memcached プロトコルに則ったリクエストを通して基本的なキー・バリューペアの保存と取り出しができるサーバーを自作しています。
ソースコードはこちらで公開しておりますので、よろしければお試しください。
通信部分には、以前から自作している TCP/IP スタックを利用できるようにしています。また、自作 TCP/IP スタックではなく、Linux 等のカーネルの TCP/IP スタックを利用するバージョンもあります。
実装の内容
memcached サーバーがクライアントからのリクエストに応答する際のおおよその挙動は以下の通りです。
- リクエストメッセージの受信:クライアントから memcached プロトコルに則ったフォーマットで送信されてきたリクエスト内容を含むメッセージを受信する。
- メッセージのパース:クライアントから送られてきたメッセージをパースして、リクエスト内容を判別する。
- キー・バリュー操作:判別されたリクエスト内容に応じてキー・バリューペアの保存や検索を行う。
- レスポンスメッセージの送信:キー・バリュー操作の結果を memcached プロトコルに則ったフォーマットにして、クライアントへ送信する。
これらは主に「メッセージの送受信」「memcached プロトコルに則ったメッセージのパースと応答の生成」「キー・バリュー操作」の三つの要素に分けられます。
自作 memcached 互換サーバーを作成するためには、自作 TCP/IP スタックが担当する「メッセージの送受信」以外の「memcached プロトコルに則ったメッセージのパースと応答の生成」「キー・バリュー操作」の機能が不足しているため、これらを実装します。
実装で配慮した点
実装の再利用性
以前から手軽に memcached プロトコルに則った挙動ができるサーバーを簡単に実装できたらいいなと思うことが何度かあったため、特に memcached プロトコルのパーサーと応答生成部分がなるべく再利用しやすいように配慮しました。
