TCP/IP スタックを自作する
最近、TCP/IP スタックを自作しており、少し動くようになってきたので、それについて記事にしてみようと思いました。
主に、ポータブル(特定の CPU、NIC、OS、ライブラリ、コンパイラ機能に依存しない)かつマルチコア環境で利用できる実装があればいいなと思ったことが、モチベーションになっています。
まだ実装の途中ではありますが、ソースコードは GitHub に置いてありますので、よろしければお試しください。
GitHub - yasukata/iip: iip: an integratable TCP/IP stackgithub.com
モチベーション
TCP/IP スタック実装はインターネット上でいくつか見つけることができるのですが、それらの多くが可搬性についてあまり意識されておらず、込み入ったことをしようと思うと取り回しが良くない、というような印象を持っていました。
具体的には、既存の多くの TCP/IP スタック実装が、
- 特定の OS、ライブラリやネットワーク I/O 機能の実装(例えば tap デバイスや DPDK 等)に依存し、
- 更に、内部でそれらを利用するためのサブシステムが独自に実装されており、かつ、それらが外部から隠蔽されている
- また、TCP/IP スタック実装に、TCP/IP スタックの処理を実行するスレッドが含まれている
結果として、
ということがあると思いました。
1. 他のシステムとの統合・コンパイルそのものが難しい場合がある
例えば、ある TCP/IP スタック実装を、pthread (カーネルによって管理されるスレッド)をユーザー空間スレッドに置き換えるようなアイデア・実装 (e.g., Shenango (NSDI'19), Caladan (OSDI'20)) と組み合わせたいと考えた場合に、その TCP/IP スタック実装が pthread と pthread を想定したロックに依存していた場合、統合・コンパイル自体が難しくなります。
また、新しく設計・実装された OS 等の、既存の標準ライブラリとの互換性が十分でないシステムの上では、標準ライブラリに依存する TCP/IP スタックの実装を動かすことは難しいです。
更に、TCP/IP スタック実装が依存するライブラリやビルド環境の中に一つでもうまく機能しないものがあると、ビルド自体が成功しなかったり、コンパイルできても利用者側から解消が難しいバグ等で実装全体が利用できなくなってしまうことがあるため、依存関係はなるべく新規に作らない方が利用者側はありがたい場合が多いと思いました。
