OS のメモリ管理の仕組み
OS のメモリ管理の仕組みについて調べたことをまとめました。
読んでいただくと、以下のようなことについて少し詳しくわかるかもしれません。
- あるユーザー空間プロセスが他のユーザー空間プロセスのメモリにアクセスできない理由
- ユーザー空間プロセスがカーネル空間のメモリにアクセスできない理由
- ユーザー空間のプロセスとスレッドの違いはどのように実装できるか
- 共有メモリはどのように実装できるか
- メモリマップトファイルはどのように実装できるか
- malloc は何故必要か
- あるコンテナが別のコンテナのメモリにアクセスできない理由
- コンテナと仮想マシンのメモリ領域の分離についての違い
上記の全ての点について、仮想メモリという一つの機構で概ね説明可能である、というのが今回のポイントです。
また、そもそものユーザー空間プロセスとメモリの関係についても、少しわかるかもしれません。
当記事は、x86-64 CPU で動作する汎用 OS 環境を想定しています。
メモリ
当記事では、Dynamic Random Access Memory (DRAM) についてメモリと呼ぶとします。
メモリは、ハードウェアの仕様上、CPU からアクセス可能な記憶領域で、パソコンには基本的なパーツとして付属しています。
メモリには、各バイト(8-bit)ごとに 0 からメモリの最大容量まで番地(アドレス)が振ってあり、CPU からメモリへのデータの書き出し・読み込みは、アドレスを元に行います。(後述しますが、このアドレスは物理メモリアドレスと呼ばれます。)
CPU からメモリへのアクセスはいつどのように発生するか
まず、プログラムがどのようにメモリを利用しているか、具体的には、メモリへのアクセスがどのように発生するかということについて見ていきます。
前提として、
- CPU はプログラムを実行するハードウェアで、
- CPU はプログラムの実行に際して、メモリ上のデータを読み書きし、そのことをメモリアクセスと当記事では呼んでいます。
今回は例として、以下のような変数 __x と変数 __y を加算した結果を変数 __z に代入するようなプログラムを考えます。
__z = __x + __y
コンピューターで上のプログラムを実行するときの CPU とメモリの状態は以下の図のようになると思われます。
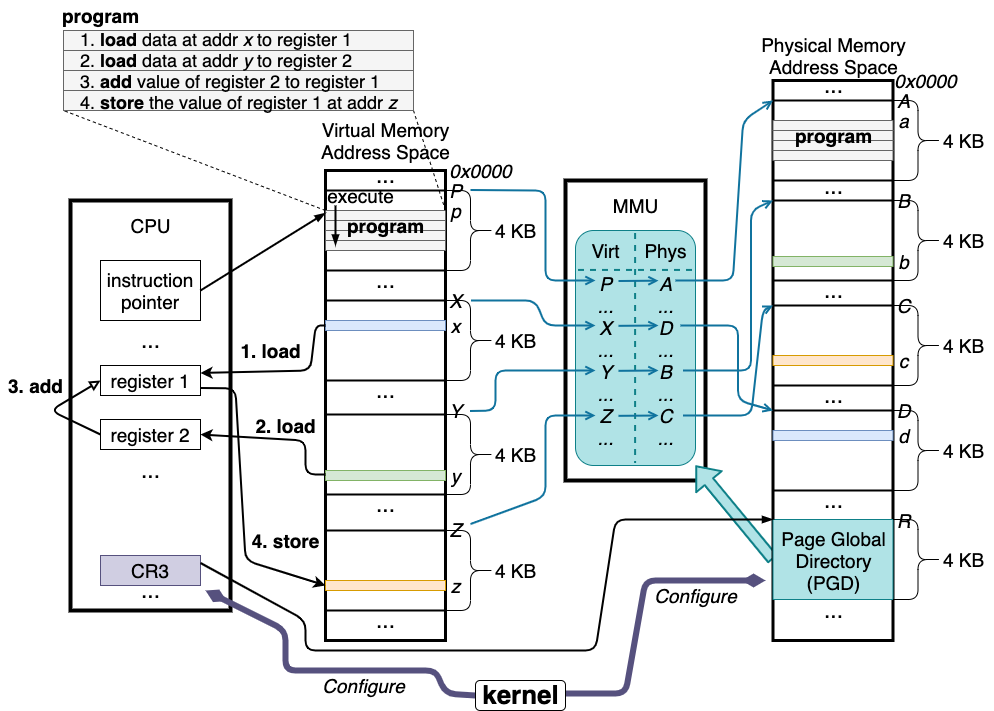
メモリに置かれるデータ
上のプログラムを実行する際には、__x, __y, __z の値と、上のプログラム自体がメモリの上に保存されます。
まず、Virtual Memory Address Space と書いてある箇所に目を向けていただいて、今回の例では、__x はメモリアドレス x、__y はメモリアドレス y、__z はメモリアドレス z、プログラムはメモリアドレス p に保存されるとして見てください。(実際のプログラムでは、__x, __y, __z は比較的近いアドレスに保存されると思いますが、今回は例のため敢えて分散しています。)
CPU 内部のパーツ
次に、図中の CPU 内の要素について見ていただきたいのですが、この図には、
- instruction pointer
- register 1
- register 2
- CR3
が描いてあり、これらはレジスタと呼ばれるパーツで、x86-64 等では、それぞれ 64-bit の値を保持できます。
それぞれの機能についての説明は以下のようになります。
プログラムの挙動
__x + __y = __z を実行するプログラムは、機械語に対応するアセンブリ言語に変換すると、以下のようなになるとします。(コンパイラの出力によっては違う結果になると思われます。)(CPU の仕様上、各命令を実行すると、instruction pointer が自動的にインクリメントされて次の命令が CPU に読み込まれ実行されるようになっています。)
命令 1. メモリアドレス x の値を register 1 へロードする
命令 2. メモリアドレス y の値を register 2 へロードする
命令 3. register 2 の値を register 1 へ加算する
命令 4. register 1 の値をメモリアドレス z へストアする
なぜ単純な足し算がこのような手順を踏む必要があるかというと、それは CPU の仕様によるもので、CPU が実装している加算の命令がレジスタの現在の値を元に加算を行うものしかない場合、このようにわざわざメモリの値をレジスタに読み込んだ後加算する、という操作が必要になります。
