ネットワークスタック高速化手法まとめ
ネットワークスタックの高速化手法についてまとめました。
これらの手法が提案された背景には、10Gb NIC 等の高性能なハードウェアの値段が下がり、汎用化が進んだ一方で、汎用 OS のネットワークスタック実装では、それらの性能を十分引き出せないという問題があります。
特に、小さいパケットをやりとりするワークロードや、短い TCP コネクションをたくさん処理するようなワークロードで、10Gb, 40Gb のラインレートを達成するのが難しく、様々な解決策が提案されています。
システムコールバッチング
システムコールは、ユーザー空間とカーネル空間のコンテキスト切り替えのための処理を必要とし、Web サーバーやキャッシュサーバー等の高速なメッセージの送受信が必要なシステムにおいて、性能劣化の原因となることが問題として指摘されています。
以下の論文では、システムコールバッチングをこの問題の解決策として提案しています。複数システムコールをまとめて実行することで、コンテキスト切り替え時に発生するコストをまとめることができ、性能を向上できると報告されています。
システムコールをバッチすると、どのようないいことがあるのかを絵に描いてみました。
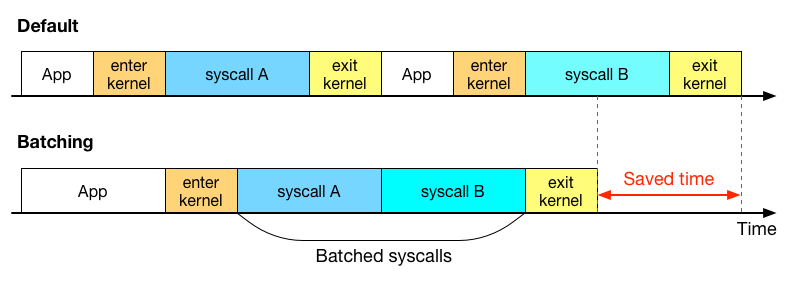
システムコールによるユーザー空間とカーネル空間の切り替えには、幾分かのコストを伴います。上の図のように、複数のシステムコールを、一度のカーネル空間へのコンテキスト切り替えで実行することにより、コンテキスト切り替えの頻度を低下させることができ、その分のコストを削減できます。
FlexSC の論文では、システムコールのコストがコンテキスト切り替えの時間だけでなく、キャッシュ汚染を引き起こし、処理性能低下につながると指摘しています。
CPU コア間のデータ共有を減らす
性能を向上するための方策の一つとして、利用する CPU のコアの数を増やす方法が考えられますが、ただ割り当てる CPU を増やすだけではパフォーマンスがスケールしないことが以下の論文で指摘されています。
- Improving Network Connection Locality on Multicore Systems (EuroSys'12)
- MegaPipe: A New Programming Interface for Scalable Network I/O (OSDI'12)
- Scalable Kernel TCP Design and Implementation for Short-Lived Connections (ASPLOS'16)
具体的には、マルチコアスケーラビリティの問題として、accept( ) のキューが一つしか存在しない場合、accept( ) の処理を複数 CPU に分散しても、キューのロックを取り合うことになり、CPU の増加に合わせた性能の向上が見込めないことが指摘されています。解決策として、以下の絵のように accept( ) のキューを CPU ごとに用意して、ロックの取り合いをなくすことが提案されています。
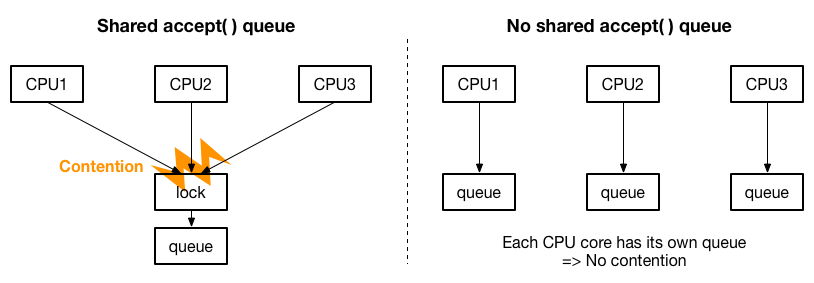
MegaPipe では、FlexSC と同じく、システムコールバッチングを可能にするネットワーク API を設計しています。
高速パケット I/O フレームワークを採用する
高速パケット I/O フレームワークは、OS カーネルのパケット I/O に関するコストを大きく引き下げることができることが示されたことにより、ネットワークスタックとのインテグレーションが試され、ネットワークスタックの性能向上にも大きな効果があることが報告されています。
- mTCP: A Highly Scalable User-level TCP Stack for Multicore Systems (NSDI'14)
- Rekindling Network Protocol Innovation with User-Level Stacks (CCR'14)
- Network Stack Specialization for Performance (SIGCOMM'14)
- StackMap: Low-Latency Networking with the OS Stack and Dedicated NICs (ATC'16)
- Seastar, High performance server-side application framework (From ScyllaDB/Cloudius Systems)
- OpenOnload (From Solarflare)
mTCP や Seastar では MegaPipe や Affinity-Accept と同じく CPU 間で共有されるデータを減らすように設計されており、マルチコアでスケールするように意識されています。また、バッチングも積極的に採用されています。
DPDK や netmap 等の高速パケット I/O フレームワークは、基本的に、ユーザー空間のアプリケーションからのパケット送受信を高速化するものであるため、これらのネットワークスタックの多くは、以下の絵のようにユーザー空間実装になっています。
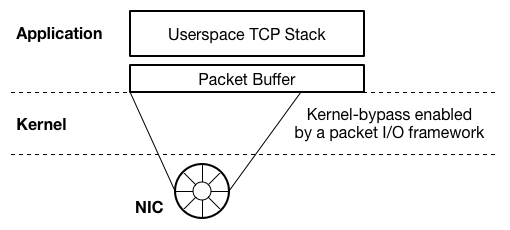
一方、StackMap の論文では、Windows, Linux, BSD 等の汎用 OS のネットワークスタック実装が、大きな開発者コミュニティを持ち、継続的に改善の努力が続けられていくことから、汎用 OS ネットワークスタックを高速することの重要性を指摘するとともに、Linux のネットワークスタックと高速パケット I/O フレームワークを組み合わせて性能を向上する方法を提案しています。