2. 機能の隠蔽により、最適化がしにくくなる場合がある
例として、ディスクからメモリへ読み込んだデータをそのままヘッダだけ付与して NIC から転送する sendfile システムコールと同様の挙動を実装しようとすると、既存の TCP/IP スタック実装の多くが、NIC に紐づいているパケットバッファを TCP/IP スタック実装の内部で独自に確保・使用し、更に、それは TCP/IP スタック実装外部へは隠蔽されており、ディスク上のデータの読み込み先として指定することが難しいため、sendfile のようなディスクと NIC の間のデータの移動でコピーを削減する機能を実装しにくいというようなことがあります。
3. TCP/IP のプロトコル処理を行うスレッドの実行形式が限定されてしまう
多くの TCP/IP スタック実装は自前でプロトコル処理を実行するスレッドとその起動部分も含めて実装しており、結果として、CPU 効率の良くない実行形式を採用せざるを得なくなるということがあります。
TCP/IP スタック実装が自前でプロトコル処理を実行するスレッドを実装することの弊害
具体的には、TCP/IP スタック実装が自前でプロトコル処理を実行するスレッドを実装すると、以下のようなキューを通してアプリとやり取り・連携を行う場合が多いと思います。以下の疑似コードの中では net_thread_fn が TCP/IP スタック実装に含まれ、初期化時に自動的に起動されるものとします。
shared_rx_payload_queue; shared_tx_payload_queue; net_thread_fn() { while (1) { // NIC から受信パケットを取り出す rx_pkt = nic_rx(); // 受信パケットをプロトコルスタックに渡しペイロードを取得 rx_payload = tcpip_rx(rx_pkt); // 受信したペイロードをアプリの受信キューに入れる enqueue(shared_rx_payload_queue, rx_payload); // アプリの送信キューからペイロードを取り出す tx_payload = dequeue(shared_tx_payload_queue); // 送信用ペイロードにプロトコル処理を施してパケットにする tx_pkt = tcpip_tx(tx_payload); // パケットを NIC から送信する nic_tx(tx_pkt); } }
