netmap を使ったアプリケーションで、パケットの送受信を行う方法について、netmap で利用されるデータ構造と一緒にまとめました。
netmap API を使ったプログラミング
netmap では socket と read( )/write( ) システムコールを使ったネットワーク通信が遅いという問題を解決するために、さらに効率の良い方法でアプリケーションからパケットを送受信できるようにしています。
その結果、高速なパケット I/O が実現される代わりに、これまで慣れ親しんだ socket ではなく、netmap 固有の API を使ってアプリケーションを書く必要があります。
このエントリーでは、netmap API を使ったプログラミングを GitHub に公開したサンプルアプリケーション*1を元に説明します。netmap のデフォルトの pkt-gen アプリケーションは、多くの機能が入っており、送受信の部分だけを理解する目的においては、見辛くなってしまうかと思い用意しました。
netmap 自体のインストール方法につきましては、過去のエントリー*2を参考にして頂ければと思います。
準備
- キャラクタデバイス /dev/netmap に対して open( ) システムコールを発行し、ファイルデスクリプタを取得する。
- 取得したファイルデスクリプタに、ioctl( ) システムコールを発行し、ネットワークインターフェースの登録を行う。
- 取得したファイルデスクリプタに、mmap( ) システムコールを発行し、アプリケーション空間に、カーネル空間との共有メモリを作成する。
これらの処理は煩雑ですが、実は、netmap/sys/net/netmap_user.h というヘッダファイルにラッパー関数が実装されており、アプリケーションでは、nm_open( ) という関数を呼び出すだけで、上記の処理を全て完了できます。
nm_open( ) の使い方は以下のようになります。
struct nm_desc *nmd = NULL; ... nmd = nm_open(ifname, NULL, 0, NULL);
nm_open( ) は、第一引数に生成するネットワークインターフェース名を取ります。引数の型は const char * で、具体的には、"vale0:foo" などのインターフェース名の文字列へのポインタとなります。
仮想インターフェースの生成をリクエストする場合には、インターフェース名が "仮想スイッチ名:インターフェース名" のフォーマットで指定される必要があることに注意が必要です。また、仮想スイッチ名は vale から始まる必要があります。
nm_open( ) の他の引数は、NULL と 0 を入れるだけで使えます。仮想インターフェースのリングの数を変更したい場合などには、これらの引数を変更することで、カーネルモジュールにリクエストをすることができます。
nm_open( ) の戻り値は、netmap/sys/net/netmap_user.h で定義されている nm_desc 構造体で、この構造体はアプリケーションが netmap を使ってパケットの送受信を行う際に必要な情報が格納されます。
アプリケーション側からの共有メモリ上オブジェクトへのアクセス
パケット送受信の準備が完了した後の共有メモリの状態は以下のようになります。
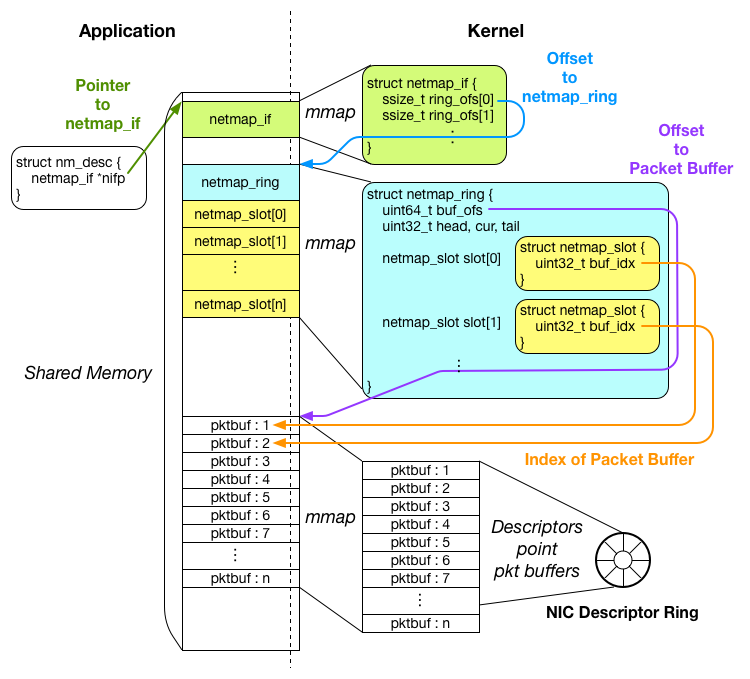
共有メモリのおかげで、アプリケーションはカーネルのメモリ空間内部のオブジェクトにアクセスできるようになりますが、正しくオブジェクトにアクセスするには、どのオブジェクトがどこにあるのかを知っている必要があります。
ですが、アプリケーションが mmap( ) システムコールを実行した際に得られるのは、戻り値として共有メモリの一番先頭のアドレスが返ってくるのみで、パケットバッファがどこにあるか等を知ることはできません。
そこで、netmap では、カーネルとアプリケーションで同じ構造体を共有し、アプリケーション側からオフセットをもとにしたオブジェクトへのアクセスを行えるようにします。
具体的には、netmap_if, netmap_ring, netmap_slot 構造体が共有されています。
netmap_user.h には以下のようなマクロが用意されており、これを使って、アプリケーションは共有メモリ上の netmap_ring やパケットバッファにアクセスしていきます。