上の例におけるメモリアクセスの発生箇所
上のプログラムにおいて、メモリアクセスは、命令 1, 2 のロード(メモリからレジスタへの読み込み)と命令 4 のストア(レジスタからメモリへの書き込み)、さらにはプログラムである命令 1, 2, 3, 4 自体を CPU へ読み込むところで発生しています。
OS・カーネルによる、プログラムのメモリアクセスについての制御の要件
汎用 OS 環境では、プログラムは複数並列で実行されることが一般的ですが、その場合に、複数のプログラムが意図せず同じメモリ領域を利用してしまうことを回避する必要があります。
例えば、上の例のプログラムと一緒に別のプログラムが動作しているとして、例のプログラムは加算結果をメモリアドレス z に保存しますが、その別のプログラムがメモリアドレス z 上に既にデータを保存していたとすると、それは上書きされ、その別プログラムのクラッシュ等につながります。
このようなことを避けるために、汎用 OS・カーネルは、複数のプログラムが意図せず同じメモリ領域へアクセスできないように制御しています。
この制御の根底にある機構が、仮想メモリという仕組みで、今回の記事のポイントです。
仮想メモリ
物理メモリアドレスと仮想メモリアドレス
ここまで特別に区別なくメモリアドレスと記述してきましたが、メモリアドレスには物理メモリアドレスと仮想メモリアドレスがあります。
物理メモリアドレスは、ハードウェアのメモリの中で、各バイト(8-bit)ごとに割り当てられている番地です。
一方、仮想メモリアドレスは、ソフトウェアが制御可能な仮想的なメモリアドレスで、あるプログラムが(仮想)メモリアドレス N にアクセスしているつもりでも、実は物理メモリアドレス M にアクセスさせる、というようなことができます。
x86-64 のような CPU を採用しているコンピューターで通常利用されるプログラムは、仮想メモリアドレスをもとに動作しており、この仮想メモリ機構がカーネルが行うメモリ管理の基本的な仕組みとなっています。
上のプログラムの例にあるメモリアドレス x, y, z, p は、仮想メモリアドレスとなります。
Memory Management Unit (MMU)
「プログラムが(仮想)メモリアドレス N にアクセスしているつもりでも、実は物理メモリアドレス M にアクセスさせる」というようなことができる仮想メモリ機構はどのように実現されるか、ということについて見ていきます。
基本的に、仮想メモリ機構の実現は Memory Management Unit (MMU) というハードウェアの機能に依存しています。
上の図の通り、MMU は CPU とメモリの間に位置し、CPU のメモリアクセスを仲介します。
この仲介に際して、MMU は、
- ソフトウェアがメモリ上に作成可能なページテーブルと呼ばれる(ハードウェア仕様によりフォーマットが定義された)仮想メモリアドレスと物理メモリアドレスの対応を保持するデータ構造を参照し、
- CPU がアクセスしようとしたメモリアドレス(これを仮装メモリアドレスとします)を、ページテーブルに保持されている対応の通りに、物理メモリアドレスへのアクセスへと変換します。
ページテーブル
ページテーブルは、4KB 単位(ページと呼ばれます)で仮想メモリアドレスと物理メモリアドレスの対応を保持するようになっており、上の図の例では、以下のような対応が保持されています。
| 仮想アドレス | 物理アドレス |
| P | A |
| X | D |
| Y | B |
| Z | C |
MMU のアドレス変換に際しては、4KB のページ単位での変換の上、4KB より小さい粒度はオフセットとして加算されます。例えば、上の図では、プログラムは仮想メモリアドレス p に存在し、MMU によって、まず4KB 単位の変換、仮想メモリアドレス P から物理メモリアドレス A に変換されたのち、オフセット (p - P) が A に加算され、(今回の図では (p - P) は (a - A) と同じとして見てください)仮想メモリアドレス p へのアクセスは物理メモリアドレス a へのアクセスに変換されます。
また、「1. メモリアドレス x の値を register 1 へロードする」の操作の場合、実際には、プログラムが x という仮想メモリアドレスへアクセスしようとしたところ、MMU がそれを物理メモリアドレス d へのアクセスへ変換します。((x - X) は (d - D) と同じとして見てください。)
