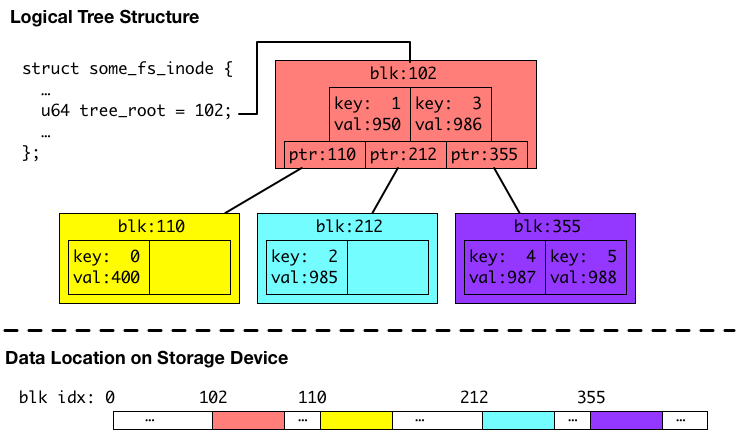
上の図の例のB木は、キーがファイル内のインデックスで、バリューがディスク上のファイルデータの位置のペアを保存しています。このB木の場合は、6つエントリーを保持していて、1エントリーあたり4キロバイトのブロックに対応しているので、24 KB のファイルのディスク上のデータの位置を保持している例になります。
ここでは、さらに4キロバイトファイルを(ファイル内のオフセット 24 KB ~ 28 KB にかけて)追記して、28 KB のファイルになった場合を考えます。この追記に関しては、通常の write システムコール等を通して行うことができます。
4キロバイトのデータがファイルへ追加されると、ファイル内の 24 KB ~ 28 KB (インデックス6)のデータがディスクのどこにあるかを保存するために、B木へ追加されます。ファイルシステムは、今回の例ではなんとなく、新しいデータをディスクの 989 番におくことにしたようです。
今ある B木にキー6、バリュー 989 を追加すると、B木の仕様によって、以下のように形が変わります。(今回の例では、一つの色つきブロック(ノード、リーフ)が2つしかエントリーを保持しませんが、実際は1つのブロックは4KB(もしくはその倍数)で、エントリーはブロックに収まるだけ保持されることにご注意ください。)
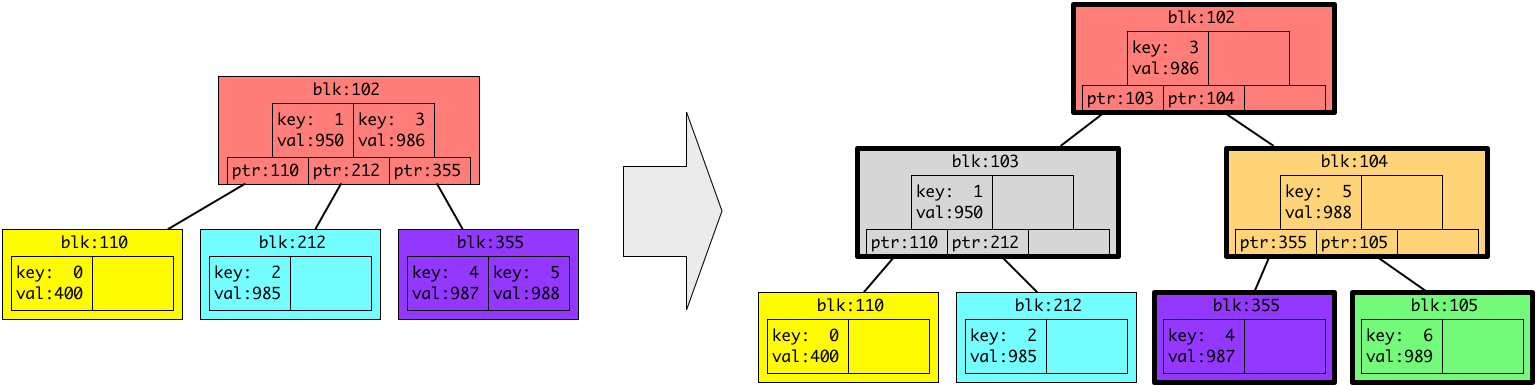
上の図では、新しいデータを保存するために、3つ新しい灰色、オレンジ、緑のブロック(ノード、リーフ)が追加されています。また、太い枠で囲われている色つきのブロックが新しく追加された、もしくは内容が変更されたブロックです。
これらの追加、変更されたB木(メタデータ)は、新しくファイルの 24 KB から 28 KB にかけて追記されたファイルのデータと一緒にディスクへ書き込まれる必要があります。
B木がディスクへ書き込まれる様子を図にすると以下のようになります。このメタデータのディスクへの書き込みは、非同期の書き込みスレッドの中で実行されます。また、fsync は、この書き込みが完了するまで待機します。(もしくは、fsync のシステムコールコンテキストで実行するように実装することもできます。)
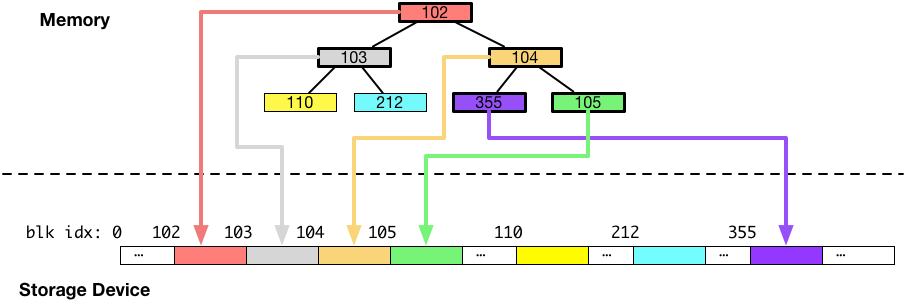