この場合、TCP/IP スタック実装利用者(アプリ開発者)は以下のように独自でアプリ固有の処理を実行するスレッドを実装することになります;アプリは shared_rx/tx_payload_queue を通して、TCP/IP スタック実装とデータのやり取りを行います。
shared_rx_payload_queue; shared_tx_payload_queue; app_thread_fn() { while (1) { // アプリの受信キューからペイロードを取り出す rx_payload = dequeue(shared_rx_payload_queue); // アプリ固有の処理で応答データを生成 tx_payload = handle_request(rx_payload); // アプリの送信キューへペイロードを入れる enqueue(shared_tx_payload_queue, tx_payload); } }
上記の形式の問題は、TCP/IP スタックのプロトコル実装を行うスレッドとアプリを実行するスレッドが別になってしまい、CPU 利用効率を最大化するのが難しくなるということがあります。
具体的には、例えば、以下を設定1として、
- CPUコア0 が TCP/IP スタックの処理 net_thread_fn のスレッドを実行し、
- CPUコア1 がアプリ固有の処理 app_thread_fn のスレッドを実行する
とすると、
仮に、アプリのワークロードがプロトコル処理よりも重い場合、アプリを実行する CPU1 は使用率が 100% になる一方で、プロトコル処理を行う CPU0 の使用率は例えば 10% 程度に留まるようなことが考えられます。この場合、CPU0 の残りの 90% の CPU 時間はこのアプリのために利用することはできないため、本来2つの CPU コアで 200% 分の CPU 時間を利用できる環境でも 110% しか CPU 時間を利用できなくなってしまいます。
言い換えると、この設定1では、TCP/IP スタックの処理に必要な CPU 時間とアプリの処理に必要な CPU 時間が一致した時以外は、CPU が意味のある仕事をしない空き時間ができしまいます。