新しく OS を実装する
独自のネットワークスタックだけではなく、更なる高速化のために OS 自体を設計しなおすというアプローチも提案されています。
- Arrakis: The Operating System is the Control Plane (OSDI'14)
- IX: A Protected Dataplane Operating System for High Throughput and Low Latency (OSDI'14)
Arrakis の大きな特徴の一つは、Single Root I/O Virtualization (SR-IOV) を使って、アプリケーションが直接、仮想化された NIC へアクセスできるようにしています。IX では、OS のプロテクション機能を担保するために、Dune (OSDI'12) を利用しています。
上記の論文では、lwIP をベースにして、ネットワークスタックを実装しています。
まとめ
ネットワークスタックの高速化手法についてまとめました。それぞれの論文には、ここには書いていない高速化に関するテクニックや、パフォーマンスに関する分析が書いてありますので、是非原文を読んでみてください。
高速パケット I/O フレームワークの NIC の I/O について
netmap のようなパケット I/O フレームワークが、どのように NIC からパケット転送を行っているのかについてまとめました。
以前のエントリー*1で、Intel NIC でパケットを転送するために、デバイスドライバがどのような処理をしているのかを見ました。
今回は、netmap が、それらのデバイスドライバをハックして、データ転送部分だけを切り出して使っている実装について見ていきます。
netmap のパケット転送
netmap を使ってパケットを送信する際には、以下の図のように、大きく3つのステップで行います。過去のエントリーにも説明がありますので、そちらも参考にしてください。
以前のエントリー*2は、最初の2つの項目について説明しています。今回は3つ目についての説明で、カーネルがデバイスドライバを経由して、NIC に転送のリクエストを送る部分を見ます。
netmap の NIC の転送部分の実装
下記の実装は、e1000e ドライバを利用する NIC 用で、netmap/LINUX/if_e1000e_netmap.h にあります。これと同じ類の実装が、それぞれの NIC ごとにあります。
以下の関数 e1000_netmap_txsync へは、図の赤い矢印(Request I/O)の先で、たどり着きます。
過去のエントリーでは、netmap_ring、netmap_slot 等の netmap のデータ構造について*3と、NIC のデスクリプタリングや、E1000_TX_DESC 等のマクロについて*4書いてありますので、参考にしてください。
/* * Reconcile kernel and user view of the transmit ring. */ static int e1000_netmap_txsync(struct netmap_kring *kring, int flags) { ... struct netmap_ring *ring = kring->ring; ... /* device-specific */ // SOFTC_T は e1000_adapter のマクロ struct SOFTC_T *adapter = netdev_priv(ifp); // e1000_ring : 転送用デスクリプタリングの構造体 struct e1000_ring* txr = &adapter->tx_ring[ring_nr]; ... if (nm_i != head) { /* we have new packets to send */ nic_i = netmap_idx_k2n(kring, nm_i); for (n = 0; nm_i != head; n++) { // パケットバッファのアドレスと、データ長の情報を持つスロットを取得 struct netmap_slot *slot = &ring->slot[nm_i]; u_int len = slot->len; uint64_t paddr; // paddr に netmap_slot が参照するパケットバッファの物理アドレスが格納される void *addr = PNMB(na, slot, &paddr); /* device-specific */ // 転送用デスクリプタを E1000_TX_DESC マクロで取得 struct e1000_tx_desc *curr = E1000_TX_DESC(*txr, nic_i); int flags = (slot->flags & NS_REPORT || nic_i == 0 || nic_i == report_frequency) ? E1000_TXD_CMD_RS : 0; NM_CHECK_ADDR_LEN(na, addr, len); /* 既に、この段階ではデスクリプタの Buffer Address フィールドは、 パケットバッファを参照していますが、 slot->flags に NS_BUF_CHANGED というフラグを立てると、 デスクリプタが参照しているパケットバッファを変更することができます。