ネットワークスタックの高速化手法についてまとめました。
これらの手法が提案された背景には、10Gb NIC 等の高性能なハードウェアの値段が下がり、汎用化が進んだ一方で、汎用 OS のネットワークスタック実装では、それらの性能を十分引き出せないという問題があります。
特に、小さいパケットをやりとりするワークロードや、短い TCP コネクションをたくさん処理するようなワークロードで、10Gb, 40Gb のラインレートを達成するのが難しく、様々な解決策が提案されています。
システムコールバッチング
システムコールは、ユーザー空間とカーネル空間のコンテキスト切り替えのための処理を必要とし、Web サーバーやキャッシュサーバー等の高速なメッセージの送受信が必要なシステムにおいて、性能劣化の原因となることが問題として指摘されています。
以下の論文では、システムコールバッチングをこの問題の解決策として提案しています。複数システムコールをまとめて実行することで、コンテキスト切り替え時に発生するコストをまとめることができ、性能を向上できると報告されています。
システムコールをバッチすると、どのようないいことがあるのかを絵に描いてみました。
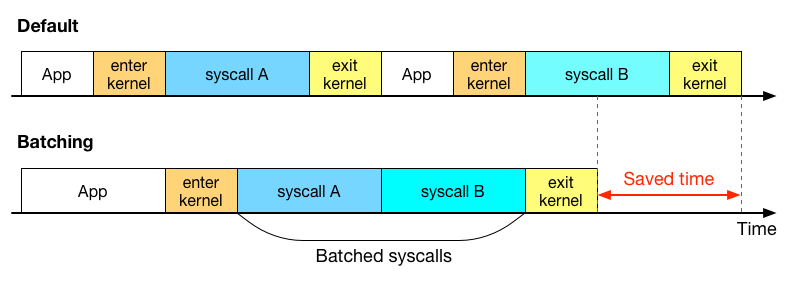
システムコールによるユーザー空間とカーネル空間の切り替えには、幾分かのコストを伴います。上の図のように、複数のシステムコールを、一度のカーネル空間へのコンテキスト切り替えで実行することにより、コンテキスト切り替えの頻度を低下させることができ、その分のコストを削減できます。
FlexSC の論文では、システムコールのコストがコンテキスト切り替えの時間だけでなく、キャッシュ汚染を引き起こし、処理性能低下につながると指摘しています。
CPU コア間のデータ共有を減らす
性能を向上するための方策の一つとして、利用する CPU のコアの数を増やす方法が考えられますが、ただ割り当てる CPU を増やすだけではパフォーマンスがスケールしないことが以下の論文で指摘されています。
- Improving Network Connection Locality on Multicore Systems (EuroSys'12)
- MegaPipe: A New Programming Interface for Scalable Network I/O (OSDI'12)
- Scalable Kernel TCP Design and Implementation for Short-Lived Connections (ASPLOS'16)
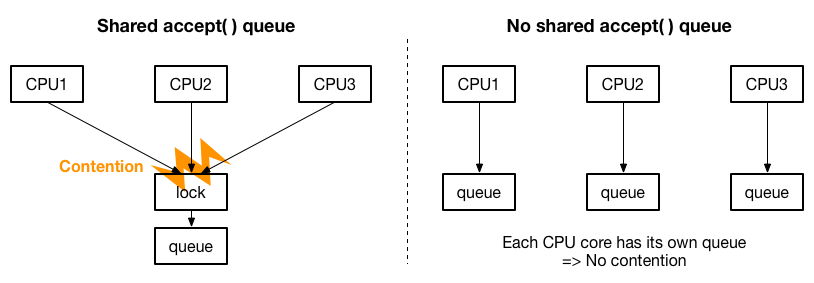
具体的には、マルチコアスケーラビリティの問題として、accept( ) のキューが一つしか存在しない場合、accept( ) の処理を複数 CPU に分散しても、キューのロックを取り合うことになり、CPU の増加に合わせた性能の向上が見込めないことが指摘されています。解決策として、以下の絵のように accept( ) のキューを CPU ごとに用意して、ロックの取り合いをなくすことが提案されています。
MegaPipe では、FlexSC と同じく、システムコールバッチングを可能にするネットワーク API を設計しています。
高速パケット I/O フレームワークを採用する
高速パケット I/O フレームワークは、OS カーネルのパケット I/O に関するコストを大きく引き下げることができることが示されたことにより、ネットワークスタックとのインテグレーションが試され、ネットワークスタックの性能向上にも大きな効果があることが報告されています。
- mTCP: A Highly Scalable User-level TCP Stack for Multicore Systems (NSDI'14)
- Rekindling Network Protocol Innovation with User-Level Stacks (CCR'14)
- Network Stack Specialization for Performance (SIGCOMM'14)
- StackMap: Low-Latency Networking with the OS Stack and Dedicated NICs (ATC'16)
- Seastar, High performance server-side application framework (From ScyllaDB/Cloudius Systems)
- OpenOnload (From Solarflare)
mTCP や Seastar では MegaPipe や Affinity-Accept と同じく CPU 間で共有されるデータを減らすように設計されており、マルチコアでスケールするように意識されています。また、バッチングも積極的に採用されています。
DPDK や netmap 等の高速パケット I/O フレームワークは、基本的に、ユーザー空間のアプリケーションからのパケット送受信を高速化するものであるため、これらのネットワークスタックの多くは、以下の絵のようにユーザー空間実装になっています。
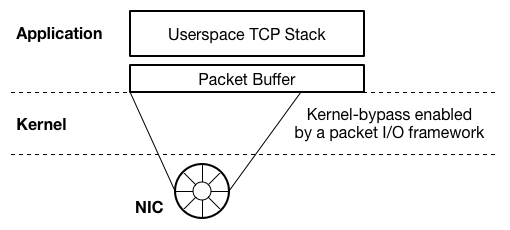
一方、StackMap の論文では、Windows, Linux, BSD 等の汎用 OS のネットワークスタック実装が、大きな開発者コミュニティを持ち、継続的に改善の努力が続けられていくことから、汎用 OS ネットワークスタックを高速することの重要性を指摘するとともに、Linux のネットワークスタックと高速パケット I/O フレームワークを組み合わせて性能を向上する方法を提案しています。
新しく OS を実装する
独自のネットワークスタックだけではなく、更なる高速化のために OS 自体を設計しなおすというアプローチも提案されています。
- Arrakis: The Operating System is the Control Plane (OSDI'14)
- IX: A Protected Dataplane Operating System for High Throughput and Low Latency (OSDI'14)
Arrakis の大きな特徴の一つは、Single Root I/O Virtualization (SR-IOV) を使って、アプリケーションが直接、仮想化された NIC へアクセスできるようにしています。IX では、OS のプロテクション機能を担保するために、Dune (OSDI'12) を利用しています。
上記の論文では、lwIP をベースにして、ネットワークスタックを実装しています。
まとめ
ネットワークスタックの高速化手法についてまとめました。それぞれの論文には、ここには書いていない高速化に関するテクニックや、パフォーマンスに関する分析が書いてありますので、是非原文を読んでみてください。