ptrace より 100 倍速いシステムコールフック作った
新しい高性能で汎用的なシステムコールフックの仕組みを作ってみました。
モチベーションとして、システムコールをフックしてユーザー空間でエミュレートしたくなったのですが、現状、性能と汎用性を両立する仕組みがなさそうだったので、新しい方法を考えました。
今回のシステムコールフックの仕組みは以下のような特徴があります。
- ptrace より 100 倍以上高速
- LD_PRELOAD や既存のバイナリ書き換えツールより確実
- カーネルへの変更なし、かつカーネルモジュールを使わない
- プログラムのソースコード、プログラムの再コンパイル不要
eBPF でトレーシングをしているけれど、できれば制約が少ないユーザー空間でトレーシングツールを作りたい。もしくは、gVisor のようなサンドボックスを作りたいけれど、ptrace による性能劣化が大きいので、他の高速なシステムコールフックの仕組みが使いたい、というような場合に利用できると思います。
今回は、Linux と x86-64 アーキテクチャを想定して実装してみました。
ソースコードは GitHub へ置いてあるので、よかったら試してみてください。
以下に、新しい仕組みの詳細を書いていきます。
上記の方法の問題点
ですが、上記の5つの方法は、性能もしくは汎用性についての問題が見受けられました。
- 既存のカーネル機能:ptrace、SUD はオーバーヘッドが大きい(性能)
- カーネルの変更、カーネルモジュール:通常の環境で使えない(汎用性)
- プログラムの再コンパイル:ソースコードが必ずしも手に入らない(汎用性)
- LD_PRELOAD:ライブラリ関数でラップされていないシステムコールはフックできない(汎用性)
- バイナリ書き換えツール:100% の書き換え成功を保証できない(汎用性)
このことから、現状では、性能と汎用性を両立できる、ユーザー空間でシステムコールフックを実装可能な仕組みはなさそうでした。
今回考えたシステムコールフックの仕組み:Zpoline
今回考えた、Zpoline という仕組みは、プログラムのバイナリが実行前にメモリに読み込まれた段階で、バイナリ書き換えを行います。ですので、Zpoline は、バイナリ書き換えにカテゴライズされますが、プログラムのバイナリ"ファイル"自体は上書きしません。
前提知識:x86-64 でのシステムコール
システムコールは、ユーザー空間のプログラムが、カーネル機能へアクセスするためのインターフェースとして利用されます。
実装として、ユーザー空間プログラムは syscall もしくは sysenter という CPU 命令を利用することで、システムコールを発行できます。
ユーザー空間プログラムが syscall/sysenter 命令を実行すると、実行コンテキストがカーネル空間へ切り替わり、カーネルが予め設定したシステムコール ハンドラへ処理が以降します。
解決する問題:バイナリ書き換え固有の問題
Zpoline はバイナリ書き換えによって、システムコールのフックを実装しますが、バイナリ書き換えの仕組みには、100% の書き換え成功を担保することが難しいという問題があります。
具体的な難しさは、ある CPU 命令を、それよりも大きな CPU 命令と置き換える、という点にあります。
まず、syscall と sysenter CPU 命令は、それぞれ、0x0f 0x05 と 0x0f 0x34 という 2 byte のオペコードで表されます。