上図のように、ディスクをデータを書き込むことは一見簡単そうなのですが、書き込み中にシステムがクラッシュしてもB木のようなメタデータの整合性を失わないようにするには追加の配慮が必要になります。
回避したい状態
上図の例と同じB木の追加変更箇所をディスクに書き出している間に、システムがクラッシュすると、B木がどのような状態になる可能性があるかについて見ていきます。
今回は、ディスクのブロック番号 103 番に書かれるはずだったデータ(灰色のブロック)だけが、書き込みに失敗し、それ以外の部分が成功した例を考えます。書き込みに一部失敗した例を図にすると以下のようになります。
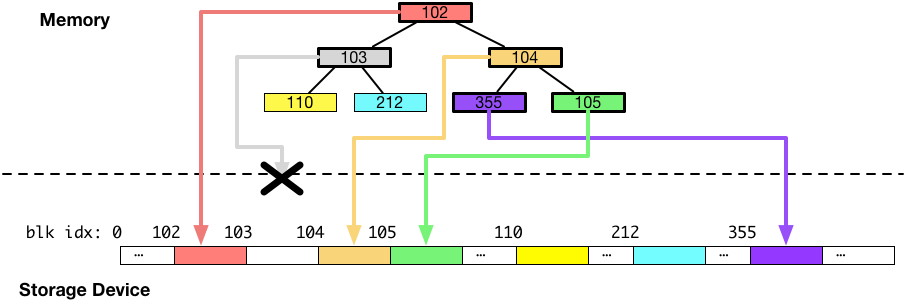
この状態で、システムを再起動すると、DRAM にあったデータは全て消えてしまっているので、ディスクの上にある情報だけでB木を再構成することになります。しかし、103 番に書かれるはずだったデータが書かれていないため、B木を再構成しようとすると以下のような状態になります。
B木でデータを探索する場合には、ルートからリーフ(図では上から下)へ向けて探索を行いますが、リーフへのポインタを保持しているはずの 103 番のブロックに書かれるべきデータが書かれなかった結果、ディスクに書かれなかったキー1に対応するバリューだけでなく、黄色と水色のブロック(リーフ)へのポインタを失ってしまい、B木としては、キー0、1、2に対応するバリューへのアクセス方法を完全になくしてしまっています。
このように、システムのクラッシュは、メタデータの欠損を引き起こす可能性があり、結果として、保存されたファイルのデータへアクセスできなくなってしまうことがあります。
上の例では、ファイルを読み込もうとしても、インデックス0〜2(0 B ~ 12 KB目)までのデータは、B木が破損してディスク上のデータの位置がわからなくなってしまったので、読み取ることができません。
ジャーナリングによる整合性の担保
ジャーナリングは、上の例のような、書き込みが中断された結果発生する、データの不整合を回避するための仕組みです。
ジャーナリングによって達成する機能は、クラッシュ後に、書き込み対象の複数のデータブロックが、全て書き込まれる、もしくは、全て書き込まれない、という2通りのみの状態に制限することです。
上のような不整合の問題が起きるのは、書き込み対象の複数のデータブロック(上の例の場合では、B木の追加変更ノード・リーフ)の一部だけがディスクへ保存されることによって起こります。