*/ if (slot->flags & NS_BUF_CHANGED) { ... // デスクリプタの Buffer Address フィールドが参照しているアドレスを変更 curr->buffer_addr = htole64(paddr); } ... /* Fill the slot in the NIC ring. */ curr->upper.data = 0; // デスクリプタの Length フィールドに送信するデータの長さを設定 curr->lower.data = htole32(adapter->txd_cmd | len | flags | E1000_TXD_CMD_EOP); nm_i = nm_next(nm_i, lim); nic_i = nm_next(nic_i, lim); // 次の netmap_slot の保持する値を、次の転送デスクリプタに反映する /* アプリケーションが用意したデータ全てに処理が完了する、もしくは 転送デスクリプタを全て使い切るまで続ける */ } ... /* NIC に転送用データの準備が完了したことを伝える。 TDT レジスタの値を変更し、データ転送をリクエストする。*/ NM_WR_TX_TAIL(nic_i); ... } ... return 0; }
NIC からデータを送信するためには、デスクリプタのフィールドにパケットデータのアドレスとパケット長を指定し、TDT レジスタの値を更新することが必要で、上の e1000_netmap_txsync 関数では、まさにそれを行っています。
以下が、上記のプログラムの中で、パケットデータアドレスを設定する箇所です。
curr->buffer_addr = htole64(paddr);
以下が、データの長さを設定するところです。
curr->lower.data = htole32(adapter->txd_cmd | len | flags |
E1000_TXD_CMD_EOP);
NM_WR_TX_TAIL は以下のようになっていて、TDT レジスタの値を更新をします。
#define NM_WR_TX_TAIL(_x) writel(_x, txr->tail)
NIC からデータを発信するために重要なのは、以上の3点です。
これらを踏まえて、netmap と、NIC のデータ構造の結びつきを図示すると以下のようになります。
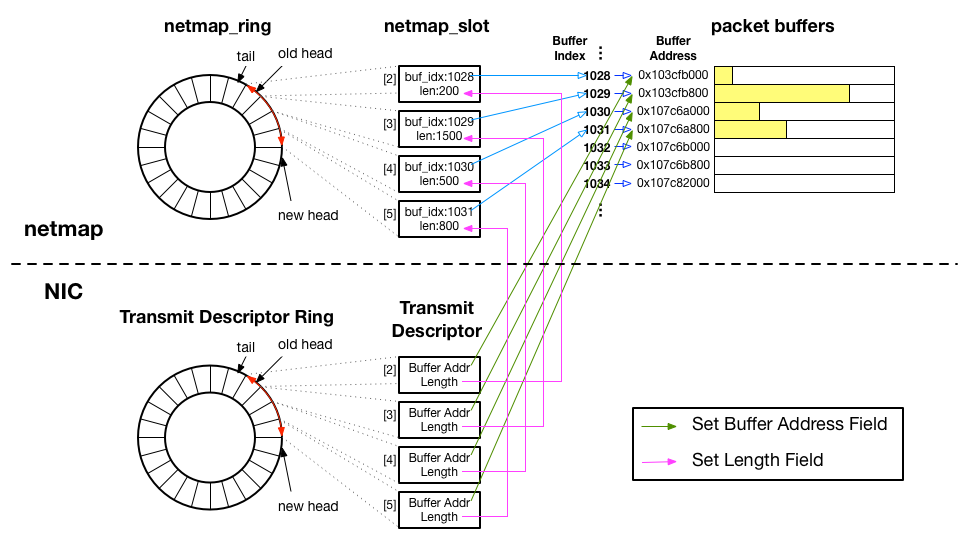
netmap_slot と、NIC の Transmit Descriptor は、どちらも同じくパケットバッファの位置( netmap_slot : buf_idx, Transmit Descriptor : Buffer Address )と、パケットデータの長さを保持するフィールド( netmap_slot : len, Transmit Descriptor : Length )を持っており、それらはリング状にして、netmap_ring と Transmit Descriptor Ring という構造で管理されています。
まとめ
Intel NIC ドライバにおけるパケット送信について
Linux の NIC のデバイスドライバが、どのようにデータを送信するのかについてまとめました。特に Intel NIC のドライバについて見ていきます。
Intel の 1Gb NIC のデータシートが次の URL *1 で見つかりますので、それも参考にしながら見ていただければと思います。。
ソースコード
Intel NIC のデバイスドライバのコードは、Linux のソースコード内で、以下のディレクトリに配置されています。
- 1Gb NIC e1000 : linux/drivers/net/ethernet/intel/e1000
- 1Gb NIC e1000e : linux/drivers/net/ethernet/intel/e1000e
- 10Gb NIC ixgbe : linux/drivers/net/ethernet/intel/ixgbe
- 40Gb NIC i40e : linux/drivers/net/ethernet/intel/i40e
今回は、e1000e を例に見ていきますが、重要なデータ構造は ixgbe, i40e にも共通しており、それぞれについても概ね同じ処理を行うことでデータの送信ができます。
NIC のデータ構造
データの送受信を行う場合の重要な構造体として、デスクリプタのリングがあります。これはハードウェアの仕様によるものです。デバイスドライバは、このデスクリプタリングを適切に扱うことで、データの送受信を行います。
データシートの 7.2.4 章に Transmit Descriptor Ring Structure というタイトルで転送用デスクリプタリングの構造の説明があります。また、転送用デスクリプタの各フィールドの説明が、データシートの 7.2.10 章に見つかります。
以下の図に、それらの情報をまとめます。
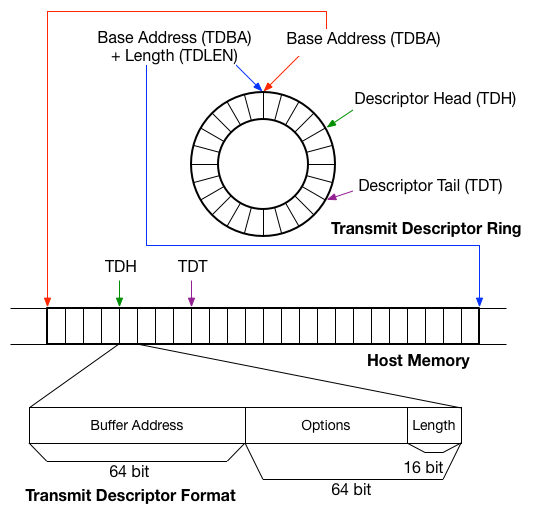
データシートによると、転送用デスクリプタリングは、4種類のレジスタによって表現されるとあります。
- Transmit Descriptor Base Address register ( TDBA ) : ホストメモリ上での、デスクリプタリングの開始位置を指定する。
- Transmit Descriptor Length register ( TDLEN ) : リングのために確保されているメモリの長さを指定する。
- Transmit Descriptor Head register ( TDH ) : NIC によって処理されるべきデスクリプタの開始位置を示す。