主な配慮の一つは、CPU、OS、固有のライブラリやコンパイラ機能等に極力依存しないようにすることです。また、なるべく多くのコンパイラでコンパイルが可能なように C89 と C++98 という C 言語の標準に準拠させます。
もう一点は、再利用性の高い memcached プロトコルパーサーとキー・バリュー操作の間のインターフェースを定義することですが、こちらはインターフェースが複雑にならず、かつ様々なキー・バリュー操作の実装に対応できるようにすることが中々難しく、特に、当初はキー・バリュー操作機能が memcached 固有のキー・バリューペアのフラグや有効期限についての情報を持つ必要がないようにしたかったのですが、ロックを取らない楽観的な排他制御を適用したい場合に、どのタイミングでバージョンを判断する変数を読み取るか、どのタイミングで読み取ったバージョンと最新のバージョンの値を比較するか、それらが異なった場合にどこからリトライするのか、というような点について、キーバリュー操作の実装に依存しない一般的なプロトコルパーサー側からのキー・バリュー操作に関連した機能の呼び出しタイミングとループの操作を見出すことが難しく、結局は、キー・バリュー操作側にも memcached 固有の情報を持たせることにしました。
この妥協のおかげで、ある程度色々なキー・バリュー操作機能の実装と組み合わせることができるようになっていると思います。
一方で、この妥協の欠点は、仮に新しくハッシュテーブルを開発した人がこのプロトコルパーサー実装を使って memcached 互換サーバーを実装しようとすると、その人は統合作業の中で memcached 固有の情報を操作する実装をする必要があるということです。特に、ms (meta set) や mg (meta get) のようなメタプロトコルのコマンドは挙動が若干複雑なので、統合作業に際してこれらの挙動を認識する必要があるというのは面倒な点です。