別の可能性として、以下を設定2とすると、
- CPUコア0 が TCP/IP スタックの処理 net_thread_fn のスレッドとアプリ固有の処理 app_thread_fn のスレッド両方を実行する
- CPUコア1 も TCP/IP スタックの処理 net_thread_fn のスレッドとアプリ固有の処理 app_thread_fn のスレッド両方を実行する
というように、二つのスレッドを一つの CPU コアで動かし、それを複数の CPU コアで行うという方法も考えられます。
この設定2の場合であれば、それぞれのスレッドが仕事がない時には CPU を手放すように実装されていると、TCP/IP スタックの処理が使わなかった CPU 時間はアプリが使うことができ、逆も可能であるため、先述の設定のような 110% しか合計で CPU 時間を利用できない、というようなことはなくなり、CPU 時間を最大限 200% まで使えるようになると思われます。
ただ、こちらの設定2は、同一 CPU コアの上で動作する二つのスレッドの切り替えが頻繁に行われる必要があり、プロセス・スレッドスケジューリングの負荷が追加されることによる性能の劣化の懸念があります。更に、TCP/IP スタック実装が DPDK のような仕事がなくても CPU を手放さないシステムを採用していると、スレッド間の切り替え頻度が低くなり、性能が大幅に劣化することが予想されます。
TCP/IP スタック実装が自前でプロトコル処理を実行するスレッドを実装しないことの利点
一方で、TCP/IP スタック実装に、TCP/IP スタックの処理を実行するスレッドが含まれていない場合には、以下のようにプロトコル処理を含むネットワーク関連の処理と、アプリ固有のリクエストについて応答を生成する処理を同じ while ループに含めることができ、上記の二つの設定の問題を全て回避することができます。
thread_fn() { while (1) { // NIC から受信パケットを取り出す rx_pkt = nic_rx(); // 受信パケットをプロトコルスタックに渡しペイロードを取得 rx_payload = tcpip_rx(rx_pkt); // アプリ固有の処理で応答データを生成 tx_payload = handle_request(rx_payload); // 送信用ペイロードにプロトコル処理を施してパケットにする tx_pkt = tcpip_tx(tx_payload); // パケットを NIC から送信する nic_tx(tx_pkt); } }