- Transmit Descriptor Tail register ( TDT ) : NIC が処理すべき最後のデスクリプタの位置を示す。
デスクリプタリングは NIC のレジスタによって表現されますが、デバイスドライバからは、直線的なメモリ領域の上にデスクリプタの構造体の配列が配置されているように見え、配列のインデックスをもとに各デスクリプタのフィールドへアクセスします。
NIC レジスタへのアクセス方法
デスクリプタリングを準備する際には、NIC のレジスタ、(TDBA, TDLEN, TDH, TDT)へ適切に値を入れていく必要があります。これらのレジスタは、デバイスドライバの初期化の段階でホストメモリにマップされており、データシートに記載されているオフセットを頼りにアクセスします。
データシートの 10.2.1 章 Register Summary Table の Table 83 には、NIC のレジスタのリストが掲載されており、ホストメモリにマップされた先頭のアドレスから、各レジスタへのオフセットが記載されています。
このテーブルによると、転送に関連する4種類のレジスタ TDBA、TDLEN、TDH、TDT は次のオフセットでアクセスできるようです。
- TDBAL ( Transmit Descriptor Base Address Low ) : 0x03800
- TDBAH ( Transmit Descriptor Base Address High ) : 0x03804
- TDLEN ( Transmit Descriptor Length ) : 0x03808
- TDH ( Transmit Descriptor Head ) : 0x03810
- TDT ( Transmit Descriptor Tail ) : 0x03818
次にデバイスドライバのコードの e1000e/reg.h を見てみます。
#define E1000_TDBAL(_n) ((_n) < 4 ? (0x03800 + ((_n) * 0x100)) : \ (0x0E000 + ((_n) * 0x40))) #define E1000_TDBAH(_n) ((_n) < 4 ? (0x03804 + ((_n) * 0x100)) : \ (0x0E004 + ((_n) * 0x40))) #define E1000_TDLEN(_n) ((_n) < 4 ? (0x03808 + ((_n) * 0x100)) : \ (0x0E008 + ((_n) * 0x40))) #define E1000_TDH(_n) ((_n) < 4 ? (0x03810 + ((_n) * 0x100)) : \ (0x0E010 + ((_n) * 0x40))) #define E1000_TDT(_n) ((_n) < 4 ? (0x03818 + ((_n) * 0x100)) : \ (0x0E018 + ((_n) * 0x40)))
?マークは三項演算子と呼ばれるもので、" 条件 ? True の場合 : False の場合 "のような形式でプログラムを書くことができます。
この場合では、_n が 4 より小さければ、: の左側の値、_n が 4 以上なら、: の右の値が適用されます。e1000e のドライバでは常に _n に0を入れて利用されているので、常に左の値が適用されます。
プログラム内で宣言されている値 0x038XX が、データシートに掲載されているオフセットの値と対応していることがわかります。
レジスタへの値の書き込みは、以下のような関数で行われます。e1000_hw->hw_addr には、ホストメモリにマップされているレジスタの先頭のアドレスが、ドライバ初期化の際に代入されており、それに対して各レジスタのオフセットを足したアドレスへ値を書き込んでいきます。
/* e1000e/netdev.c */ void __ew32(struct e1000_hw *hw, unsigned long reg, u32 val) { ... writel(val, hw->hw_addr + reg); }
/* e1000e/e1000.h */ #define ew32(reg, val) __ew32(hw, E1000_##reg, (val))
例えば、上記のマクロを使って以下のようにプログラムを書くと、TDH レジスタに 0 が書き込まれます。このときに、E1000_##reg は E1000_TDH(0) に展開され 0x03810 がオフセットの値として、__ew32 関数の unsigned long reg の引数として渡されます。
ew32(TDH(0), 0);
転送用デスクリプタリングの初期化は、e1000e/netdev.c では、上記のマクロを使って、e1000_configure_tx 関数に以下のように実装されています。
/** * e1000_configure_tx - Configure Transmit Unit after Reset * @adapter: board private structure * * Configure the Tx unit of the MAC after a reset. **/ static void e1000_configure_tx(struct e1000_adapter *adapter) { struct e1000_hw *hw = &adapter->hw; struct e1000_ring *tx_ring = adapter->tx_ring; u64 tdba; u32 tdlen, tctl, tarc; /* Setup the HW Tx Head and Tail descriptor pointers */ tdba = tx_ring->dma; tdlen = tx_ring->count * sizeof(struct e1000_tx_desc); ew32(TDBAL(0), (tdba & DMA_BIT_MASK(32))); ew32(TDBAH(0), (tdba >> 32)); ew32(TDLEN(0), tdlen); ew32(TDH(0), 0); ew32(TDT(0), 0); tx_ring->head = adapter->hw.hw_addr + E1000_TDH(0); tx_ring->tail = adapter->hw.hw_addr + E1000_TDT(0); ...
