仮想 I/O 高速化手法まとめ
仮想 I/O の高速化手法についてまとめました。特にネットワーク I/O の高速化について調べました。
デバイスの仮想化
仮想マシンが利用するネットワークカードは多くの場合、QEMU のようなエミュレータによってエミュレーションされており、物理的なネットワークカードとのやりとりはホスト上で動作する仮想スイッチを介して行われます。*1以下に構成を図示します。
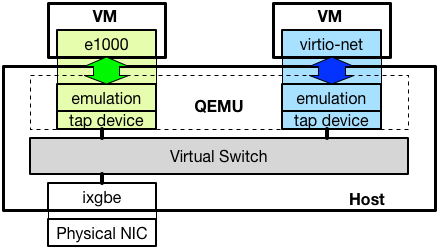
エミュレートされるデバイスは Intel の 1Gbps NIC 等、実際に存在するネットワークカードと、virtio-net のような、物理的なハードウェアが存在しないインターフェースがあります。
仮想化技術は大きく「完全仮想化」と「準仮想化」に分類されます。*2
完全仮想化によってゲストへ提供される環境は、ゲストからは、現実に存在する物理ハードウェアと全く同じように見えるようエミュレートされます。結果として、ゲスト OS は、仮想化された環境で動作していることを考慮することなく、物理ハードウェア上で動作するのと同じプログラムを実行できます。
具体的には、広く利用されている、Intel の NIC のような物理デバイスを仮想デバイスとしてエミュレートしてゲストへ提供した場合、ゲストは、多くの OS が標準的に実装している Intel NIC のデバイスドライバを、そのまま仮想ネットワークインターフェースのためのデバイスドライバとして利用できます。
これに対し、準仮想化環境では、ゲストが準仮想化環境へ対応するためのプログラムを実装している必要があり、既存のプログラムだけでは利用できないことがあります。例えば、virtio-net のような仮想デバイスは、専用のデバイスドライバが必要になります。
性能の観点では、準仮想化デバイスは、完全仮想化デバイスに比べ、エミュレーションコストを低く抑える工夫を取り入れやすいことから、性能を向上しやすいと言われています。一方で、完全仮想化デバイスは、ゲスト OS が既に実装しているデバイスドライバを利用することができるため、可搬性が高いと言われています。
仮想 I/O 実行方式
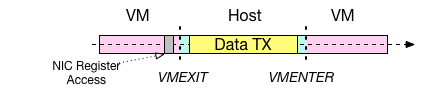
仮想デバイスの I/O は、VMEXIT のハンドラで実行される方式と、I/O スレッドによって実行される方式が考えられます。VMEXIT は、Intel VT-x の仮想化支援機構を用いて実装される仮想化環境で、実行コンテキストが仮想マシンからホストへ切り替わるときに発生します。仮想マシンが、ホスト側のエミュレーションが必要な命令を実行したり、外部からの割り込みをハンドルする際に発生するそうです。*3
前者の挙動を以下の図に示します。この方式は、Intel 1Gbps NIC ( e1000 ) 等の完全仮想化デバイスに多く採用されています。I/O のエミュレーションが、VMEXIT が発生した CPU で実行され、その間、仮想マシン自体の処理が中断されているという特徴があります。
もう一方の I/O スレッドによる仮想 I/O の図を以下に示します。こちらは、Xen の netfront/netback や、QEMU/KVM の virtio/vhost-net 等の準仮想化デバイスで多く採用されている方式です。最新の高速化手法も、この実行形式に則っているものが多いです。
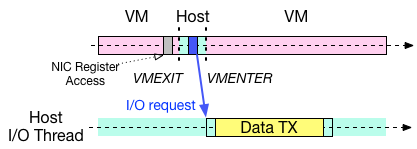
この方式においても基本的に、仮想マシンは、I/O をリクエストするために VMEXIT を発生させる必要がありますが、リクエストの完了後には、I/O の完了を待たずに仮想マシンのコンテキストへ戻ります。代わりに、リクエストを受けた I/O スレッドが仮想マシンのために I/O を実行します。
この方式では、仮想マシンと、I/O をそれぞれ別のスレッドで並列して実行することができるため、CPU が2つ以上ある場合には、並列化の恩恵により性能の向上が期待できます。具体的に、仮想マシン上で動作する Web サーバーを例にすると、仮想マシンのコンテキスト(図中ピンク色の部分)で、サーバーアプリケーションが HTTP のリクエストをハンドルする処理を行うのと同時に、ホストの I/O スレッドで HTTP レスポンスデータの送信処理(図中黄色の部分)を行うことができます。
一般的に利用されている仮想 I/O 機構
ハードウェア機能による I/O 仮想化 : SR-IOV
Xen の標準仮想ネットワーク機構 netfront/netback の論文 : Reconstructing I/O (University of Cambridge, Technical Report 2004)
QEMU/KVM virtio の論文 : virtio: Towards a De-Facto Standard For Virtual I/O Devices (ACM SIGOPS OSR 2008)
Xen 仮想 I/O 最適化
2005~2010 年には、Xen の仮想 I/O 機構である netfront/netback の性能を改善する論文が発表されています。