応答の挙動をなるべく公式の memcached 実装に近づける
プロトコルパーサーは memcached のテキストプロトコル、メタプロトコル、バイナリプロトコルに対応する、また、なるべく公式の実装と同じエラーメッセージが返されるようにするようにします。
このために、エラーを含むリクエストを公式の memcached と自作 memcached 互換サーバーの両方に送って、同じ結果が返されるかを確認するテストプログラムを用意しました。
利用する CPU コアの増加とともに性能が向上するようにする
利用する CPU コアの増加にあわせて性能を向上できるように、キー・バリューペアを保持するハッシュテーブルへのアクセスの排他制御方法を工夫します。
具体的には、あるスレッドがロックを獲得した後で、そのロックが解放される前に、別のスレッドが同じロックを獲得しようとすると、そのスレッドはロックが解放されるまで待機する必要があり、この待機時間の蓄積が単位時間あたりに処理可能なリクエスト数の低下につながります。
このため、ハッシュテーブル実装において、キー・バリューペアの追加また更新は CPU の compare and swap 機能を元に実装し、読み書き共にロックの獲得が不要になるようにしました。
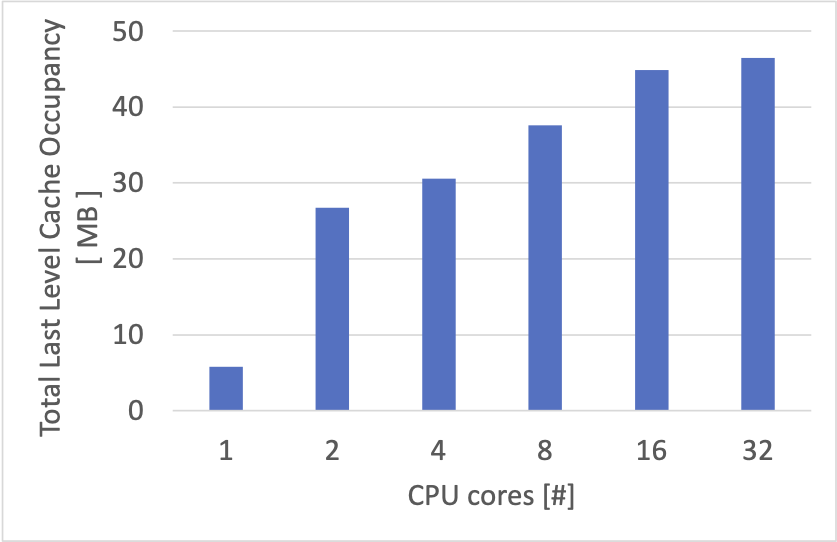
また、キャッシュの追い出しポリシーも CPU 間の同期が少なくて済むように配慮します。Least Recently Used (LRU) のようなポリシーの実装は CPU コア間での同期が多くなりやすいため採用を見送りました。少し調べてみて、ランダムな追い出しはキャッシュヒット率の観点からは最適ではないものの、必ずしも悪いアルゴリズムではないようだったので、こちらを採用しました。
簡単な性能計測
自作した memcached 互換サーバーの性能を簡単に計測してみます。
