マルチコアでスケールするB木を書いてみた
Optimistic, Latch-Free Index Traversal (OLFIT) という手法を提案している、Cache-Conscious Concurrency Control of Main-Memory Indexes on Shared-Memory Multiprocessor Systems という論文を参考に、マルチコア環境でスケールするB木を書いてみました。
Optimistic Concurrency Control (OCC) (日本語では楽観的並行性制御)について勉強になったので記事にしてみようと思いました。
ソースコードを GitHub に置いておきましたので、ご興味がありましたら是非試してみてください。
B木の並列操作
B木はファイルシステムや、キーバリューストア (KVS) 、データベースでよく利用されるデータ構造です。キーとバリューのペアを効率よく保存できます。
最近のコンピューターではマルチコアが比較的一般的になっているので、多くのプログラムにとって、コアを増やすほど速くなる、というのが一つの大事な要件になっています。KVS 等においてもこの点は例外ではありません。
KVS 等のソフトウェアは、B木のようなデータ構造を元にデータを保存しますが、複数コアが並列でデータの追加、更新、探索を行う場合、B木等のデータ構造の操作自体が競合のポイントになりがちです。
今回は、データ構造の並列操作に伴う競合による性能の低下を抑える手法の一つである Optimistic Concurrency Control (OCC) という仕組みを取り入れてB木を書いてみました。(厳密にはB+木を書きました。)
readers-writer ロックの問題点
並列性に配慮したプログラムで比較的よく利用されるロックに readers-writer ロックと呼ばれるものがあります。
このロックには、書き込みロックと読み込みロックの2種類があり、同じロックのオブジェクトについて、書き込みを行いたい場合、書き込みロックを、読み込みを行いたい場合は読み込みロックを取得します。
書き込みロックは、ほかに書き込みロックを取っているワーカーがおらず、かつ、読み込みロックを取っているワーカーもいない場合に取得できます。一方、読み込みロックは、書き込みのロックが取られていなければ取得できます。
これにより、同じデータの読み取りを行うワーカーが複数いたとしても、互いをブロックしないで同時に読み込みを行うことができます。
一見、readers-writer ロックには問題がないように見えるのですが、CPU のキャッシュが性能において重要になるB木のようなデータ構造では、キャッシュ効率の観点から性能が伸びない場合が多いようです。
readers-writer ロックの問題として、 書き込みロックだけでなく、読み込みロックも、書き込みロックが取られないように、現在読み込み中であることを示すために、メモリ上のロックのオブジェクトの値を更新する必要があるということがあります。
ある CPU によって更新されたメモリ上の値が他の CPU から参照される場合には、更新された値については 参照する側の CPU キャッシュが効かないため、ロックオブジェクトの値の読み込みには時間がかかります。
readers-writer ロックは多くの場合でマルチコアスケーラビリティを達成できる方法である一方で、CPU キャッシュが性能において重要なシステムでは問題になる場合があります。
Optimistic Concurrency Control (OCC)
OCC は CPU キャッシュを効かせやすい並列実行制御の方法として利用されることがあります。OLFIT の論文では、OCC を適用した B link Tree を提案しています。
OLFIT の特徴として、読み込み時にラッチ(ロック)を獲得しないという点があります。OLFIT では、ラッチとバージョン番号という2つのオブジェクトを使って並列操作の制御を行います。
OLFIT の論文に記述されている更新アルゴリズムは以下のようになります。
1. ラッチを取得する
2. コンテンツを更新する
3. バージョン番号を増加させる
4. ラッチを解放する
以下が読み込みアルゴリズムです。
1. バージョン番号を取得する
2. コンテンツを読み込む
3. ラッチが獲得されているかを確認する。もし獲得されていれば1に戻ってやりなおす
4. 再度バージョン番号を取得する。もし、取得したバージョン番号が1で取得した値と違った場合、1に戻ってやりなおす
以上が、基本的な操作の仕組みです。
ポイントは、読み込み操作にメモリ上のオブジェクトに対して書き込みが不要であるということです。readers-writer ロックと異なり、OLFIT では、読み込み操作は、書き込み操作をブロックしません。そのかわりに、バージョン番号を用いて変更を検出できるようにしておき、もし読み込み側が変更を検出した場合には、変更が検出されなくなるまで読み込みをやりなおす、という戦略を採用しています。
今回は、この仕組みを使って、並列操作が可能なB+木を実装してみました。
性能
1千万件のランダムな8バイトキーと8バイトのバリューを追加するベンチマークをしてみると以下のような結果になりました。
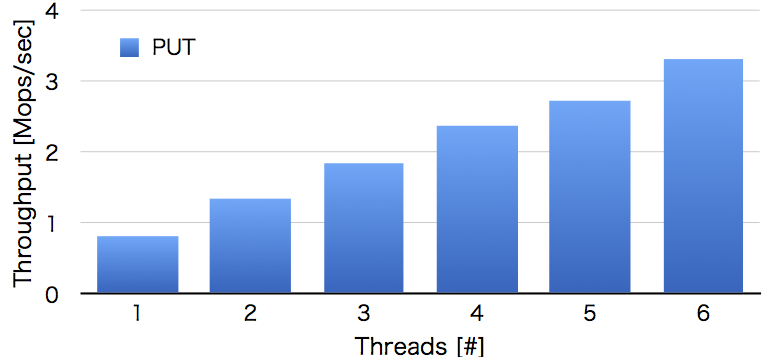
もっとうまく実装できればこれ以上に速くなると思うのですが、今回は完全にスケールするというところまではいきませんでした。ですが、スレッド数に合わせて線形に性能が伸びているのでそこまで悪くない結果だと思います。
その他の資料
マルチコアでスケールするツリー構造といえば Masstree が有名ですが、Masstree の設計は OLFIT に影響を受けているそうです。