「2. メモリアドレス y の値を register 2 へロードする」は、実際には MMU での変換により、物理メモリアドレス b からの読み込みになります。((y - Y) は (b - B) と同じとして見てください。)
ちなみに、4KB のページ単位で変換を行うと書いてきましたが、ハードウェアとしては2MB、1GB 単位の対応の記述もサポートしており、Linux 等では Huge Page という機能で利用可能です。
ページテーブルのフォーマット
先述の通り、ページテーブルはハードウェアで定義された構造で、ソフトウェアはそれに合わせてメモリ上にデータを用意します。
ページテーブルのフォーマットについては若干実装に寄りすぎるため、ページテーブルが、ソフトウェアがメモリ上に作成可能なデータ構造である、という認識をしていただけたら読み飛ばしていただいても大丈夫と思います。
具体的には、以下の図のように4段の木構造のようになっており(5段もサポートされる場合があります)、仮想メモリアドレスをキーとして、物理メモリアドレスをバリューとするキー・バリューを保持するデータ構造として見ることができます。
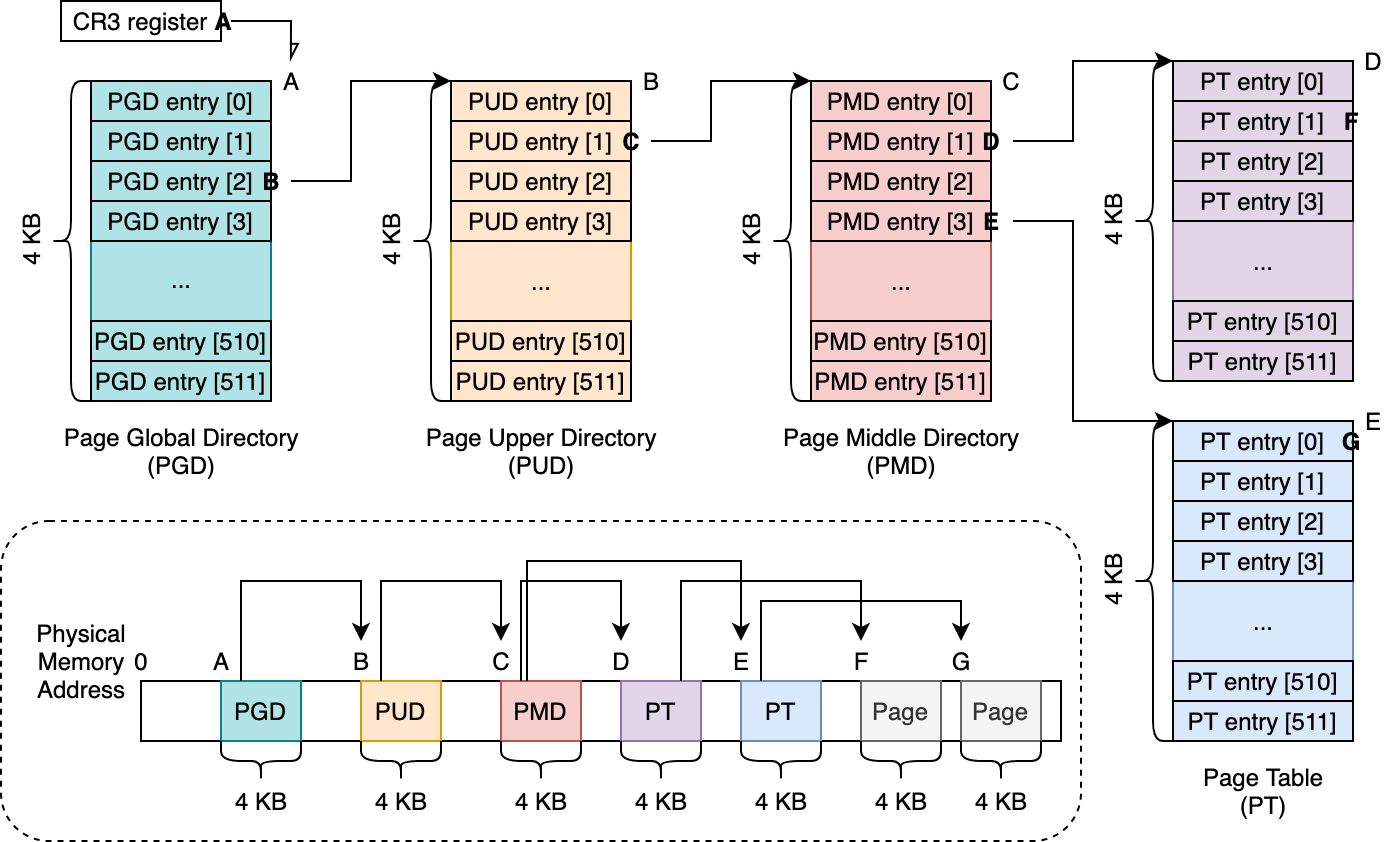
4段の各層には名前がついており、Linux 等ではそれぞれ、
- Page Global Directory (PGD)
- Page Upper Directory (PUD)
- Page Middle Directory (PMD)
- Page Table (PT)
と呼称され、これら全ての構成要素は4KB のページとなっており、8バイトのエントリーを最大 512 個保持します。(それぞれ8バイトの最大 512 要素が持てる配列として捉えられると思います。)ここで、各エントリーは、次の層の4KB ページの先頭の物理メモリアドレスです。また、それら各エントリーは、その参照先の物理メモリアドレスに加え、フラグとして、書き込み可能・不可能等の設定が可能になっています。
上の図の例を使って、具体的にどのように仮想メモリアドレスに対応する物理メモリアドレスをどのように登録するか見ていきます。
先に書くと、上の図では、2つの4KB ページについての対応が保持されています。
| 仮想アドレス | 物理アドレス |
| 0x10040201000 | F |
| 0x10040600000 | G |
仮想メモリアドレス 0x10040201000 に対して、物理メモリアドレス F を対応させるには、以下のような手順をたどります。(以下、512 GB == (1 << 39), 1 GB == (1 << 30), 2 MB == (1 << 21), 4 KB == (1 << 12) として見てください。)
- まず、ページテーブルを辿るときの探索開始位置である PGD の 512 個保持可能なエントリーのどこを見るべきか考えます。
- PGD の各エントリーは、それぞれ仮想メモリ領域の 512 GB ごとに対応しており、0x10040201000 / 512 GB = 2 となるので(0x10040201000 は 10 進数で 1 TB とちょっとくらいです。)、PGD entry [2] を対象の参照位置とします。(仮に、対応を設定したい仮想メモリアドレスが 512 GB より小さければ、PGD entry [0]、512 GB から 1 TB の間であれば、PGD entry [1] が対象になります。)(これらの値は、実装では割り算ではなくて、ビットマスクで算出することが多いと思います。あと、この例では仮想メモリアドレスが 256 TB (512 GB x 512) より小さいとして見てください。)
- ここで、(ページテーブルを実際に作っていっている時のことを想定して)PGD entry [2] に既に値が入っている場合は、その値を元に次の層である PUD を辿り、逆に値がない、つまり PUD への参照がまだ登録されていない場合は、新しく4KB のページを確保し、その4KB のページの物理メモリアドレスを PGD entry [2] へ入れます。
- 上の図では、物理メモリアドレス B に用意された(今回はメモリアロケータを呼び出したら、たまたま物理メモリアドレス B の4KB ページをくれた、という感じをイメージしてください) PUD を、PGD entry [2] から参照するようになっています。