実験環境
二台の同じ以下の設定のマシンを利用します。
memcached 用ワークロード
自作 TCP/IP スタックを利用する memcached サーバー向けクライアントを使用して以下のワークロードを実行します。
- キー・バリューペア総数:1000 件
- キーのサイズ:8バイト
- バリューのサイズ:8バイト
- リクエストの分布:一様にランダム
- set と get の割合:get 100%(1000 件のキー・バリューペアは計測開始時にサーバー側に全てロードされている)
- プロトコル:テキストプロトコル
キー・バリュー操作の負荷が特に小さい場合の性能を見るためにキー・バリューペアの総数を 1000 件という少ない件数に設定しています。
サーバーは自作 TCP/IP スタックを利用する自作 memcached 互換サーバーと、Linux カーネルの TCP/IP スタックを利用する公式の memcached バージョン 1.6.39 の2通りです。
TCP メッセージ往復ワークロード
また、memcached の応答についての処理のうち「memcached プロトコルに則ったメッセージのパースと応答の生成」「キー・バリュー操作」を含まない「メッセージの送受信」だけの場合の性能の目安を得るために、サーバーとクライアント間で 16 バイトのメッセージを往復させた場合のスループットも計測します。
この場合のベンチマークプログラムはサーバーとクライアント共にこちらの実装を利用します。また、Linux カーネルの TCP/IP スタックを利用する場合のサーバーはこのリンクの please click here to show the code of the program タブを開いた先のものを利用します。クライアントは常に自作 TCP/IP スタックを利用します。
計測結果
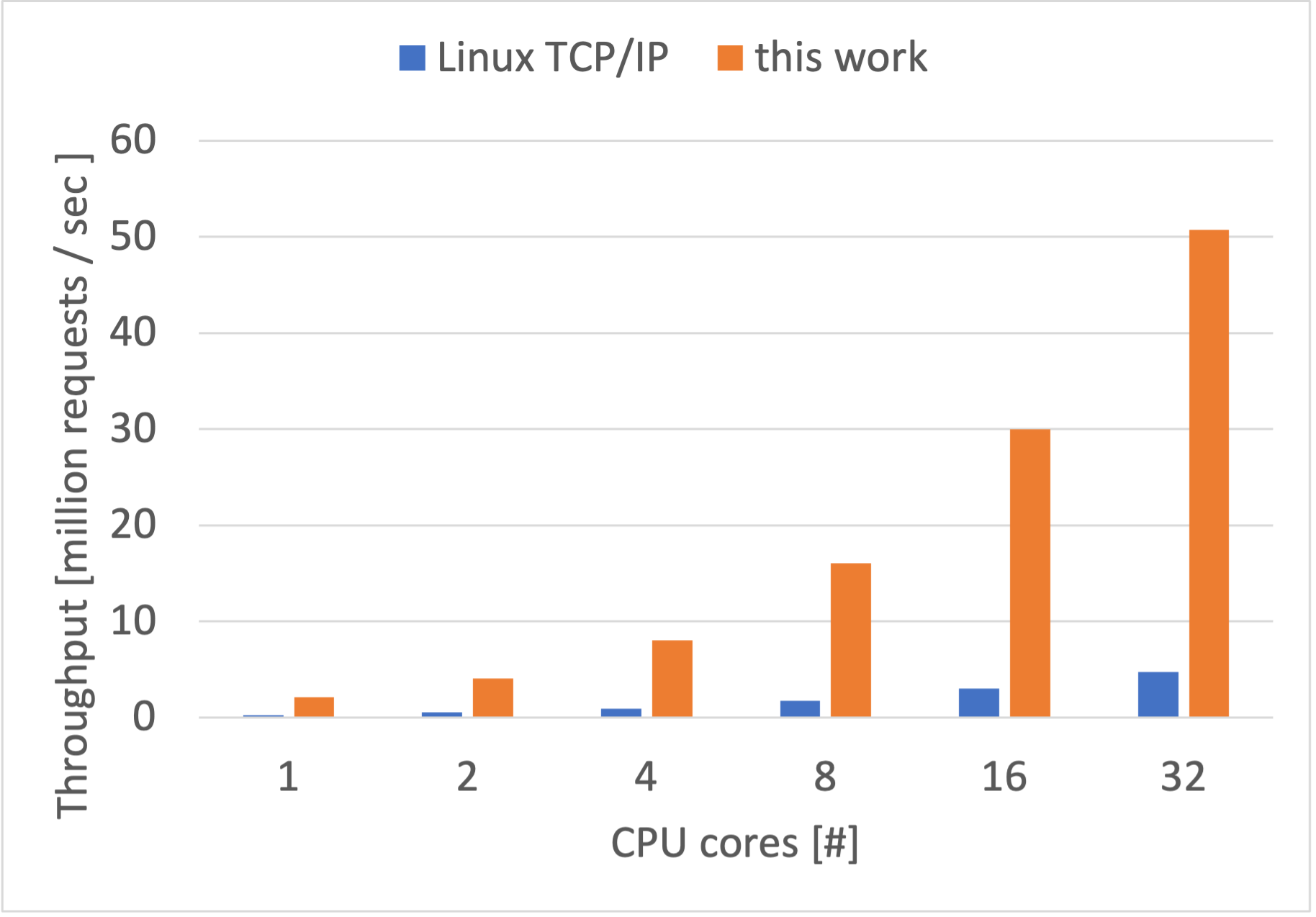