Optimizing Network Virtualization in Xen (USENIX ATC’06)
Bridging the Gap between Software and Hardware Techniques for I/O Virtualization (USENIX ATC’08)
Achieving 10 Gb/s using safe and transparent network interface virtualization (VEE’09)
VMEXIT を削減する
ELI: Bare-Metal Performance for I/O Virtualization (ASPLOS’12)
仮想デバイスはデータ送受信の際に、VMEXIT を発生させる必要があり、その VMEXIT による性能劣化が指摘されていました。
ELI の論文では、仮想マシンへの割り込みを、VMEXIT を発生させることなく、直接仮想マシンへ届ける手法 "Exit-Less Interrupt" を提案し、仮想化環境でも非仮想化環境と遜色ない性能を達成できることを示しています。
ELI の論文の詳細は、以下の解説がとても参考になりました。
constellation.github.io
Efficient and Scalable Paravirtual I/O System (USENIX ATC’13)
Efficient and ScaLable para-Virtual I/O System ( Elvis ) は ELI を採用した準仮想化 I/O 機構です。特徴として、仮想 I/O のために占有の CPU を用意して、複数の仮想マシンの I/O の処理をまとめて同じ CPU で行うことが挙げられます。図にすると以下のようになります。
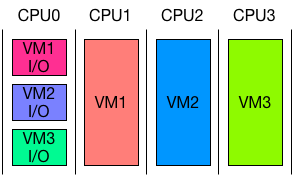
これにより、ホストのコンテキストで実行される仮想 I/O が常に、仮想マシンが動いている CPU と別の CPU で処理されるため、実行中の仮想マシンが、ホストの仮想 I/O の処理によって中断されることを避けることができ、結果として VMEXIT を削減しています。ELI と併用して、1NUMA ノードあたり、1コアを I/O のために割り当てるだけで、十分な性能が達成できるそうです。
Paravirtual Remote I/O (ASPLOS’16)
Paravirtual Remote I/O ( vRIO ) では、仮想 I/O を実行するためのホストを新たに用意し、仮想マシンと SR-IOV 経由でやりとりを行います。
仮想スイッチの最適化
Hyper-Switch: A Scalable Software Virtual Switching Architecture (USENIX ATC’13)
Hyper-Switch はネットワーク I/O がドライバードメイン(ホスト)を経由する必要があることについて、スケーラビリティの観点から問題があると指摘し、解決策として、仮想スイッチを Xen ハイパーバイザーの中へ実装するを提案しています。これにより、ドライバードメインを経由しない I/O を実現することができ、特に仮想マシン間通信の性能が向上できると述べられています。
Speeding Up Packet I/O in Virtual Machines (ANCS’13)
上の論文では、既存の仮想デバイスはそのままに、割り込みエミュレーションの実装部分への最適化と、仮想スイッチを高速なもの置き換えることで性能を向上しています。
NFV プラットフォーム向け仮想 I/O
高速パケット I/O フレームワーク登場以後、仮想マシンとパケット I/O フレームワークを組み合わせた NFV プラットフォームが複数提案されました。これらの特徴として、高速な仮想スイッチを適用することと、そのスイッチに適した仮想デバイスを実装していることが挙げられます。
QEMU/KVM + netmap = ptnetmap
Virtual device passthrough for high speed VM networking (ANCS’15)
Flexible Virtual Machine Networking Using Netmap Passthrough (LANMAN’16)
ptnetmap は、netmap の物理 NIC ポート、もしくは仮想ポートを仮想マシンに接続できるようにする技術です。ゲスト用のptnetmap デバイスドライバが用意されており、これを利用することで、ゲスト上で動作する netmap アプリケーションは、ホスト側で用意された netmap ポートを透過的に利用できます。
チュートリアルのスライドが以下の URL で見つかりました。
QEMU/KVM + DPDK
NetVM: High Performance and Flexible Networking using Virtualization on Commodity Platforms (NSDI’14)
Xen + netmap
ClickOS and the Art of Network Function Virtualization (NSDI’14)