- PUD の各エントリーは、512 GB より小さい、1GB の粒度で次の層に対応する PMD への参照を保持します。ここで、PGD の時と同じように、0x10040201000 のために PUD が保持可能な 512 個のエントリーのどこを参照の対象とすべきか考えます。
- 計算として、(0x10040201000 % 512 GB) / 1 GB = 1 となるので、PUD entry [1] を対象とします。
- ここでも、PGD の時と同じく、PUD entry [1] に参照の値がない場合は、新しく PMD として利用するために4KB ページを確保して、その物理メモリアドレスを代入します。逆に、すでに値が入っている場合は、それを元に次に辿るべき PMD を見つけます。上の図の例では、物理メモリアドレス C の PMD を辿ります。
- ここまで来ると繰り返しで、PMD の各エントリーは2MB 単位の粒度で次の層への参照を保持します。
- 0x10040201000 の参照のために見るべき PMD のエントリーは、(0x10040201000 % 1 GB) / 2 MB = 1 となるので、PMD entry [1] から次の層である PT への参照を辿ります。上の例では、物理メモリアドレス D です。
- PT の各エントリーは4KB ごとのページに対する参照を保持します。ページテーブルの構成としては、ここが終端です。
- 0x10040201000 については、(0x10040201000 % 2 MB) / 4 KB = 1 なので、PT entry [1] が対象になります。
- 最後に、今回の目的であった、0x10040201000 に対応させたい物理メモリアドレス F を(物理メモリアドレス D の) PT entry [1] に入れます。
仮想メモリアドレス 0x10040600000 に物理メモリアドレス G を対応させるには、
- 0x10040600000 / 512 GB = 2 : PGD entry [2] => 物理メモリアドレス B の PUD を参照
- (0x10040600000 % 512 GB) / 1 GB = 1 : PUD entry [1] => 物理メモリアドレス C の PMD を参照
- とここまで、仮想メモリアドレス 0x10040201000 と同じで、
- (0x10040600000 % 1 GB) / 2 MB = 3 なので、PMD entry [3] を参照の対象とします。(0x10040201000 の時は (0x10040201000 % 1 GB) / 2 MB = 1 だったので、PMD entry [1] を辿っていました。)今回の例では、物理メモリアドレス E の PT への参照が入っています。
- 最後に、(0x10040600000 % 2 MB) / 4 KB = 0 なので、(物理メモリアドレス E の)PT entry [0] に物理メモリアドレス G を代入します。
このフォーマットに沿ってソフトウェアでページテーブルを用意してハードウェアに登録すると、CPU からのメモリアクセス時に、そのページテーブルに保持された仮想・物理メモリアドレスの対応に則ってアドレス変換を行ってくれます。
また、PGD の1エントリが 512 GB への対応となっており、それが最大 512 保持可能なことから、256 TB (512GB x 512) が基本的に最大の仮想メモリアドレス空間となります。
ページテーブルの適用
上のフォーマットに合わせて用意したページテーブルを MMU に適用するためには、x86 CPU では、CR3 レジスタに、PGD の先頭の物理メモリアドレスを設定することで行います。上のページテーブルの例の図では、CR3 レジスタに値 A を入れます。(最初の図の例では、CR3 レジスタに値 R を入れます。)
言い換えると、CPU のメモリアクセスに際して、仮想メモリアドレスから物理メモリアドレスへの変換は、CR3 が参照している PGD を起点として構成されているページテーブルに保持されている対応を元に行われる、ことになります。
カーネルによる、非特権モード時のメモリアクセスの制限
ここで一点、重要なこととして、CPU の仕様上、CR3 レジスタへの値の書き込み操作は、特権命令によってのみ行うことが可能である、ということがあります。つまり、非特権モードで動作する、カーネルでないプログラムから CR3 の値を変更することはできません。