#define _NETMAP_OFFSET(type, ptr, offset) \ ((type)(void *)((char *)(ptr) + (offset))) #define NETMAP_TXRING(nifp, index) _NETMAP_OFFSET(struct netmap_ring *, \ nifp, (nifp)->ring_ofs[index] ) #define NETMAP_BUF(ring, index) \ ((char *)(ring) + (ring)->buf_ofs + ((index)*(ring)->nr_buf_size))
まず、アプリケーションの準備の段階で得られた、nm_desc オブジェクトが、メンバ変数 nifp に、共有メモリ上の netmap_if オブジェクトへのポインタ(図中では緑色の矢印)を保持しています。
アプリケーションは、この nifp を起点に、各オブジェクトへのポインタを計算します。
netmap_if 構造体は、メンバ変数 ring_ofs に netmap_ring オブジェクトまでのオフセットを保持しています。
上のマクロの中で、NETMAP_TXRING を見てみてください。このマクロは転送用の netmap_ring へのポインタを取得するために利用されます。
このマクロによると、転送用の一つ目の netmap_ring は、nifp + ring_ofs[0] の場所に用意されています(図中では青い矢印)。ring_ofs が配列になっているのは、一つのインターフェースが複数のリングを保持できるようにするためです。
netmap_ring 構造体は、内部に netmap_slot 構造体の配列をメンバ変数として保持しています。ですので、netmap_slot へは、以下のようにアクセスできます。
struct netmap_ring *ring; struct netmap_slot *slot = &ring->slot[0];
パケットバッファは、それぞれ一意のインデックス番号を保持しており、それぞれの netmap_slot オブジェクトから、buf_idx というメンバ変数によって、インデックス番号をもとに参照されています。
マクロのリストの中にある、NETMAP_BUF を見てみてください。このマクロは以下のように、パケットバッファのポインタを得る際に利用されます。
struct char *pktbuf = NETMAP_BUF(ring, slot->buf_idx);
このマクロによれば、インデックス番号 N のパケットバッファは、「netmap_ring のあるアドレス」+「パケットバッファ開始位置までのオフセット:図中紫色の矢印」+「N × パケットバッファ一つの大きさ:図中オレンジの矢印」に位置しています。
以上のように、アプリケーション側からの各オブジェクトへのアクセスは、カーネル側が設定した各構造体に格納されるオフセットの値をもとに行われます。
パケット送信
パケット送信を行うには、アプリケーションは以下の処理を行う必要があります。
- パケットのデータを適切な位置のパケットバッファに書き込む。
- netmap_ring オブジェクトのメンバ変数 head, cur を更新する。
- インターフェースからのデータ送信をカーネル側へ ioctl( ) もしくは poll( ) システムコールを使ってリクエストする。
サンプルプログラムの中では transmit_packets( ) という関数に送信の部分が実装されています。
1. 適切なパケットバッファへのデータ書き込み
データ書き込みを行うべきパケットバッファの位置は、nm_desc オブジェクトの nifp メンバ変数から辿ります。まず、転送用 netmap_ring のポインタを取得します。
struct netmap_ring *tx_ring; // nmd は nm_desc 構造体、引数 0 は一つ目の転送用リングのアドレスを取得するために指定 tx_ring = NETMAP_TXRING(nmd->nifp, 0);
次に、目的のパケットバッファを参照している netmap_slot オブジェクトを取得します。
netmap_ring は、以下のように netmap_slot をリング状にまとめており、各 netmap_slot がインデックス番号 ( buf_idx ) で参照しているパケットバッファのデータが順番に転送されていきます。
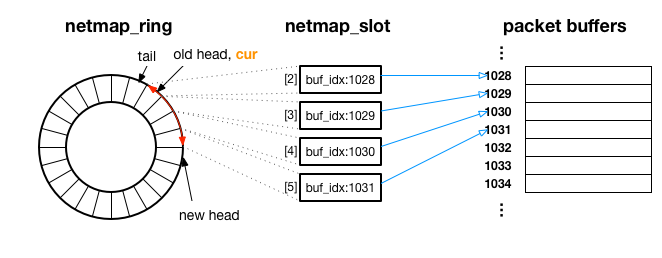
次にどの netmap_slot が参照しているパケットバッファのデータが転送されるか、という情報は、netmap_ring 構造体の cur メンバ変数(図中オレンジ)が保持しています。
cur は netmap_ring 構造体が保持する netmap_slot 配列のインデックスとして利用します。具体的には、以下のようにすることで、次に書き込むべきパケットバッファを参照している netmap_slot のアドレスを取得できます。