上記のプログラムでは、TDBA (デスクリプタリング開始位置指定用レジスタ)には、tx_ring->dma の値が書き込まれています。tx_ring->dma は、以下の関数、e1000_alloc_ring_dma でデスクリプタリング用に確保したメモリ領域の先頭アドレスが格納されています。
また、tx_ring->dma に格納される値は物理メモリアドレスで、tx_ring->desc には同じ領域を参照する仮想メモリアドレスが格納されます。NIC のレジスタへアドレスを指定する際は、物理メモリアドレス(tx_ring->dma)で指定し、デバイスドライバのカーネルモジュールのプログラムからデスクリプタを参照する場合には、仮想メモリアドレス(tx_ring->desc)をもとに参照します。
/** * e1000_alloc_ring_dma - allocate memory for a ring structure **/ static int e1000_alloc_ring_dma(struct e1000_adapter *adapter, struct e1000_ring *ring) { ... ring->desc = dma_alloc_coherent(pci_dev_to_dev(pdev), ring->size, &ring->dma, GFP_KERNEL);
デスクリプタのフィールド
データシートの転送用デスクリプタのフィールドの説明を見ていきます。データの送受信について特に重要なのが以下の2項目です。
- 7.2.10.1.1 章 Buffer Address : Buffer Address は、メインメモリ上の転送すべきデータの位置(アドレス)を指定します。
- 7.2.10.1.2 章 Length : Length は、Buffer Address で指定したアドレスから転送されるべきデータの長さをバイト単位で指定します。
Buffer Address のフィールドに転送したいデータのメインメモリ上のアドレス、Length に転送したいデータの長さを指定します。
デスクリプタへのアクセス
Intel の 1Gb NIC ドライバ e1000e では、転送デスクリプタを e1000e/hw.h 内部で以下のような構造体として定義しています。
/* Transmit Descriptor */ struct e1000_tx_desc { __le64 buffer_addr; /* Address of the descriptor's data buffer */ union { __le32 data; struct { __le16 length; /* Data buffer length */ u8 cso; /* Checksum offset */ u8 cmd; /* Descriptor control */ } flags; } lower; union { __le32 data; struct { u8 status; /* Descriptor status */ u8 css; /* Checksum start */ __le16 special; } fields; } upper; };
ある転送デスクリプタリングの、i 番目の転送デスクリプタへアクセスするためには、e1000.h で定義されている、以下の E1000_TX_DESC マクロを利用します。ここで、R には struct e1000_ring が入り、E1000_GET_DESC は (&(((struct e1000_tx_desc *)(tx_ring.desc))[i])) のように展開されます。
前述の通り、tx_ring.desc には、転送用デスクリプタリングの開始位置の仮想メモリアドレスが入っており、このマクロでは i 番目の struct e1000_tx_desc の配列のオブジェクトへのアドレスが得られます。
#define E1000_GET_DESC(R, i, type) (&(((struct type *)((R).desc))[i])) #define E1000_TX_DESC(R, i) E1000_GET_DESC(R, i, e1000_tx_desc)
パケットの転送
1. デスクリプタのフィールドへ、Buffer Address と Length を指定する
e1000e では、以下の関数 e1000_tx_queue に実装されています。