この仕様を利用して、特権モードで動作するカーネルは、特定の非特権モードで動作するプログラムがアクセス可能な物理メモリ領域を、ページテーブルの設定を通じて制御することができます。
ポイントは、仮想メモリアドレスを基準に動作するプログラムのメモリアクセスは全て MMU に仲介されるため、非特権モードで動作するプログラムはどう頑張っても MMU が参照するページテーブルに登録されていない物理メモリアドレスへアクセスすることができないところです。(ページテーブルとして利用している物理メモリ領域を非特権モードのプログラムがアクセス可能なように設定にしない、というのが前提になります。)
ユーザー空間プロセスとメモリ管理の関連
汎用 OS は、複数プログラムが一つのコンピューターのリソースを共有しながら利用できるように作られており、その根底にプロセスという抽象的な概念があります。
プロセスとは何であるかを説明するのは難易度が高い気がしますが、プロセスは、プログラムの実行の単位で、リソース割り当ての対象である、というのが遠からずという感じがします。
このリソースとしてわかりやすいところでは、1つの CPU で複数のプログラムが並列で動作する場合、一定時間ごとに実行されるプログラムが切り替わっている(この辺りはよろしければ過去の記事をご参照ください)のですが、この各プログラムの実行のために割り当てられる CPU の実行時間が一つのリソースと言えます。また、物理メモリ領域も同じくプログラムごとに割り当てられるリソースです。
一つのプログラムが動作するためには CPU 時間やメモリ領域等の複数種類のリソースを利用する必要があり、カーネルがそれらリソースをプロセスという単位にまとめて紐づけている、という見方ができそうな気がします。この抽象化の方法によって、例えば、単位時間あたりにたくさんの CPU 時間とメモリ容量を使えるプロセスと、少ししか使えないプロセスのような区別ができるようになります。
また、カーネルが意図した以上のリソースを、プロセスが使えないようにするポイントが、通常のプロセスが非特権モードで動作し、先述の CR3 アクセスにあるようなリソース管理に関わる操作ができないようになっている点で、当記事では、この非特権モードで操作するプロセスをユーザー空間プロセスと呼称しています。
ということで、汎用 OS 環境で、プログラムへの物理メモリ割り当ては、ユーザー空間プロセス単位で行われますが、先述の通り、カーネルはプログラム間でメモリアクセスが干渉しないように配慮する必要があり、このためにカーネルは、あるユーザー空間プロセスが、他のユーザー空間プロセスに割り当てられたメモリに基本的にアクセスできないようにしています。
この OS・カーネルが行うユーザー空間プロセス単位でのメモリ管理を可能にしているのが、ここまでで述べてきた仮想メモリ機構です。
最初の疑問へ戻る
あるユーザー空間プロセスが他のユーザー空間プロセスのメモリにアクセスできない理由
この、あるユーザー空間プロセスが他のユーザー空間プロセスのメモリにアクセスできない、という挙動の実装は、
- カーネルは、ユーザー空間プロセス1つごとに、独立した1つのページテーブルを作成し割り当て、
- カーネルが、1つの物理メモリ領域が、1つのユーザー空間プロセスのページテーブル以外に登録されないように注意する(先述の、仮想メモリアドレスを基準に動作し、メモリアクセスが全て MMU に仲介されるプログラムは、適用されているページテーブルに登録されていない物理メモリ領域へどう頑張ってもアクセスできない、というのがポイントです。)、
ことで達成できます。
このため、汎用 OS 環境では、一般的に各ユーザー空間プロセスが独立したページテーブルを持っており、プロセススケジューラーによって、プロセスが切り替わるタイミングで CR3 の値を書き換え、そこから実行され始めるプロセスのページテーブルを MMU に適用するすることで仮想メモリ領域を切り替えています。
図にすると以下のようになると思われます。
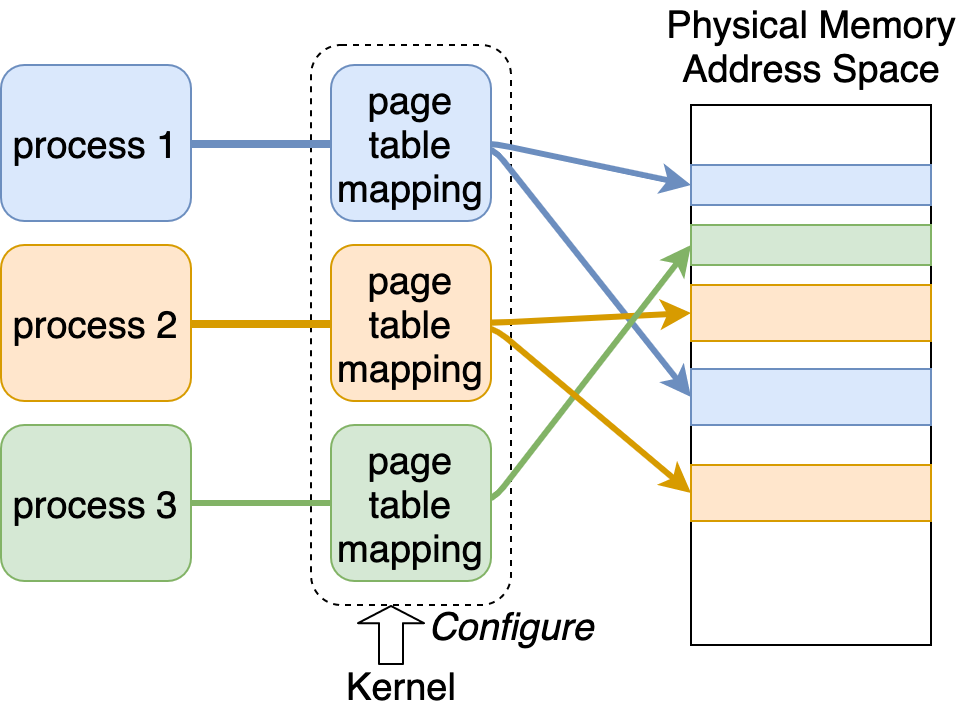