Xen + netmap / QEMU/KVM + netmap
HyperNF: building a high performance, high utilization and fair NFV platform (SoCC’17)
HyperNF の論文では、Network Function アプリケーションを動かす仮想マシンを1つの物理サーバーへ集積する場合にむけた、リソース効率の高い仮想 I/O の実行手法ついて議論しています。特に、I/O スレッドによる仮想 I/O のモデルは、仮想 CPU と、仮想 I/O スレッドに別々に CPU リソースを割り当てる必要があり、それぞれへのリソース配分比率が性能に影響を与えることと、ワークロードごとに最適な比率が異なることを指摘しています。
以下のグラフでは、仮想 CPU と仮想 I/O のために、合計で 100% の CPU が割り当てられた仮想マシンの上で、ファイアーウォールを実行した場合の、仮想 CPU と仮想 I/O への CPU 割り当て比率ごとの性能の変化をプロットしています。
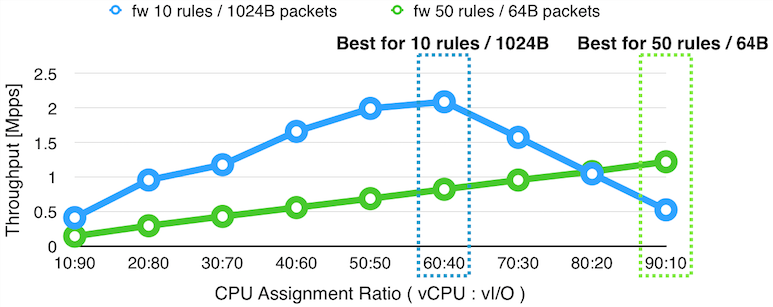
上のグラフの結果によると、50 のフィルタリングルールが入ったファイアーウォールを実行し、64 バイトのパケットをフォワードする場合(緑の線)には、仮想 CPU に9割、仮想 I/O に1割の CPU を割り振ると最大の性能が発揮されますが、10 のフィルタリングルールが入ったファイアーウォールを実行し 1024 バイトのパケットをフォワードする場合(青い線)には、仮想 CPU に6割、仮想 I/O に4割のリソースを割り当てたときに最高の性能が発揮されます。また、片側の場合で最大性能が達成される場合には、もう片方の場合で、最高性能と比較して約半分から4分の1まで性能が低下しています。
論文では、これらのことと、Network Function のコストと、パケットサイズが動的に変化することから、仮想 CPU と仮想 I/O の CPU リソースを固定的に割り当てることは、仮想マシンに割り当てられたリソースを使って最大性能を発揮するために適切ではないと主張しています。
また、仮想 CPU と仮想 I/O を別々の CPU で実行した場合には、ある CPU で実行されるスレッドが、同時に別の CPU のリソースを利用できないことから、CPU リソースが固定的に分割されるのと同じであることも指摘しています。
これらの問題の解決策として、論文では、仮想 I/O をハイパーコール*4のコンテキストで実行することを提案しています。CPU のリソース配置は Elvis と比較して、以下の図のようになります。
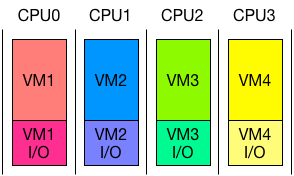
この実行形式では、仮想 CPU と仮想 I/O が常に同じ CPU で実行され、結果として、CPU リソースが仮想 CPU と仮想 I/O へ、常に最適な比率で配分されます。さらに、スケジューラーは、仮想 CPU と仮想 I/O をまとめて一つのスレッドとして扱うことができるため、標準的に実装されている Xen の resource cap/weight のようなリソース配分の仕組みを、より正確に適用することができます。
コンテナ + DPDK
OpenNetVM: A Platform for High Performance Network Service Chains (HotMiddlebox'16)
Flurries: Countless Fine-Grained NFs for Flexible Per-Flow Customization (CoNEXT'16)
これらの NFV 向け仮想 I/O 機構は、仮想マシンだけでなくコンテナに適用する研究も行われています。OpenNetVM と Flurries は NetVM を開発したグループによって発表されました。
参考資料
Reading the Paper, "ELI: Bare-Metal Performance for I/O Virtualization"
ハイパーバイザの作り方~ちゃんと理解する仮想化技術~ 第1回 x86アーキテクチャにおける仮想化の歴史とIntel VT-x
ハイパーバイザの作り方~ちゃんと理解する仮想化技術~ 第11回 virtioによる準仮想化デバイス その1「virtioの概要とVirtio PCI」
*1:物理デバイスを直接仮想マシンへ接続するデバイスパススルーという技術を利用した場合には、物理デバイスは、ホストを介することなく仮想マシンによって制御されます。
*2:https://syuu1228.github.io/howto_implement_hypervisor/part11.html
*3:https://syuu1228.github.io/howto_implement_hypervisor/part1.html
*4:仮想マシンがハイパーバイザーの機能へアクセスする仕組みで、システムコールと同じように、割り込みを起点に仮想マシンからハイパーバイザーへのコンテキスト切り替えが行われます。