static void e1000_tx_queue(struct e1000_ring *tx_ring, int tx_flags, int count) { ... do { buffer_info = &tx_ring->buffer_info[i]; tx_desc = E1000_TX_DESC(*tx_ring, i); // マクロを利用して i 番目のデスクリプタへの参照を得る tx_desc->buffer_addr = cpu_to_le64(buffer_info->dma); // Buffer Address フィールドへパケットのデータのアドレスを書き込む tx_desc->lower.data = cpu_to_le32(txd_lower | // Length フィールドへパケットの長さを書き込む buffer_info->length); tx_desc->upper.data = cpu_to_le32(txd_upper); i++; if (i == tx_ring->count) i = 0; } while (--count > 0);
上記の e1000_tx_queue 関数で、Buffer Address に指定している値、buffer_info->dma には、上記の処理にたどり着く前に、以下の関数 e1000_tx_map の中で、パケットデータの仮想アドレス(skb->data + offset)が参照する物理メモリアドレスが格納されています。
static int e1000_tx_map(struct e1000_ring *tx_ring, struct sk_buff *skb, unsigned int first, unsigned int max_per_txd, unsigned int nr_frags) { ... buffer_info->length = size; ... buffer_info->dma = dma_map_single(pci_dev_to_dev(pdev), skb->data + offset, size, DMA_TO_DEVICE);
2. TDT レジスタ(NIC が処理すべき最後のデスクリプタを示す)の値を更新して、NIC に転送すべきパケットが用意されたことを伝える
先ほどと同じ関数 e1000_tx_map の中で、以下のようにして実装されています。
static int e1000_tx_map(struct e1000_ring *tx_ring, struct sk_buff *skb, unsigned int first, unsigned int max_per_txd, unsigned int nr_frags) { ... writel(i, tx_ring->tail);
i には、転送されるべきデータを参照する最後尾の転送デスクリプタのインデックスが代入されています。これにより、NIC は、TDH から、新しく i が設定された TDT までのインデックスをもつ転送デスクリプタが Buffer Address のフィールドで参照しているパケットのデータを転送します。
tx_ring->tail は、転送用デスクリプタリングを設定する関数 e1000_configure_tx の中で、以下のようにして、NIC の TDT レジスタがマップされたアドレスが代入されています。
static void e1000_configure_tx(struct e1000_adapter *adapter) { ... tx_ring->tail = adapter->hw.hw_addr + E1000_TDT(0);
まとめ
netmap でわかる Linux カーネルハック入門
以前のエントリー*1で、netmap API を使ったアプリケーションを作成する方法やデータ構造についてとりあげました。今回は少しレイヤーを下げて、カーネルのどのような機能を使って、netmap API が作られているのかについてまとめました。
Linux カーネルハックを始めてみたいけれど、何から手をつければよいかわからないという方にとって、netmap で使われているカーネルハックの方法について知ることは、とても良い導入の一つだと思います。
Linux カーネルハック
netmap は、キャラクタデバイスのカーネルモジュールとして実装されています。今回はキャラクタデバイスのカーネルモジュールで何ができるのか、ということと、netmap がそれらをどのように使っているかについて説明します。
カーネルハックで、Linux カーネルに新しい機能を追加する場合に、カーネルのソースコードを直接変更することもできますが、カーネルのコードを直接変更した場合は、カーネル自体をコンパイルした後、コンピューターの再起動をしてカーネルをロードし直す必要があります。特にカーネルのコンパイルは、ソースコードの量がとても多いので、ラップトップ等のパソコンで行うと30分から1時間前後の時間がかかってしまいます。
一方、カーネルモジュールであれば、ロードのためにコンピューターの再起動が不要で、コンパイルの時間も短いため、比較的手軽に開発が行えます。
netmap を実現するのに必要な実装
まず、netmap の完成形の状態を確認して、netmap の機能を実現するために、どのような実装が必要であるかを見ていきます。
以前のエントリーで、netmap のアプリケーションの使い方*2や、アプリケーション側から見えるデータ構造*3についてまとめましたので、そちらも参考にしてください。
以下に、netmap がパケットを転送する際の処理の流れを示します。
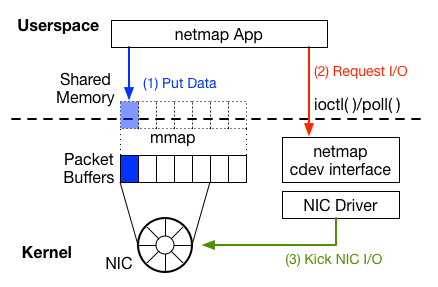
最初の構成として、カーネル空間に用意されたパケットバッファが、アプリケーションのメモリ空間にマップされ、共有メモリが作成されています。まず、パケットバッファを用意するために、①あるアプリケーションが、カーネルにメモリ確保をリクエストできる機能が必要です。また、②そのメモリをカーネルとアプリケーションの間での共有メモリとして利用できる機能が実装されている必要があることがわかります。