この図では、process 1, 2, 3 が別々のページテーブルを持ち、それぞれについて、カーネルが仮想メモリアドレスと物理メモリアドレスの対応 (page table mapping) を設定しており、例えば、process 1 は、そのページテーブルに物理メモリ領域の参照が登録されてる青い物理メモリ領域しかアクセスできず、別のプロセスに属しているオレンジと緑の物理メモリ領域、また空白(白い)物理メモリ領域にはアクセスできません。更に、カーネルが気をつけて、この青い物理メモリ領域への参照を他のプロセスのページテーブルに登録しないようにすることで、今回の例であれば、process 2, process 3 から、process 1 が利用している青い物理メモリ領域へアクセスできなくなっています。
ユーザー空間プロセスがカーネル空間のメモリにアクセスできない理由
カーネルは、カーネルが利用する物理メモリ領域(つまりカーネル空間のメモリ)への参照をユーザー空間プロセスのページテーブルに登録しないようにすることで、そのユーザー空間プロセスは、カーネル空間のメモリにアクセスできないようにできます。
また、ページテーブルには各4KB ページごとに特権モードでないとアクセスできない、という設定をすることが可能ですが、Meltdown のようなサイドチャネル攻撃の影響を受けるため、最近ではユーザー空間プロセス実行時に利用されるページテーブルは、大部分のカーネルの利用する物理メモリ領域への参照を持たないようになっているようです。これは Kernel Page Table Isolation (KPTI) というような名前で呼ばれるようです。
ユーザー空間のプロセスとスレッドの違いはどのように実装できるか
ユーザー空間のプロセスとスレッドの違いは(Java や Python のような言語のランタイムではなく OS レベルにおいて)、プロセス間はメモリ領域が分離されている一方で、同一プロセス内で生成されたスレッド間ではメモリ領域を共有する、というものがあります。
スレッド間で、全く同じメモリ領域を共有する、という挙動は、それらスレッドで同一のページテーブルを共有することで実現できます。具体的には、同一プロセス内で生成されたスレッドが実行される時には、CR3 が同一の PGD を参照する、ようにします。
図にすると以下のようになります。
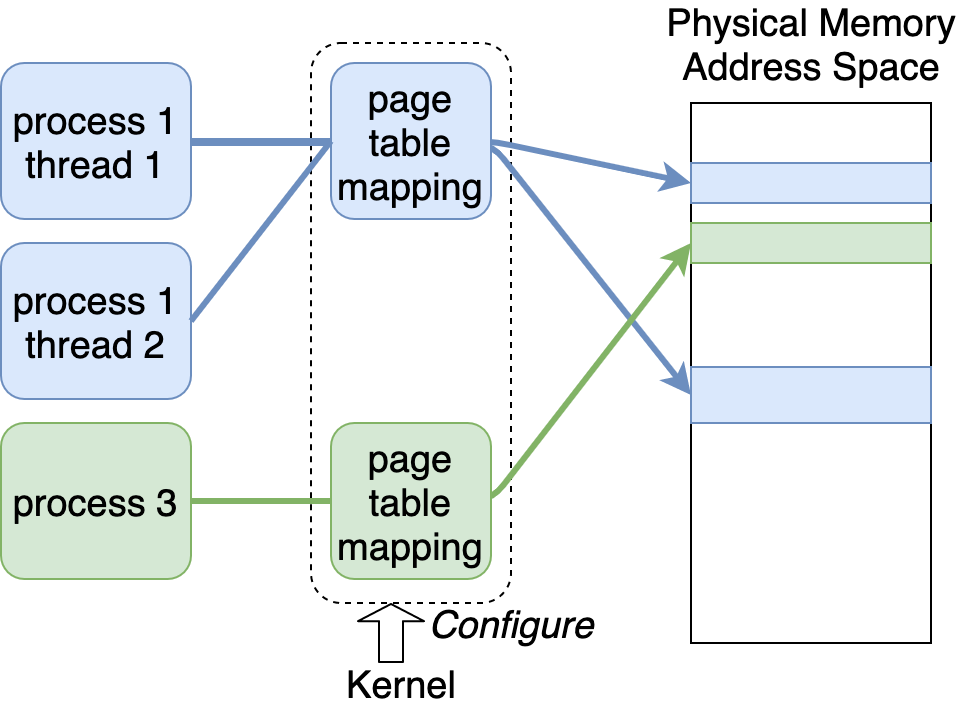
この図では、process 1 に属する thread 1 と thread 2 が同一のページテーブルを共有しています。これにより、これら thread 1, 2 は MMU によるアドレス変換を通じて、全く同じ物理メモリ領域にアクセスできます。
実装としては、Linux でいう task_struct のようなプロセス・スレッドを表す構造体に CR3 が参照すべき PGD の値を保持するフィールドを用意し、プロセス切り替え時にその値を CR3 に適用していくようにしておくとともに、同一プロセス内で生成されたスレッドの task_struct の参照する PGD の値は全て同じになるようにする、というような方法が考えられると思います。(スレッド生成時に、新しくページテーブルを作成せず、スレッド生成元のプロセスと同じページテーブルを使う、という感じで良いと思います。)
共有メモリはどのように実装できるか
共有メモリは、異なるユーザー空間プロセス間、もしくは、カーネルと特定のユーザー空間プロセス間で作成可能です。
異なるユーザー空間プロセス間で共有メモリの作成は、それぞれのユーザー空間プロセスのページテーブルに、同一の物理メモリ領域への参照を登録することで実装可能です。
図にすると以下のようになると思われます。
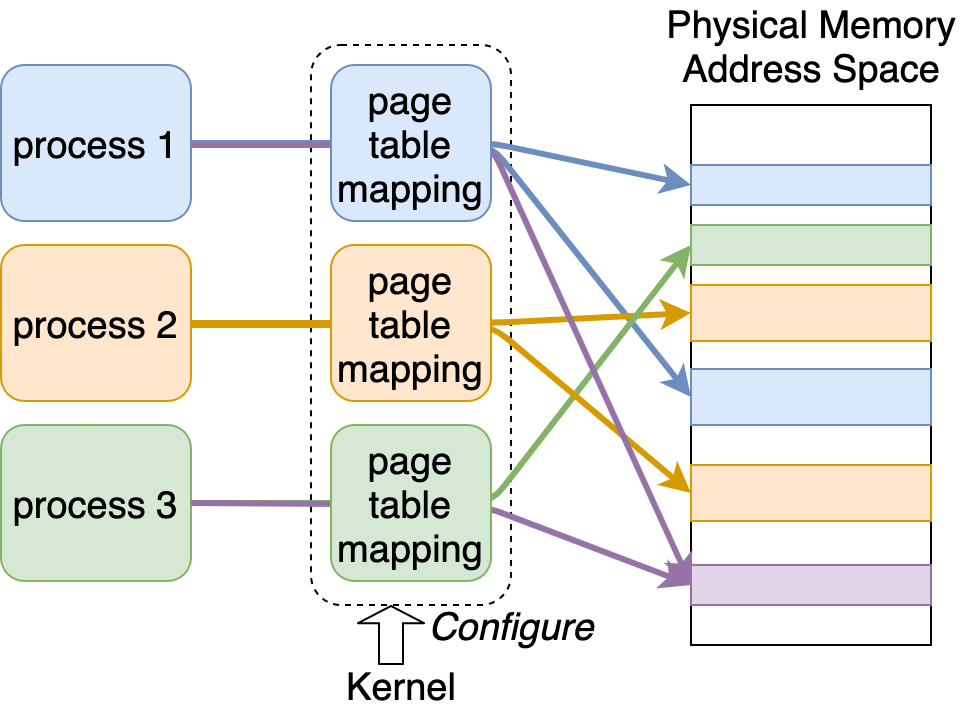
上の図で、紫の物理メモリ領域が process 1 と process 3 にとっての共有メモリになります。これは、カーネルが process 1 と process 3 のページテーブル両方に、この紫の物理メモリ領域への参照を登録することで実現できます。
同じく、カーネルと特定のユーザー空間プロセス間の共有メモリは、カーネル実行中に適用しているページテーブルとそのユーザー空間プロセスのページテーブルの中に、同一の物理メモリ領域への参照を登録することで作成できます。
メモリマップトファイルはどのように実装できるか
ファイルをユーザー空間プロセスのメモリ領域に貼り付けるメモリマップトファイルは、基本的に、カーネルとユーザー空間プロセス間の共有メモリとして実装可能です。
具体的には、通常カーネル空間からのみアクセスできるようになっている、ファイルシステムのページキャッシュとして利用している物理メモリ領域の参照を、特定のユーザー空間プロセスのページテーブルに登録します。