以下のテーブルに1秒間に往復できたメッセージの数を記載しています。注意点として、Linux カーネルの TCP/IP スタックと自作 TCP/IP スタックの性能、公式の memcached サーバーと自作 memcached 互換サーバーの性能を比較することは公平ではないため、目安としてご覧ください。
| CPU コア数 | TCP メッセージ往復(Linux カーネルの TCP/IP スタック) | 公式 memcached(Linux カーネルの TCP/IP スタック) | TCP メッセージ往復(自作 TCP/IP スタック) | 自作 memcached (自作 TCP/IP スタック) |
| 1 | 251,998 | 221,158 | 2,942,829 | 1,796,002 |
| 2 | 518,701 | 416,550 | 5,443,978 | 3,108,503 |
| 4 | 953,781 | 775,122 | 10,548,274 | 6,115,211 |
| 8 | 1,736,528 | 1,532,406 | 22,491,567 | 12,247,723 |
| 16 | 3,320,573 | 2,856,584 | 42,728,778 | 23,766,128 |
| 32 | 5,009,303 | 4,515,630 | 69,237,228 | 31,957,330 |
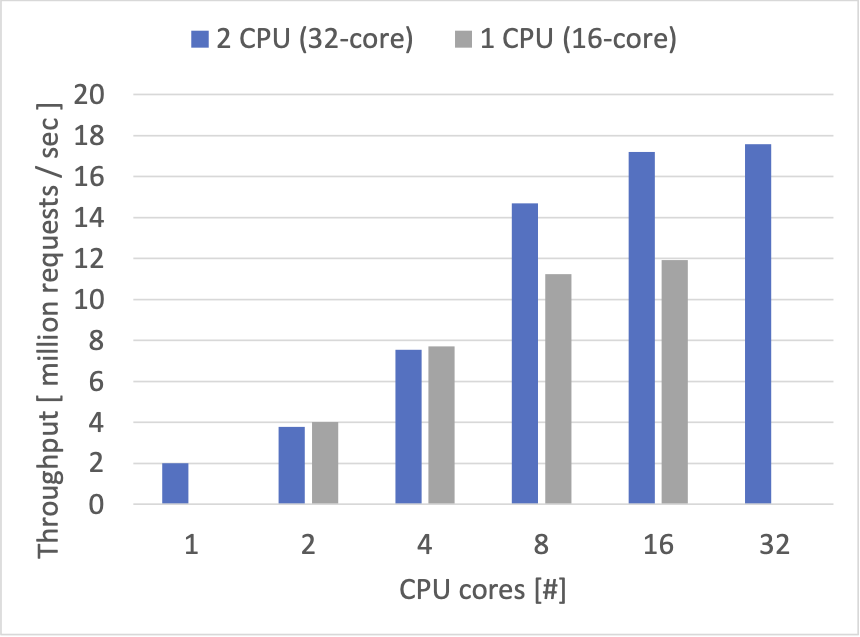
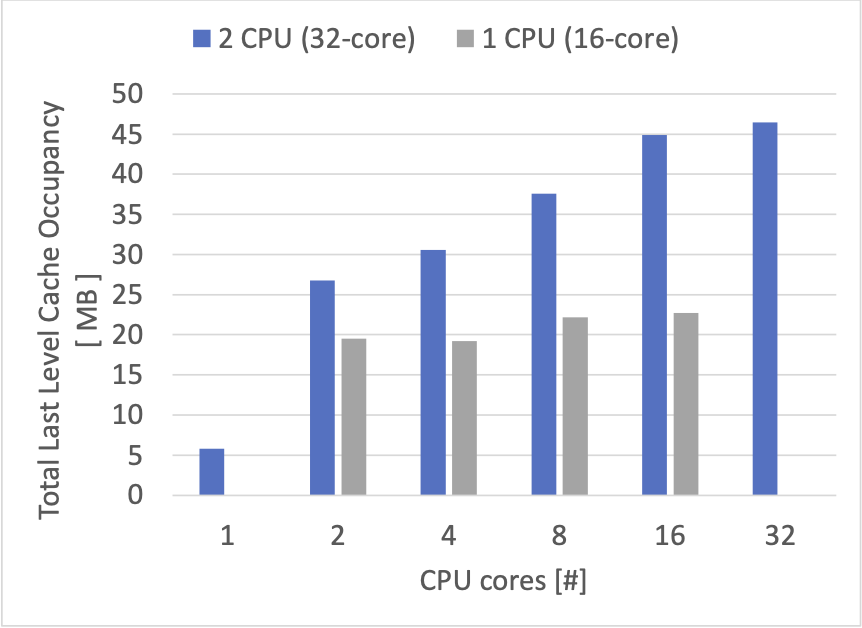
自作の memcached 互換サーバーの性能は自作 TCP/IP スタック実装の性能を反映したものになっているように見えます。また、ある程度 CPU コアの増加にあわせて性能が上がる様子を見ることができました。
他のワークロード