アプリケーションがパケットを送信するには、共有メモリ上のパケットバッファにデータを直接書き込んだ後(図中では青い矢印)、アプリケーションは、データ送信のリクエストをカーネルに送ります(赤い矢印)。③この段階で必要になるのが、アプリケーションから、カーネルへデータ送信リクエストを行う手段です。
netmap カーネルモジュールは、アプリケーションからリクエストを受け取った後、NIC のドライバを通じて、データの転送を行います(緑色の矢印)。
ここまで見てきたことから、この一連の流れを実現するためには、少なくとも、アプリケーションとカーネルの連携手段として、以下の3つの機能が必要であることがわかります。
キャラクタデバイスのカーネルモジュールは、上記の3つを実装できる機能を備えています。
1つ目と、3番目、カーネル空間でのメモリ確保のリクエスト、データ送信のリクエストの2つについては、キャラクタデバイスから取得されたファイルデスクリプタに対して ioctl( ) システムコールを発行することで行います。2つ目、共有メモリの作成については、キャラクタデバイスと mmap( ) システムコールの組み合わせで実現できます。
キャラクタデバイスのサンプルプログラム
実際にプログラムを見ていただくのが早いと思ったので、GitHub にサンプルコード*4を用意しました。
サンプルプログラムは以下のようにしてコンパイルしてください。
$ git clone https://github.com/yasukata/kernel_module_cdev_template.git $ cd kernel_module_cdev_template $ make
kmod.ko という名前のファイルができていれば成功です。これがカーネルモジュールのファイルです。このカーネルモジュールを以下のコマンドでカーネルにインストールしてみてください。
$ insmod kmod.ko
これで、このカーネルモジュールに実装された機能がカーネルに追加されました。
カーネルの機能を確認するには、アプリケーションから、その機能にアクセスして試して見る必要があります。app という名前のディレクトリ以下に、動作を確認するためのアプリケーションが入っています。以下のようにしてビルドしてみてください。
$ cd app $ make
kmod-test という名前のアプリケーションのバイナリができていれば成功です。
それでは、アプリケーションを実行してみましょう。
$ ./kmod-test Start poll, wait 2 sec poll done
上のような出力がされましたでしょうか。
次に、以下のようなコマンドを試してみてください。dmesg コマンドでは、カーネル側から出力されたメッセージを確認することができます。
$ dmesg | tail -n 20 ... [ 875.668875] open() allocated private data [ 875.668881] page 0 at ffff961033aab000 [ 875.668883] page 1 at ffff96102ab95000 [ 875.668884] page 2 at ffff96102c40d000 [ 875.668885] 3 pages are allocated [ 875.668891] page fault offset 8192, page 2 [ 875.668892] mmap is done [ 875.668895] off 9000, len 12 [ 875.668895] Hello world! [ 877.672468] release() released private data
上のような出力になりましたでしょうか。
サンプルプログラムの説明
先に、サンプルプログラムの動かし方について説明しました。次に、実際にサンプルプログラムが何をしているのかについて、netmap と照らし合わせて説明します。
netmap を使ったアプリケーションを書く場合には、以下の4つのポイントでアプリケーションとカーネルのコミュニケーションが行われます。
- キャラクタデバイス /dev/netmap に対して open( ) システムコールを発行し、ファイルデスクリプタを取得する。
- 取得したファイルデスクリプタに、ioctl( ) システムコールを発行し、ネットワークインターフェース登録のリクエストを送る。このリクエストに対して、カーネルはパケットバッファ用のメモリを確保します。
- 取得したファイルデスクリプタに、mmap( ) システムコールを発行し、アプリケーション空間に、カーネル空間との共有メモリを作成する。
- 取得したファイルデスクリプタに、ioctl( ) システムコールを実行し、送受信のリクエストをカーネルへ送る。
まず、最初にカーネルモジュールを insmod コマンドを使ってカーネルにインストールしましたが、そのときに /dev/kmod というキャラクタデバイスの特殊ファイルが作られます。これは、ステップ1で open( ) システムコールを発行する /dev/netmap と対応するものです。
カーネルモジュールの実装では、以下のように、miscdevice 構造体を宣言して、misc_register( ) 関数を実行すると、/dev/*** というキャラクタデバイスを作成できます。miscdevice 構造体と、misc_register( ) 関数は、Linux カーネル自体が用意、実装している関数です。カーネルハックを行っていく場合、多くの部分は、Linux カーネルに実装されている関数を使って機能を追加していきます。