今回は、それらを任意のユーザー空間にあるシステムコールフック関数へ処理を飛ばすための、jmp もしくは call 命令と置き換えることを目指します。
問題点は、jmp と call 命令は、2 byte だけでは、任意のフック関数へのジャンプを実装することが難しいということにあります。なぜかというと、それらの命令は、ジャンプの宛先のアドレス(今回ならフック関数のアドレス)を指定する必要があり、それには 2 byte 以上が必要になるからです。
プログラムのバイナリの中では、syscall / sysenter 命令以降には、次の命令が書いてあるので、jmp / call 命令がはみ出ると、それらを上書きして、プログラムを壊してしまうことになります。結果として、既存のバイナリ書き換えツールでは、100% の書き換え成功を担保することが難しくなっています。
Zpoline のアイデア
Zpoline のアイデアは、システムコールの呼出規約をうまく使って、それに合わせてバイナリ書き換えを行い、かつ適切にトランポリンコードを用意することです。
以下の図に、外観を示します。
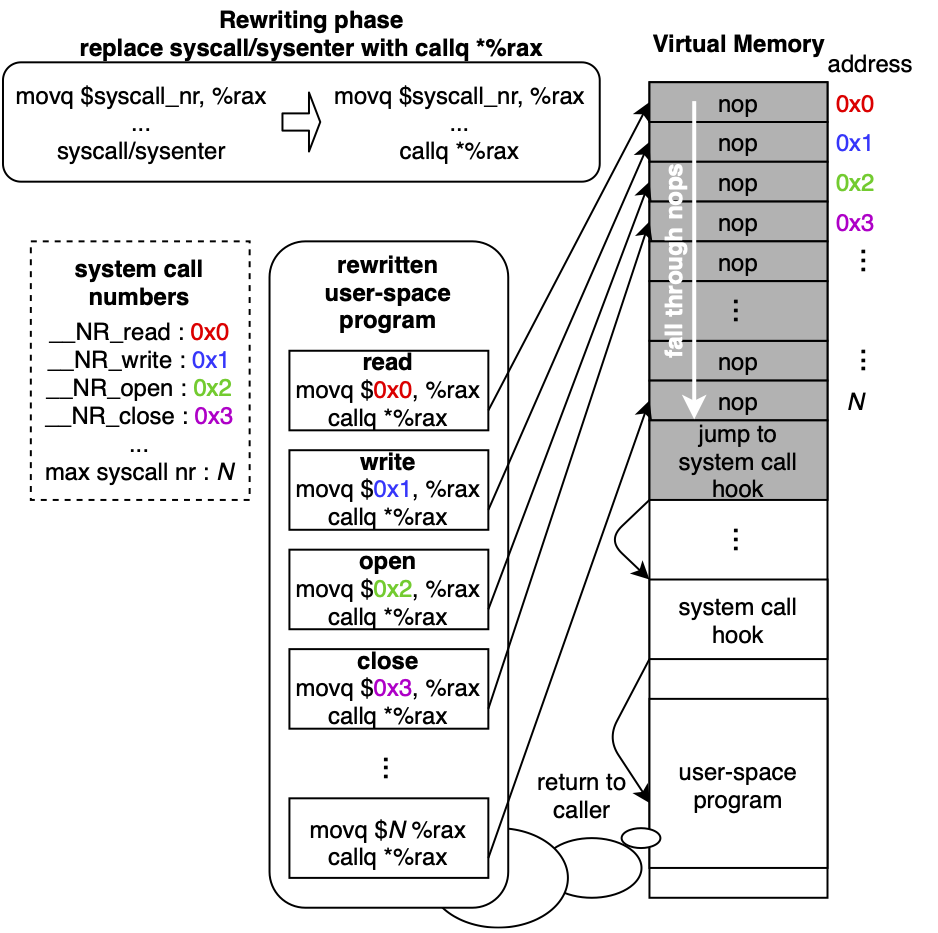
バイナリ書き換え
具体的には、syscall / sysenter 命令を callq *%rax という 0xff 0xd0 で表される 2 byte の命令で書き換えます。ここで、大事なポイントは、callq *%rax は syscall / sysenter 命令と同じ 2 byte なので、他の箇所に影響を与えずに、単純に置き換えることができます。
さて、callq *%rax が何をするのかというと、%rax CPU レジスタへ入った値を宛先アドレスとして、ジャンプします。また、callq は call 系列の命令なので、ジャンプ元のアドレスはスタックへ push します。
ここで、システムコールの呼出規約を使います。前述の通り、Linux の呼出規約では、%rax へは、システムコール番号が入っています。システムコール番号は、カーネルの定義によって、0 から始まり 400~500 程度までに収まる数なので、callq *%rax が飛ぶ宛先アドレスは必ず 0 ~ 500 程度になります。
Zpoline では、そのアドレス 0 ~ 500 の含まれる領域にトランポリンコードを用意し、任意のシステムコールフック関数へのジャンプを実装します。Zpoline の名前は、tramPOLINE code をアドレス 0 ( Zero ) に設定することから来ています。
トランポリンコード
トランポリンコードの用意は、mmap システムコール を使って、メモリをアドレス 0 に確保することから始まります。Linux では、デフォルトでは、アドレス 0 は mmap できないようになっていますが、/proc/sys/vm/mmap_min_addr に 0 を設定すると、通常ユーザーでもアドレス 0 にメモリをマップできるようになります。
次に、アドレス 0 から最大のシステムコール番号までを nop 命令 ( 0x90 ) で埋めます。その後、最後の nop 命令の次に、任意のシステムコールフック関数へジャンプするためのコードを埋め込みます。
その結果、syscall / sysenter を置き換えた callq *%rax は、トランポリンコードの上の nop 命令のどれかへのジャンプになります。nop 命令に飛んだ後は、システムコール フックへのジャンプのコードへ行き着くまで、続く nop 命令を実行します。