これまでの表記に合わせると、CPU コアの設定は以下のようになります。
- CPUコア0 が thread_fn のスレッドを実行する
- CPUコア1 も thread_fn のスレッドを実行する
これで、1)TCP/IP スタックの処理が使わなかった CPU 時間はアプリが使うことができ、その逆も可能である、2)TCP/IP スタックの処理とアプリの処理の間でプロセス・スレッドの切り替えが不要、になります。
lwIP
一方、lwIP という実装は、利用者が1)CPU や OS、既存のライブラリ等への依存度が低く、2)プロトコル処理以外の箇所はあまり隠蔽されておらず、更に、3)lwIP 自体がプロトコルの処理を行うスレッドを実装していないため、個人的に非常に利用しやすく日頃から大変お世話になっているのですが、lwIP は 20 年以上前に小型の組み込みデバイスを想定して設計・実装されていることから、
というようなことがあり、できれば上記の点が解消された実装があれば嬉しいと思っていたため、今回、新しく作ってみることにしました。
今回の実装のポイント
上記のことから、今回は、以下のポイントに注意して実装しています。
- プロトコル処理の実装が特定の CPU、NIC、OS、ライブラリ(DPDK のようなネットワーク I/O 機能実装を含む)、コンパイラ機能に依存しない;プロトコル処理の実装に、標準ライブラリを含む外部のライブラリを利用せず、コンパイラ機能も最低限のものだけを使うようにしました。今回は C 言語で実装しています。
- 外部の実装に対して、隠蔽する機構を最小限にする;外部のライブラリへ依存しないようにすることで、隠蔽の対象はそもそも多くないですが、以下5(NIC とアプリの間でコピーをなくすことができるようにする)のためにパケットバッファの確保・開放機能を内包しない点に注意しています。
- TCP/IP スタック自身がプロトコル処理を実行するスレッドを実装しない;TCP/IP スタック利用者(アプリ開発者)が用意したスレッドの中で定期的に実行されることを想定した関数(API)の中で TCP/IP スタックの処理を実行するようにしました。