j = tx_ring->cur;
...
struct netmap_slot *slot = &tx_ring->slot[j];
これで、次に書き込むべきパケットバッファのインデックスを知ることができます。以下のようにすることで、変数 txbuf に、転送パケットの書き込み先のアドレスが取得できます。
char *txbuf = NETMAP_BUF(tx_ring, slot->buf_idx);
書き込み先がわかったので、データを書き込みます。netmap ではパケットバッファ上のデータがそのまま送信されるため、イーサーネットや IP、UDP ヘッダもアプリケーションで用意します。サンプルプログラムの中では、make_packet という関数の中でヘッダをつける処理をしています。
パケットの準備が完了したら、netmap_slot オブジェクトのメンバ変数 len に、パケットのデータの長さを代入します。
/* Make a ethernet packet * - Prepare ether, IP and UDP headers * - Copy payload into the packet buffer */ pkt_len = make_packet(txbuf, payload, strlen(payload)); ... /* Set packet length to slot->len */ slot->len = pkt_len;
以上で、パケット1つ分の用意が完了しました。続けて次のパケットを用意する場合には、以下のようにして、次の netmap_slot の配列内でのインデックスを取得して、ここまでと同じ処理を繰り返していきます。
// j には、次の netmap_slot の配列内でのインデックスが入ります j = nm_ring_next(tx_ring, j);
2. netmap_ring の head, cur のアップデート
アプリケーション側で、ペイロードの書き込みが完了しましたが、次は逆にアプリケーションが、どこまでペイロードを書き込んだかをカーネル側に伝える必要があります。
この情報のカーネル側への引渡しは、アプリケーション側でデータ書き込みが完了したスロットの最後尾の netmap_slot のインデックスを、netmap_ring 構造体のメンバ変数 head, cur に代入することで行います。プログラムは以下のようになります。
/* Upadte head and cur indexes of netmap_ring */
tx_ring->head = tx_ring->cur = j;
カーネルは、netmap_ring の head の値を見て、tail から head にかけてのパケットを送信します。
上の図は、netmap_ring のメンバ変数 head が old head から、new head にアップデートされた例で、赤い矢印の部分の netmap_slot が参照しているパケットバッファ(インデックス 1028 ~ 1031 まで)が、カーネル内の処理によって転送されます。
3. カーネル側へデータ発信リクエストを送る
ペイロードの書き込みが完了し、カーネル側へ転送してほしいペイロードの場所を伝える準備もできました。
いよいよシステムコールを発行して、カーネル空間へ移り、データ転送の処理を行います。カーネルに転送をリクエストするには、ioctl( ) もしくは poll( ) システムコールが使えます。
以下のようにすると、これまで用意してきたパケットが実際に送信されます。
/* Packets will be transmitted in this ioctl syscall */ // nmd は nm_desc 構造体、NIOCTXSYNC は転送リクエストです ioctl(nmd->fd, NIOCTXSYNC, NULL);
パケット受信
受信側は以下の処理の繰り返しになります。
- パケット受信を poll( ) システムコールで待つ。
- 届いたデータを読む。
- netmap_ring オブジェクトのメンバ変数 head, cur を更新する。
1. poll( ) システムコールによる受信待機
アプリケーションはパケットの受信を poll( ) システムコールを使って待つことができます。サンプルプログラムでは、以下のようにして、poll( ) システムコールを使っています。
// nmd は nm_desc 構造体 struct pollfd pfd = { .fd = nmd->fd, .events = POLLIN }; while (!do_abort) { ... ret = poll(&pfd, 1, 1000); ... receive_packets(nmd); }