今度はキー・バリューペア数を増やして、リクエストの分布も zipf 分布の近似に変更、また、リクエスト全体のうち 10% は set で上書きをするようにしてみました。
- キー・バリューペア総数:1,000,000 件
- キーのサイズ:8バイト
- バリューのサイズ:8バイト
- リクエストの分布:zipf 分布の近似
- set と get の割合:set 10% get 90%(1000000 件のキー・バリューペアは計測開始時にサーバー側に全てロードされている)
- プロトコル:テキストプロトコル
1秒間にサーバーとクライアントの間で往復できたメッセージ数は以下の通りです。
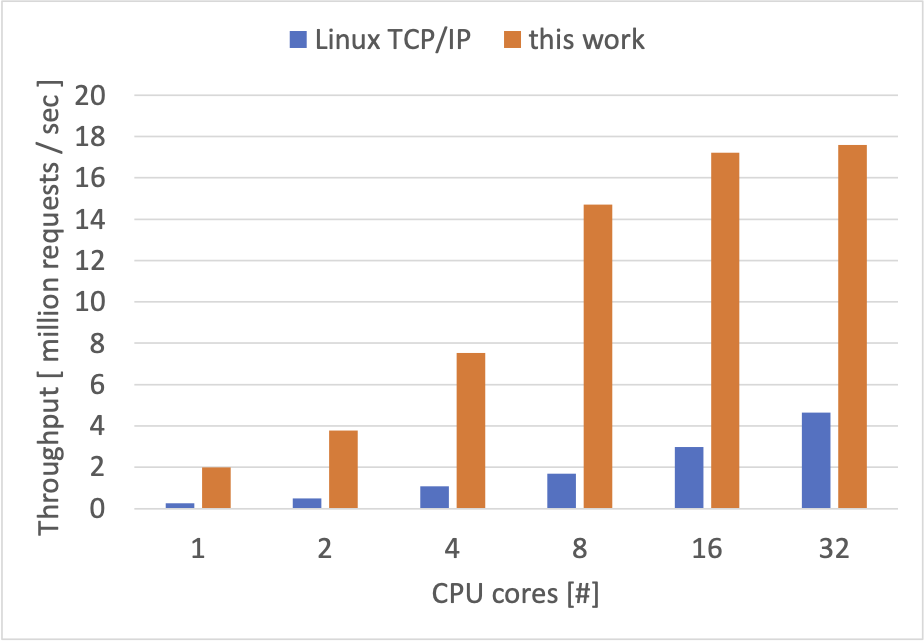
| CPU コア数 | 公式 memcached(Linux カーネルの TCP/IP スタック) | 自作 memcached (自作 TCP/IP スタック) |
| 1 | 202,487 | 1,201,418 |
| 2 | 392,694 | 2,041,757 |
| 4 | 718,106 | 3,915,976 |
| 8 | 1,378,252 | 7,650,862 |
| 16 | 2,344,839 | 14,625,274 |
| 32 | 3,192,569 | 23,194,445 |
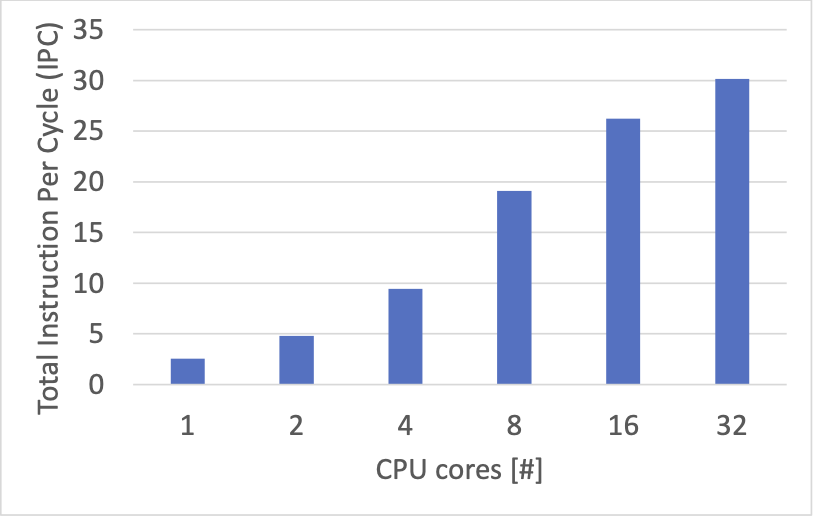
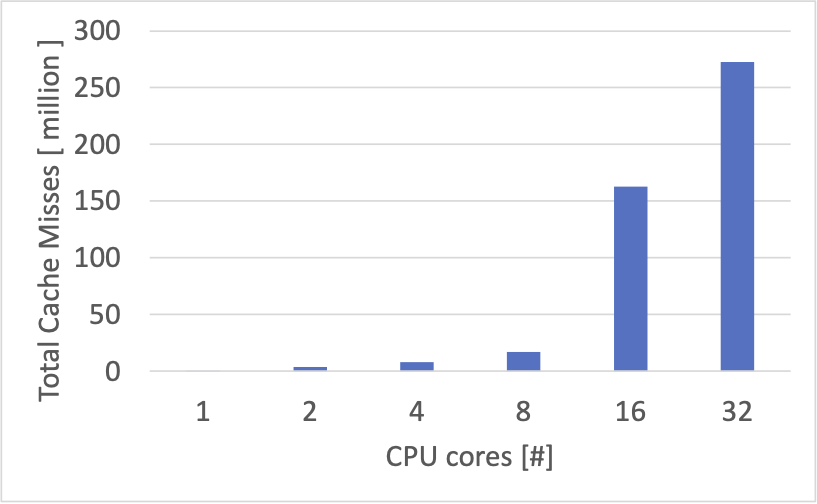
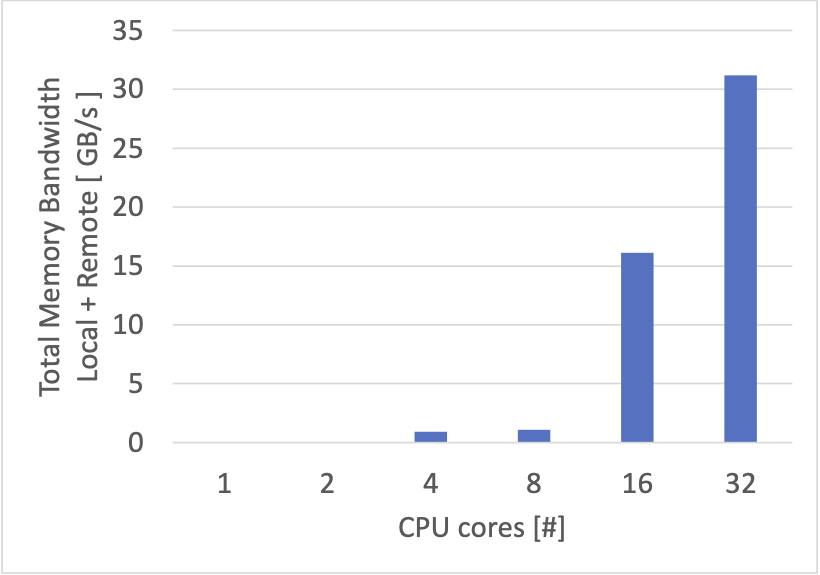
先ほどの計測結果と比べて、数値の低下が見られます。これは、キー・バリューペアの総数が増えてアクセスが発生し得るメモリ領域の範囲が拡大したことによる CPU キャッシュ効率の低下と、一部 set を行うことによる負荷の増加が要因と予想しています。