malloc は何故必要か
malloc はユーザー空間に実装されるライブラリコールで、引数に確保したい連続的なメモリ領域のサイズを取り、アプリケーションの呼び出しに応じてメモリの割り当てを行います。
malloc は呼び出された裏側で、必要があれば brk や mmap のようなシステムコールを呼び出し、カーネルに物理メモリの割り当てを要求します。
ユーザー空間のプログラムが基本的に mmap 等を直接利用してメモリを確保しない理由の一つは、メモリ確保の粒度で、ページテーブルの仕様から、カーネル空間からユーザー空間プロセスへの物理メモリ割り当ては4KB 単位となり、それより小さい例えば 100 バイトくらいの領域の確保ごとに4KB を割り当てていると無駄が多い、というのがあると思います。
一方、malloc は、カーネルから4KB 単位で確保した領域から、4KB より小さい領域を切り出してアプリケーションのリクエストに対してメモリの割り当てを行うため、メモリの利用効率が高くなります。
さらに、もう一点は、brk や mmap はシステムコールであるため呼び出しに比較的時間がかかる一方、malloc はライブラリコールであり、追加で brk や mmap の呼び出しが不要の場合は、システムコールを呼び出すより高速である、という利点もあります。
あるコンテナが別のコンテナのメモリにアクセスできない理由
コンテナ間のメモリの分離は基本的に、先述のユーザー空間プロセス間のメモリの分離と同じ仕組みで、カーネルがそれぞれのコンテナ内で動作するページテーブルが同一の物理メモリ領域を参照しないように気を付けているため、あるコンテナは別のコンテナのメモリ領域にアクセスできないようになっています。
コンテナと仮想マシンのメモリ領域の分離についての違い
仮想マシン環境では、Intel VT-x のような仮想化支援のための CPU 機能を利用する場合、
- ゲスト仮想マシンから見える物理メモリアドレス領域自体も先述の仮想メモリアドレスのように仮想化されており、
- ホストは、ゲスト物理メモリアドレスとホスト物理メモリアドレスの対応を保持する Extended Page Table (EPT) とよばれるページテーブル(EPT も通常のページテーブルと同じくハードウェア仕様でフォーマットが決まっており、概ね通常のページテーブルと同じ形式です)をメモリ上に用意し、
- それを仮想化支援機能機構に登録する(EPT の登録は CR3 への書き込みではなく Virtual Machine Control Structure (VMCS) の特定のフィールドに EPT の (PGD と同じような) 参照開始位置のホスト物理メモリアドレスを書き込むことで行います)ことで、
- ゲスト仮想マシンからのホスト物理メモリ領域へのアクセスを制御します。
仮想マシンがアクセス可能な物理メモリ領域の分離は、ホストが異なる仮想マシンの EPT に、同一の物理メモリ領域への参照を登録しないように気をつけることで実現できます。
なので、コンテナは、通常の CR3 へ登録するページテーブルによってメモリアクセスが分離される一方、仮想マシンは、VMCS のフィールドを通して登録する EPT によってメモリアクセスが分離されている、という点が違う、といえるかもしれません。
ただ、分離の基本的な仕組みは両方同じで、1つの物理メモリ領域への参照を、(コンテナの場合)異なる複数のコンテナのプロセスのページテーブルに登録しない、(仮想マシンの場合)異なる複数の仮想マシンの EPT に登録しないようにする、ことなので、本質的に分離の機構に大きな差はないと言えるかもしれません。
一方、コンテナと仮想マシンが大きく異なる点は、同一マシンで実行されるコンテナ全てが単一のカーネルにホストされるのに対し、仮想マシン環境では、それぞれの仮想マシンインスタンスごとに1つのカーネルが動作し、ある仮想マシン上で動作するカーネルは、他の仮想マシン上で動作するカーネルとメモリ領域を共有していない、という点であると思われます。
この差異による問題として、カーネル内のコンテナのための分離機能でバグがあることがあるらしく、結果として、カーネルを共有しない仮想マシンの方が分離の強度が高いと言われる所以となっていると思われます。
まとめ
- 汎用 OS 環境ではプログラムは基本的に仮想メモリアドレスを元に動作する
- 仮想メモリ機構は、MMU という CPU がアクセスしようとした(仮想)メモリアドレスを物理メモリアドレスへのアクセスへ変換するハードウェアの機能に依存している