例えば、クラッシュによって、書き込み対象の複数のデータブロック全てが一切ディスクに書き込まれなかった場合は、最新の書き込もうとしていたデータ自体は消えてしまいますが、メタデータとしての不整合は発生しません。上のB木の例であれば、24KB~28KB に追記したデータ自体の保存は失敗していますが、B木の整合性は壊れていないので、最初からあった 0 ~ 24 KB のデータの位置に関する情報を失うことはありません。
このように、fsync が完了するまでは、write システムコールで書き込んだデータが消えてしまう可能性は、ジャーナリング等の機能を持ってしても拭いきれないものであるということにご留意ください。
ジャーナリング等の仕組みは、複数のデータブロックの書き込みが全て成功するか、失敗するかの2パターンに絞ることで、メタデータの破損を防ぎ、すでに保存されたはずのデータが、システムのクラッシュによってアクセスできなくなる、ということを回避することを目的としています。
ジャーナリングの実装
ジャーナリングの基本的なアイデアは、2回同じデータをディスクへ書き込むことです。なぜ2回データを書き込むことで不整合が回避できるのかについて書いていきます。
ジャーナリングを採用したファイルシステムは、ディスク上にジャーナル領域という、専用の領域を用意します。
ジャーナリングファイルシステムは、メタデータ(例えば、B木のノードやリーフ)のような、複数のデータブロックに分かれていて、かつ、一度にディスクに書き込みたいデータをディスクに書き出す際には、最初にそれらを全て一度、ジャーナル領域に書き込みます。図にすると以下のようになります。(下図の例では、ジャーナル領域はブロック番号 30 周辺です。)
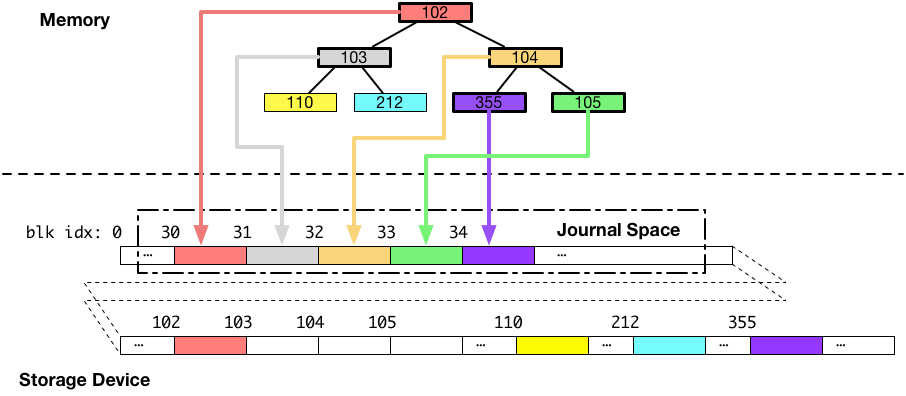
次に、ジャーナル領域へのデータの書き込みが完了した後に、同じデータを本来書き込みたいと思っていた場所に書き込みます。図にすると以下のようになります。
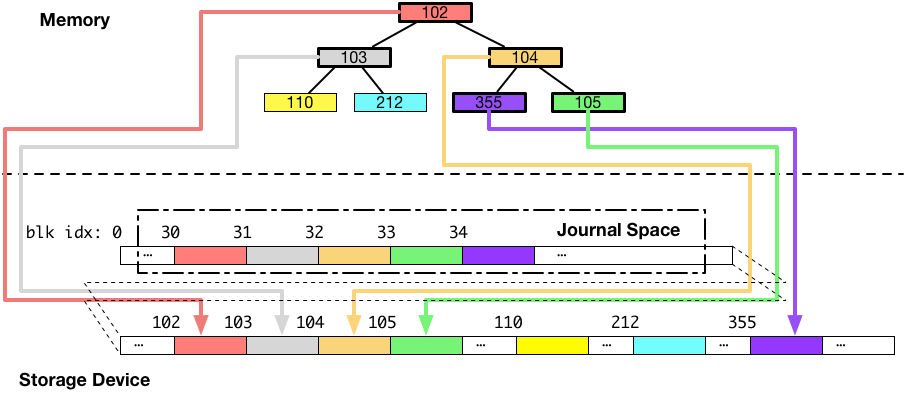
以上がジャーナリングを採用したシステムのデータの書き込みの流れです。次に、書き込み途中でシステムがクラッシュして、書き込みが中断された場合について考えます。
クラッシュからの回復
パターン1
まず、一つ目のパターンとして、ジャーナル領域への書き込み途中にクラッシュが発生して、ブロック 103 番(灰色のブロック)へ書き込まれるはずだったデータが書き込まれなかったとします。以下の図は、そのような場合、データがどのような状態になるかを示しています。