これにより、任意のフック関数へのジャンプが実装できました。
また、callq *%rax の呼び出し元のアドレスは、callq 命令のおかげでスタックに保存されているので、フック関数の return は callq *%rax の呼び出し元への return になります。
実装
Zpoline で LD_PRELOAD でロードされることを想定したライブラリとして実装されており、プログラムの main 関数が実行され始める前に、トランポリンコードとバイナリ書き換えを行います。これにより、Zpoline はどんなプログラムに対してもシステムコールフックを適用できます。LD_PREALOD を使っていますが、既存の仕組みのように、ライブラリ関数の書き換えは行いません。
独自のシステムコールフックは、LD_PRELOAD でロードされるライブラリの中に実装することができます。
1点、既存のバイナリ書き換えの仕組みや、Syscall User Dispatch と同様に、フックを適用する対象のプログラムが呼び出す可能性のある関数を、フックから呼び出す場合には注意が必要です。例えば、function_A という関数があり、内部の実装が、ロックを確保し、あるシステムコールを実行、その後、ロックを開放する、とします。仮に、フック適用対象のプログラムが function_A を呼び出すと、その中のシステムコールは、Zpoline によってフックされます。問題は、フックが function_A を呼び出すと、デッドロックが発生します。なぜなら、最初に呼び出された function_A の中で、ロックがリリースされていないからです。
このような問題については、フック関数が利用するリソースを、フック適用対象のプログラムと分けることで、回避できます。今後、フック関数の実装に役に立ちそうな実装を追加する予定でいます。
性能
簡単に、Zpoline を利用して作ったシステムコールフックの仕組みを ptrace と Syscall User Dispatch と比較してみました。
とても単純な、プロセスの pid を取得する getpid をトラップして、代わりにシステムコールを実行するために必要な CPU サイクルを計測しました。さらに、pid をキャッシュして、実際には getpid システムコールを実行しないで、キャッシュした値を返すエミュレーションも実装して、同様に CPU サイクルを計測しました。計測には、Intel Xeon E5-2640 v3 CPU 2.60 GHz と Linux-5.11 ( Ubuntu 20.04 ) を利用しました。
以下が計測結果です。
| Hook Mechanism | without pid cache | with pid cache |
|---|---|---|
| ptrace | 17820 | 16403 |
| Syscall User Dispatch | 5957 | 4563 |
| Zpoline | 1459 | 138 |
Zpoline は ptrace と Syscall User Dispatch よりも遥かに少ない CPU サイクルでシステムコールをフックできることがわかりました。
特に、システムコールフック自体のオーバーヘッドは、getpid システムコールのオーバーヘッドが含まれない with pid cache のケースに見ることができます。今回の環境では、Zpoline は ptrace より 118 倍高速であるという結果になりました。