- NIC のオフローディング機能を利用できるようにする;NIC とそれを管理するネットワーク I/O 機能は TCP/IP スタック利用者(アプリ開発者)に所属するため、TCP/IP スタック実装利用者に NIC がサポートしているオフロード機能の通知と、それを特定のパケットに対して適用する機能を持ったコールバック関数を実装してもらうようにしました。
- NIC とアプリの間でコピーをなくすことができるようにする;渡されたパケットについて、そのままプロトコル処理を行うようにしました。
- 複数スレッドで同時に実行でき、マルチコア環境で性能がスケールするようにする;過去の実装にあるように (e.g., mTCP (NSDI'14))、各 CPU 上で動作するスレッド間で共有するメモリオブジェクトを作らないようにしました。
性能
簡単に性能を計測してみました。
今回はネットワーク I/O のバックエンドとして、DPDK を利用しました。
環境
2台の同じ以下の設定のマシンを利用
ワークロード
小さいメッセージのやり取りをするワークロード
結果
計測結果は以下のようになりました。目安として Linux カーネルの TCP/IP スタックについても同様のベンチマークを行いました。
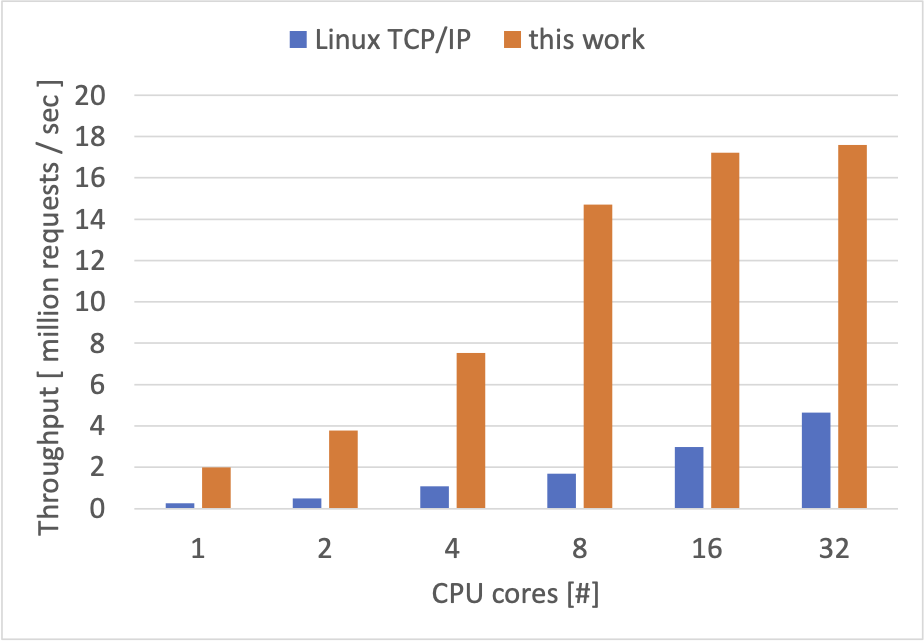
現状では、16 CPU コアまではある程度性能が伸びていく一方、それ以降は 32 CPU コアまで計算リソースを追加しても大幅な性能の改善が見られませんでした。
性能の限界の要因を調査する
16 CPU コア以降性能が大きく向上しない原因について簡単に調べてみようと思いました。
pqos コマンドを使って、CPU・メモリに関する情報を取得してみました。
以下は、それぞれの CPU コアについて得られた結果 ( https://github.com/intel/intel-cmt-cat/wiki/PQoS-monitoring-metrics-definition ) を合計したグラフです。
Instruction Per Cycle (IPC)
IPC は単位時間あたりに処理できた CPU 命令数で、高いほど CPU が効率よくプログラムを実行できているという目安になるようです。
全ての CPU コアの IPC の値の合計を並べてみると、上のスループットの結果と近い傾向が見られました。
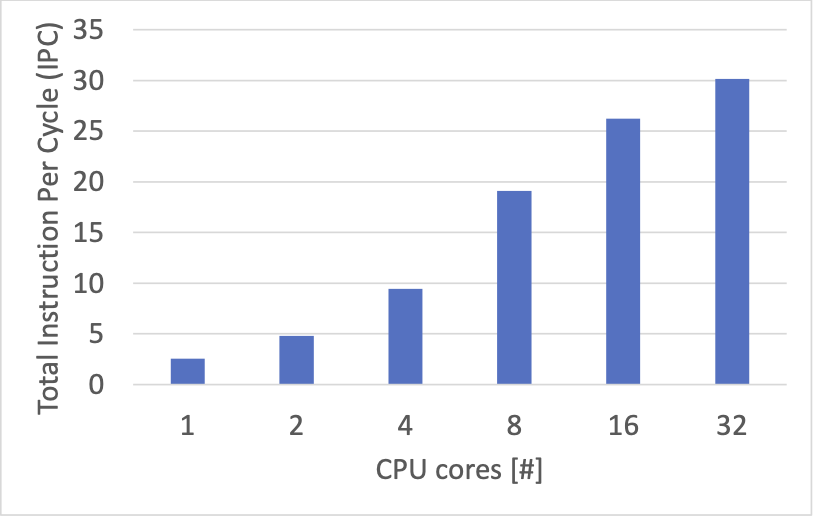