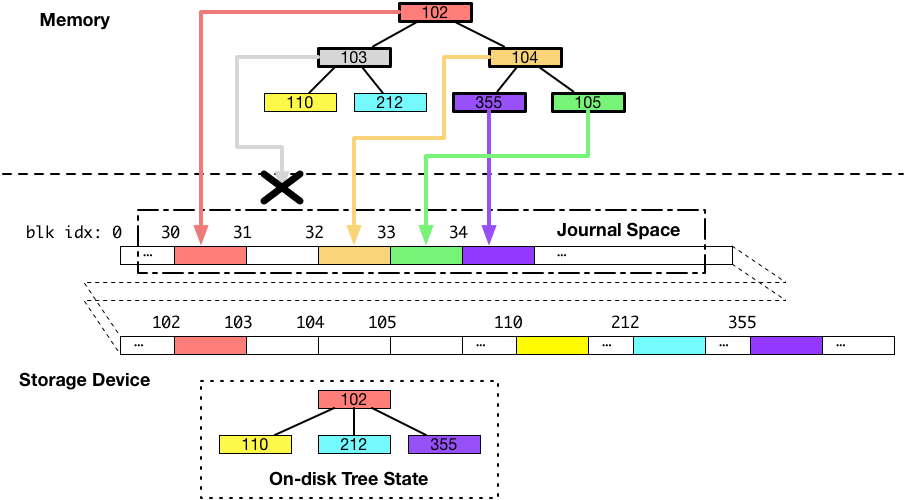
上の図では、B木本体のデータを保存しているディスク上のブロックに対して一切の書き込みがされていないことがポイントです。この場合が、複数のブロックをディスクへ書き込もうとしていたけれど、全ての書き込みに失敗した、パターンになります。
ご覧の通り、B木は古い状態のままで、整合性が保たれています。
この場合、クラッシュ後にファイルシステムはジャーナル領域のデータを破棄するだけで、通常通り動き始めることができます。
パターン2
次のパターンは、ジャーナル領域への書き込み完了後に、実際に書き込みたいと思っていた書き込み先にデータを書き込もうとしている時にクラッシュが発生した場合です。同じく 103 番に書こうとしていたデータが書かれなかった場合について考えます。以下の図が、その場合の状態を示しています。
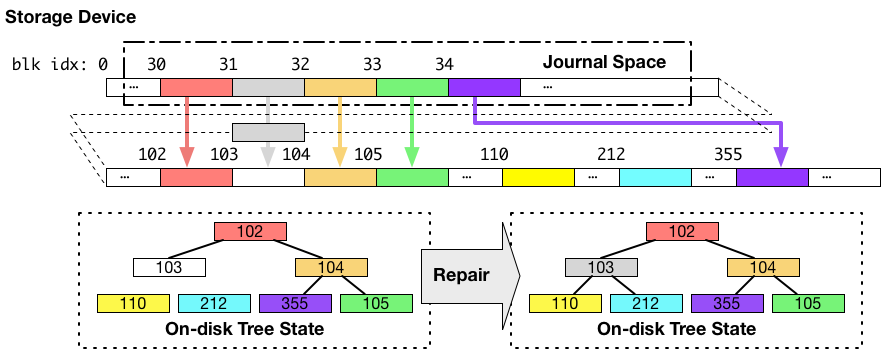
再起動の直後のB木の状態は、上図左下のようになっており、不整合な形になっています。この段階では、データブロック番号 110、103、212 にあるはずのデータへのアクセスが失われています。
ですが、この時に、全ての書き込まれるべきデータはジャーナル領域に保存されています。
なので、システムの再起動後、ファイルシステムはジャーナル領域から、本来データを書き込みたかった場所へコピーすることで、書き込み対象だった全てのデータブロックを目的の宛先に書き込んだ状態にします。この場合は、書き込み対象のデータブロックの書き込みが全て成功したパターンになります。
この再起動後のジャーナル領域からのデータコピーの結果、上図の右下のように、整合性のとれたB木がディスクに現れます。
省略箇所
省略した点として、実装によりますが、書き込みを始める際には、デスクリプタブロックと呼ばれるブロックを先頭として、続けて書き込み対象データブロックを書き込んだのち、コミットブロックと呼ばれるジャーナル領域への書き込み完了を示すブロックを最後に追記するようになっています。このコミットブロックによって、ジャーナル領域の完全性を判断し、不完全であれば、クラッシュ後はジャーナル領域のデータを破棄、そうでなければジャーナル領域のデータを、本来書き込みたかった先へコピーします。ジャーナル領域から、本来コピーされるべきだったディスクの位置については、先頭におかれるデスクリプタブロックに書かれます。