パケットが届く、もしくは設定したタイムアウト(上の例では1秒間)した場合に、poll( ) システムコールから処理がアプリケーションへ戻ってきます。poll( ) の中で待機している間は、CPU リソースを手放すことができるので、ビジーループを作らず、CPU リーソス的に、電力的に効率がよくなります。
インターフェースがパケットを受信した場合、poll( ) システムコールは、受信したパケットの最後尾まで、受信用 netmap_ring の tail が更新されます。これは、アプリケーションに、netmap_ring の head から、更新された tail までのデータがアプリケーション側から読み込み可能であることを伝えるために行われます。
2. 受信したデータの読み取り
アプリケーション内部でのパケットの受信処理は、サンプルでは receive_packets 関数に実装されています。
データの読み取りに関してのポイントは、どこにデータが届いたかを知ることですが、これは転送の場合と同じ要領で行えます。以下のプログラムでは、変数 rxbuf に受信したデータの先頭のアドレスが代入されます。
struct netmap_ring *rx_ring; unsigned int j, n; // NETMAP_RXRING マクロを使って受信用 netmap_ring のアドレスを取得 rx_ring = NETMAP_RXRING(nmd->nifp, 0); j = rx_ring->cur; ... while (n-- > 0) { // 読み込むべきパケットバッファを参照している netmap_slot を取得 struct netmap_slot *slot = &rx_ring->slot[j]; // netmap_slot の buf_idx をもとに、受信データがあるパケットバッファのアドレスを取得 char *rxbuf = NETMAP_BUF(rx_ring, slot->buf_idx); ...
次に、ペイロードの位置を取得します。アプリケーションからは、イーサーネットヘッダや IP ヘッダを含むパケットの全体像が見えており、また rxbuf はパケットの先頭のアドレスを指しているため、ペイロード自体のアドレスを得るには、これらのヘッダのオフセットを足す必要があります。
サンプルの送信側では、UDP ヘッダを追加しているため、イーサネット、IP、UDP ヘッダの合計サイズを rxbuf から進めたところが今回のサンプルコードで受信されるペイロードの位置になります。プログラムで書くと以下のようになります。
char *payload = (char *)((unsigned long) rxbuf + sizeof(struct ether_header) + sizeof(struct ip) + sizeof(struct udphdr));
やっと受信したペイロードに辿り着けました。NF アプリケーション等を作る際には、このデータに対して処理を行っていくことになると思います。
nm_ring_space(rx_ring) で受信されたパケットの個数がわかりますので、以下のように nm_ring_next( ) 関数でスロットを進めて同じ処理を続けていくと、全ての受信したデータに対して読み込み処理を行えます。
n = nm_ring_space(rx_ring); while (n-- > 0) { struct netmap_slot *slot = &rx_ring->slot[j]; ... j = nm_ring_next(rx_ring, j); }
3. 受信用 netmap_ring の head, cur を更新
最後に、アプリケーション側から、カーネル側へ、どこまでデータを読み終えたかを伝えるために、受信用 netmap_ring の head, cur をアップデートします。これにより、カーネルは、新しく届くパケットのデータを head の位置まで上書きしてよいことを知ることができます。逆に、head の位置を更新しなければ、head 以降が新しいデータで上書きされません。
/* Upadte head and cur indexes of netmap_ring */
rx_ring->head = rx_ring->cur = j;
上記の処理を行ったら、また最初の poll( ) で待機を行うループへ戻ってきます。poll( ) システムコールでは、新しくアップデートされた head の位置をカーネル内に反映する処理を行った後、次のパケットが届くまで、再度待機を継続します。