1CPUコア あたりの IPC についてみると、1〜8CPU コアくらいまでは、概ね 2.3 ~ 2.5 くらいで、16 CPU コアで 1.6 くらい、32 CPU コアの時には 0.9 ~ 1.0 くらい、というような感じでした。
Last-level Cache Miss 回数
全ての CPU コアで発生したキャッシュミス回数の合計をプロットすると、以下のようになりました。
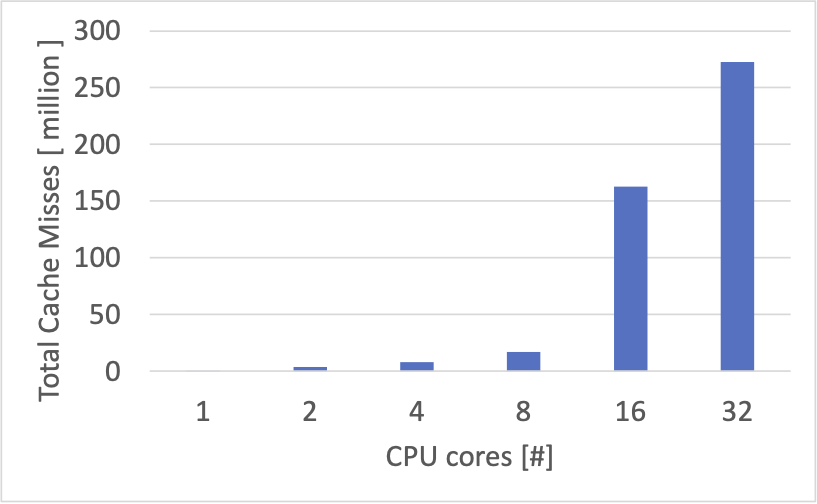
8 CPU コアから 16 CPU コアへかけてキャッシュミス回数が大きく増えているようです。
16 CPU コアからの IPC の低下は、キャッシュミス回数に関係があるかもしれません。
メモリの帯域使用量
各 CPU コアが利用したメモリの帯域の合計をプロットすると、以下のようになりました。
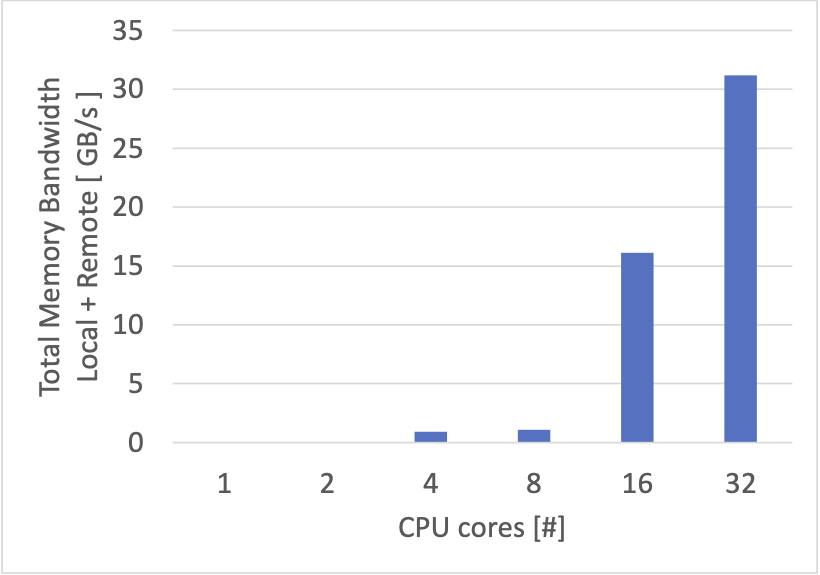
こちらはキャッシュミスの増加にあわせて、8 CPU コアから 16 CPU コアにかけての箇所で大幅な増加が見られます。
キャッシュの占有状況
各 CPU コアが占有しているキャッシュのサイズの合計をプロットすると、以下のようになりました。
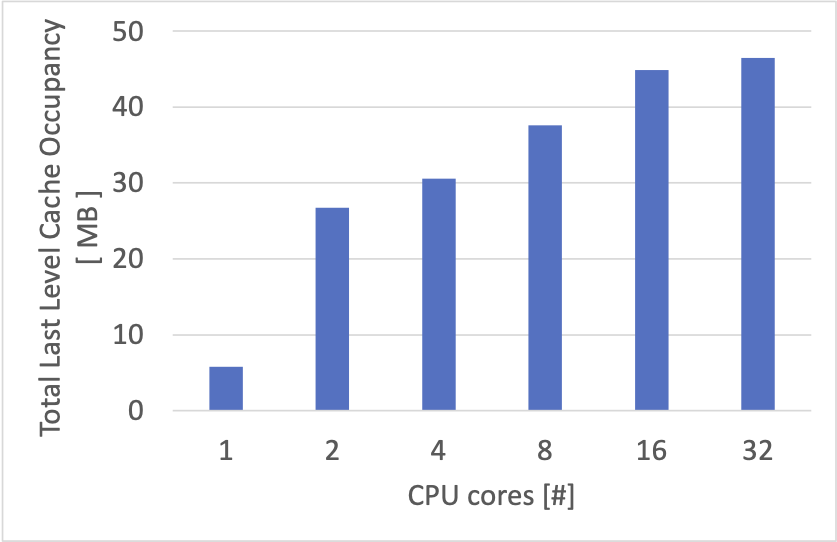
今回使用したマシンの CPU はそれぞれ 24 MB のキャッシュを持っているようなので、2つ合計で 48 MB が上限と思われます。
上のグラフからは、16 ~ 32 CPU コアの場合には、ほぼ全体のキャッシュ容量を使い切っているように見えます。
キャッシュのサイズの影響をもう少しみる
先ほどまでは、2CPU のそれぞれのコアをバランスよく同数利用していたため、合計 48 MB のキャッシュが利用できましたが、今度は、全てのスレッドを1つの CPU の上で動かして計測を行ってみました。この場合、16 CPU コアまで同じコア数でありながら利用可能な最大のキャッシュサイズが 24 MB になるはずです。
以下は、同じ実験のスループットの結果です。(青い 2 CPU の時は、先ほどまでの実験結果と同じです。)
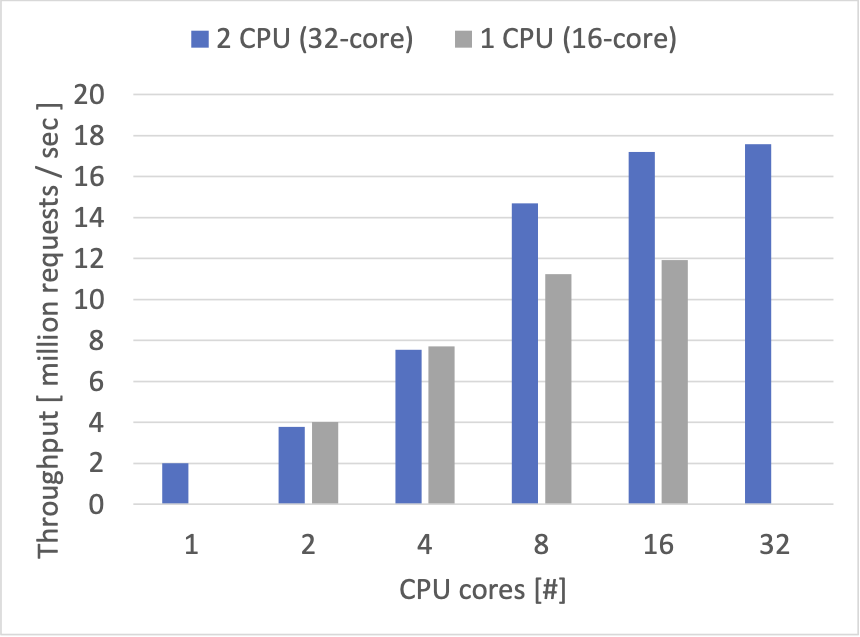
同じ CPU コア数を利用しても、1CPUの時の方が低い性能となりました。
以下は、計測した合計のキャッシュ占有状況です。