ジャーナリングにおける書き込み順番保証の必要性
かなり長くなってしまいましたが、なぜジャーナリングに永続ストレージデバイスのフラッシュコマンドが必要か書いていきます。
だいぶ上の方に書いてある「ストレージデバイスにおける永続性の保証」というところを思い出していただきたいのですが、ディスクには、データを送りつけただけでは、データはキャッシュに乗るだけでいつ永続的になるかわからない、かつ、キャッシュに置かれたデータがどの順番で永続領域へ移動されるかも不確定です。
今回の記事のポイントは、上記のジャーナリングの仕組みを適切に実装するためには、キャッシュ上のデータが永続領域へ移動される順番を制御する必要があるという点にあります。
書き込みの順番が制御されない状態で、ジャーナリングを実行し、クラッシュが発生した場合どのような状態になる可能性があるかについて、以下のような例を考えます。
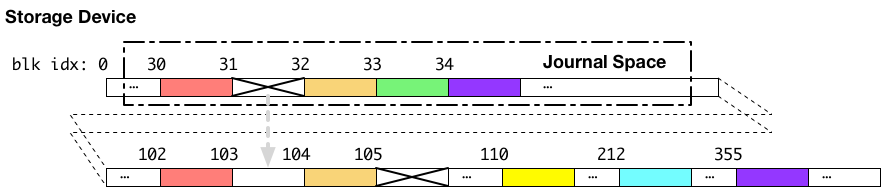
上記の例では、ジャーナル領域への書き込みが完了し、書き込み順序の制御を行わないまま、続けて本来書き込みたかった場所へ書き込んでいる最中にクラッシュが発生した場合の例です。この例では、ジャーナル領域のデータと、本来書き込みたかった書き込み先へ向けたデータの両方が、ストレージデバイス内部のキャッシュに乗った状態でクラッシュを経験しています。結果として、ジャーナル領域のブロック番号 31 に置かれるべきだった、ブロック番号 103 へ書かれるべきデータと、ブロック番号 103 に書かれようとしていたデータの2つの書き込みに失敗したとします。
この場合には、見て明らかな通り、ジャーナル領域のブロック番号 31 から、ブロック番号 103 番へデータをコピーしてもB木は復元できません。ジャーナル領域のブロック番号 31 への書き込みが失敗しているからです。
なぜこのようなことになるかというと、ジャーナル領域のデータが永続領域へ移動される前に、本来のデータ部への書き込みを開始してしまったからです。なので、本来の書き込みたかった場所へデータ書き込むのは、必ず、対応するジャーナル領域のデータが、ストレージデバイスのキャッシュから、永続領域へ移動された後である必要があります。
つまり、ジャーナル領域のデータと、本来書き込みたいデータについて、ストレージデバイスの永続領域へ書き込まれる順番の制御が必要になります。