- MMU の仮想メモリアドレスから物理メモリアドレスへの変換は、ソフトウェアから、ページテーブルの用意と CR3 へのレジスタへの設定によって操作可能である
- CPU の仕様上、 CR3 の操作が非特権モードで動作するユーザー空間プロセスに許可されていないことを利用して、カーネルは特定のユーザー空間プロセスがアクセス可能な物理メモリ領域をページテーブルの設定を通じて行うことができる
- ページテーブルの設定により、ユーザー空間プロセス間のメモリアクセスの分離、プロセスとスレッドの違い、共有メモリ、メモリマップトファイル等の実装が可能である
その他補足
ページフォルト
ページテーブルには必ずしも全ての仮想メモリ領域( 256 TB )について物理メモリページへの参照を登録する必要はありません。
仮に、プログラムが物理メモリページへの参照が登録されていない仮想メモリアドレスへのアクセスがあった場合には、ページフォルトと呼ばれる CPU 例外が発生し、通常 OS・カーネルが事前に登録しているページフォルトハンドラに処理が移行します。
物理メモリページへの参照が登録されていない仮想メモリアドレスへのアクセスによるページフォルトは、C 言語等でプログラムを書いているとよく見るセグメンテーションフォルトと呼ばれる違反の原因の一つだったりします。
デマンドページング
物理メモリページへの参照が登録されていない仮想メモリアドレスへのアクセスによってページフォルトが発生した時に、OS・カーネルは、ページフォルトハンドラの中で、該当する仮想メモリアドレス領域に新しく物理メモリページへの参照を追加したのち、ページフォルトを起こしたプログラムへ処理を戻すこともできます。この場合、特に問題がなければそのプログラムは続けて動き続けることができます。
この特性を利用して、プログラムが実際にアクセスして利用を開始するまで、物理メモリページへの参照をページテーブルに登録しない、つまり、物理メモリ領域をプログラムのために割り当てない、という操作を行うことも可能で、これはデマンドページングと呼ばれるそうです。
OS・カーネルにメモリ確保をリクエストするインターフェース
汎用 OS 環境で、物理メモリページへの参照が登録されていない仮想メモリアドレスへのアクセスによってページフォルトが発生した時に、セグメンテーションフォルトとしてプログラムを停止するか、物理メモリ領域への参照をページテーブルに追加して、処理をプログラムへ戻すかは、事前にそのプログラムが該当する仮想メモリ領域への物理メモリ割り当てを OS・カーネルにリクエストしていたかどうか、ということによる場合が多いと思われます。
UNIX 系 OS では、mmap のようなシステムコールで、ユーザー空間プロセスはカーネルに対して、物理メモリ割り当てを要求できます。
mmap システムコールは引数の一つとして、割り当てて欲しいメモリのサイズを取り、戻り値として、仮想メモリアドレスを返します。
この結果、mmap システムコールを実行したユーザー空間プロセスは、「戻り値で受け取った仮想メモリアドレス」から「戻り値で受け取った仮想メモリアドレス + mmap に割り当てて欲しいメモリのサイズとして渡した値」までの仮想メモリ領域へは、カーネルが物理メモリへの参照をページテーブルに登録してくれることが(基本的に)保証されます。
一方、カーネルは mmap システムコール実行時に、必ずしもこの物理メモリ領域への参照をページテーブルに登録する必要はなく、ページテーブルには触らないで、戻り値となる仮想メモリアドレスを決めて、それを返すだけにすることもできます。この場合、ページフォルト発生時に、ページフォルトハンドラ内で、フォルトが発生した仮想メモリアドレスを確認し、それが mmap システムコールを通して、ユーザー空間プロセスに対して物理メモリの割り当てを約束した仮想メモリ領域であれば(上の mmap の結果「戻り値で受け取った仮想メモリアドレス」から「戻り値で受け取った仮想メモリアドレス + mmap に割り当てて欲しいメモリのサイズとして渡した値」までの仮想メモリ領域であれば)、該当する仮想メモリ領域のページテーブルのエントリーに物理メモリ領域への参照を追加し、処理をユーザー空間プロセスへ戻すような、デマンドページングの方式を採用することができます。(この機能のためには、カーネルは、ユーザー空間プロセスのどこの仮想メモリアドレス領域に物理メモリの割り当てを約束したかを記録しておく必要があると思われます。)