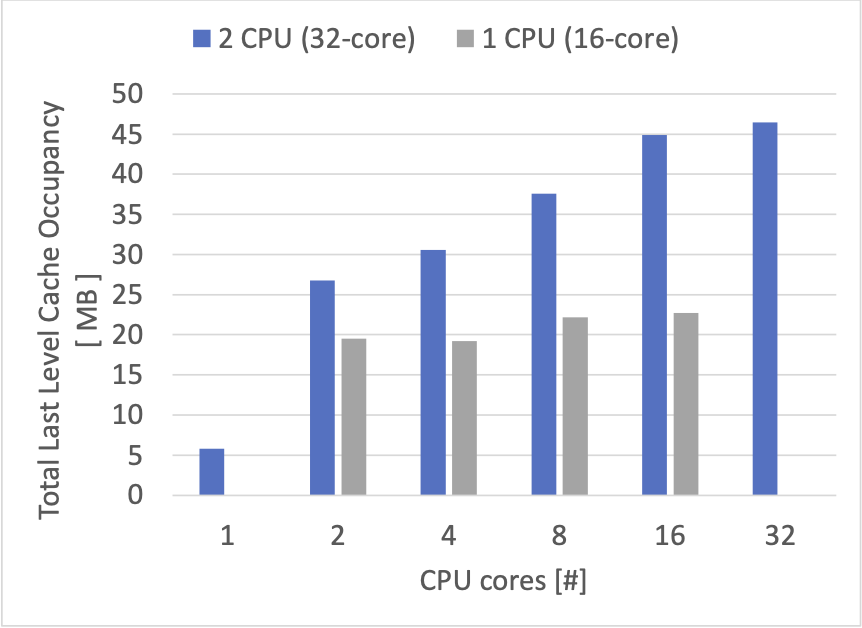
1CPUの場合は合計 24 MB 以下で頭打ちになっています。
性能限界の要因の予想
これ以外にも要因はあると思われますが、16 ~ 32 CPU コアが同時に作業しようとした場合、それら全てが一定時間内に扱うデータ量の合計が、CPU が搭載しているキャッシュのサイズを超えてしまい、結果として、(2CPU利用時)8 CPU コアから 16 CPU コアにかけて、大幅なキャッシュミスの増加とそれに伴うメモリへのアクセスの増加が発生しており、結果としてメモリの読み書き待機のために IPC が低下している、ということを、CPU コア数を増加させても性能が向上しなくなる要因の一つとして予想します。
まとめ
- 他のシステムと統合しやすいくマルチコア環境で利用できることを目指した TCP/IP スタックを作っています。
- 現在の実装は、キャッシュサイズの不足によってマルチコア環境でのスケーラビリティが制限されているのではないかと予想します。
追記 2023/11/07
キャッシュ効率を悪化させているポイントを発見し改善すると性能が 50 million リクエスト毎秒まで向上しました。(前のバージョンは 17.5 million リクエスト毎秒が最大でした。)
以下のグラフは上のものと同じ実験をした結果です。
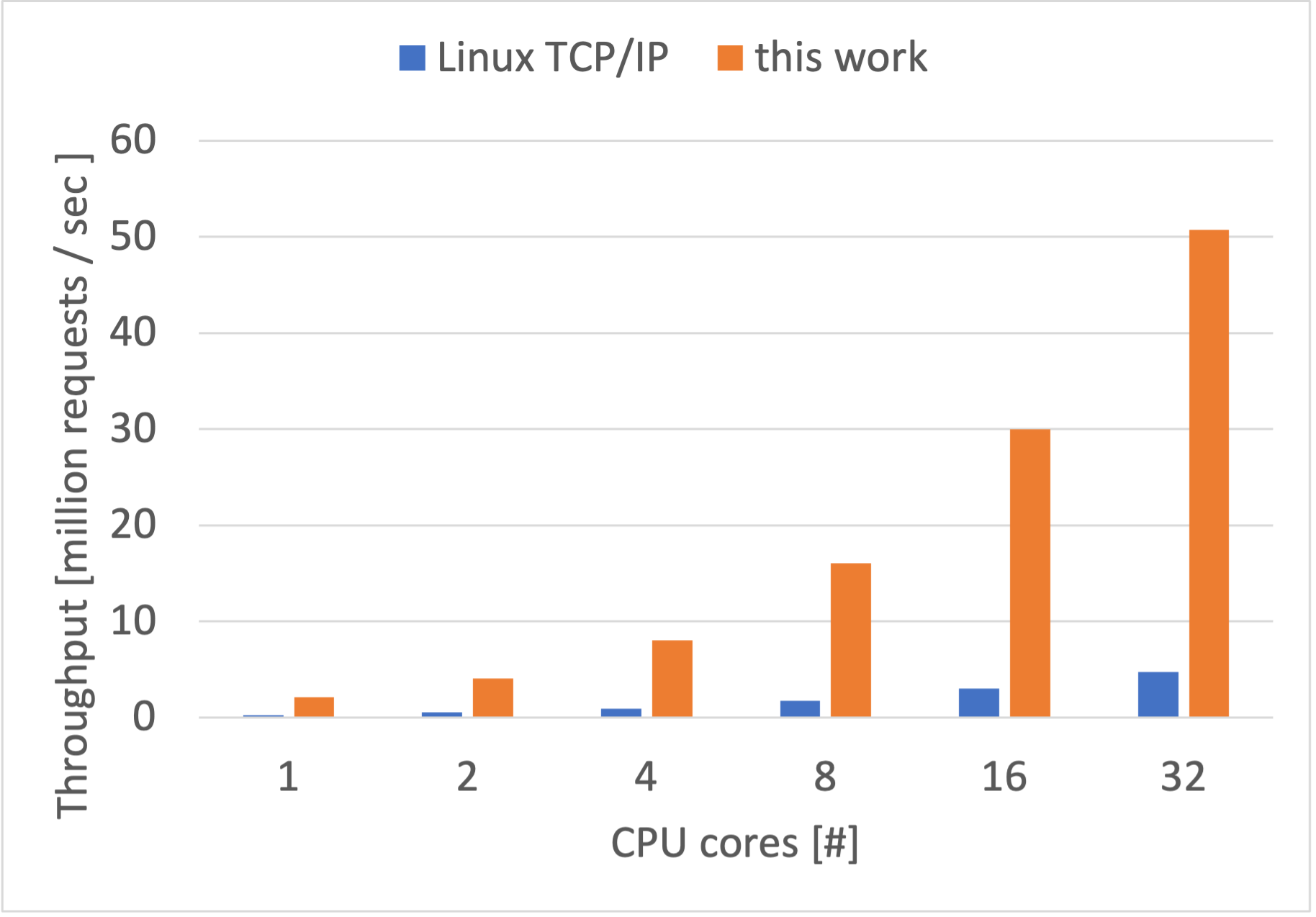
具体的には、TCP/IP スタック実装内でパケットへの参照を保持する Linux で言えば sk_buff のような構造体の確保・開放の方法に、キャッシュ効率悪化の原因がありました。
当初は、この構造体を予め所定の個数 malloc した後、キュー(連結リスト)のようなデータ構造に入れておき、新たに確保したい場合は先頭から取り出し、開放時には最後尾に追加する、というような実装で確保・開放を行なっていました。
ですが、確保・開放を繰り返した場合に、この構造体は先頭から取り出され末尾に追加されることで、ローテーションしてしまうため、結果として、毎回確保時に取り出される先頭のものは多くの場合でキャッシュに乗っていない、ということが原因でキャッシュ効率が低下しているようでした。
このため、この構造体を開放時に末尾ではなく、先頭に追加するようにするだけで、性能が大幅に改善しました。
変更としてはこのパッチにあたります。