ジャーナリングファイルシステムは、この書き込み順の制御のために、先述のフラッシュコマンドを利用します。
具体的には、ジャーナル領域へのデータ書き込みの後に、フラッシュコマンドをディスクに対して発行し、フラッシュの完了通知を受け取った後、本来のデータ領域への書き込みを行います。このフラッシュは、書き込みバリアとも呼ばれます。またさらに、ファイルシステムは、そのデータの書き込みの後にもう一度永続性の担保のためにディスクのキャッシュのフラッシュを行います。
このように、ストレージデバイスのキャッシュのフラッシュにはただでさえ時間がかかるにもかかわらず、1度の fsync に対して複数回実行されなければならない、という点が fsync に時間がかかる理由でした。
fsync を高速化する研究
ファイルシステムの研究コミュニティでは、ストレージデバイスのキャッシュのフラッシュに起因する遅延をなんとかして fsync を速くしようとする仕組みが提案されています。今回の記事が論文を読む時の理解の助けになれば嬉しいです。
- Barrier-Enabled IO Stack for Flash Storage FAST'18
- Optimistic crash consistency, SOSP'13
- Consistency Without Ordering, FAST'12
ext4 の fsync がどのようになっているかは、"Barrier-Enabled IO Stack for Flash Storage" の論文の 2.3 Analysis: fsync() in EXT4 の章を読むとわかるかもしれません。
その他参考資料
- Explicit volatile write back cache control Linux のストレージデバイスのキャッシュのフラッシュについての資料。
- Ext4 Filesystem 3. Options の barrier のマウントオプションの箇所には、書き込みバリア(フラッシュ)を有効、無効にする設定と、その効果が書いてあります。
- 詳解 Linuxカーネルには ext3 のジャーナリングに関する記述があります。
- ジャーナリングファイルシステムの構造を利用した非同期リモートミラーリングの高速化, 情報処理学会論文誌コンピューティングシステム 2005 年:fsync の速度に重点をおいた研究ではありませんが、ジャーナリングの実装に関して日本語の解説があります。
追記
まとめ
fsync になぜ比較的長い時間がかかるのか?