サンプルプログラムでは、miscdevice の登録完了後に、dmesg に "Linux character device driver is loaded" というメッセージを出力するようにしてあります。
struct miscdevice kmod_cdevsw = { MISC_DYNAMIC_MINOR, "kmod", &kmod_fops, }; ... misc_register(&kmod_cdevsw);
アプリケーションは、この特殊ファイル /dev/kmod を使って、カーネルの機能へアクセスしていきます。
open システムコールに対応する処理
上記の miscdevice 構造体は、サンプルプログラムの実装では、下記の kmod_fops という名前の file_operations 構造体へのポインタを保持しています。ここには、/dev/kmod に対して、open( ) システムコールが呼ばれた場合の処理 ( kmod_open ) と、open( ) から得られたファイルデスクリプタに対して、 mmap( ), ioctl( ), poll( ), close( ) システムコールのが、それぞれ呼び出された場合の処理が登録されています。
static struct file_operations kmod_fops = { .owner = THIS_MODULE, .open = kmod_open, .mmap = kmod_mmap, .unlocked_ioctl = kmod_ioctl, .poll = kmod_poll, .release = kmod_release, };
アプリケーション側 ( kmod-test.c ) に、以下のような箇所があります。/dev/kmod に対して、open( ) システムコールを実行しているところです。
fd = open("/dev/kmod", O_RDWR);
この open( ) システムコールは、カーネルモジュールのコード ( kmod.c ) 内の、以下の関数の実装へたどり着きます。これは、kmod_open( ) が kmod_fops ( file_operations 構造体 ) の中で、open が呼ばれた時に対応する処理として登録されたためです。
サンプルプログラムでは、kmod_open( ) が実行されるときに、"open() allocated private data" というメッセージが dmesg に出力されるようにしています。
static int kmod_open(struct inode *inode, struct file *filp) { ... printk(KERN_INFO "open() allocated private data\n"); ... }
これまでの説明で、netmap で /dev/netmap の特殊ファイルに open( ) が呼ばれた際にカーネルモジュールのどの処理へ入っていくのかのイメージをつかんでいただけたらと思います。
ioctl システムコールに対応する処理
次の処理として、ioctl( ) システムコールで、カーネル内部にアプリケーションのためのメモリ確保を行うリクエストを送ります。netmap では、この機能を使って、カーネル空間にパケットバッファ用のメモリを確保します。
サンプルプログラムでは、kmod_user.h というファイルの中にアプリケーションとカーネルで共有される構造体と、命令の種類が宣言されています。今回は、IOCREGMEM という名前をつけた命令に対して、カーネルがメモリを確保するように実装します。
IOREGMEM を引数にした場合に、shared_struct 構造体のメンバ変数の len に、カーネル内部に確保するメモリの大きさを指定します。
アプリケーションでは、以下のような実装になります。
#define IOCREGMEM _IO('i', 1) #define IOCPRINTK _IO('i', 2) struct shared_struct { unsigned long len; unsigned long off; };
struct shared_struct s; ... s.len = 10000; if (ioctl(fd, IOCREGMEM, &s) != 0) {
次に、カーネルモジュールの実装で、IOCREGMEM を引数に ioctl( ) が呼ばれた場合に対応する処理を見ていきます。
/dev/kmod から取得されたファイルデスクリプタに対して ioctl( ) を実行すると、kmod_fops ( file_operations 構造体 ) に登録してある通り、kmod_ioctl( ) 関数が実行されます。第二引数にコマンドが渡され、ここにアプリケーションが指定した、IOCREGMEM の値が入ってきます。
この関数内で、コマンドを switch 文に渡して、それぞれの場合に必要な実装をしていきます。
この処理が完了すると、メモリ確保が完了し、"pages are allocated" というメッセージが dmesg に出力されます。
static long kmod_ioctl(struct file *filp, unsigned int cmd, unsigned long data) { ... switch (cmd) { case IOCREGMEM: { ... /* メモリ確保処理 */ printk(KERN_INFO "%u pages are allocated\n", num_pages); } break; ... }
mmap システムコールに対応する処理
次に、共有メモリの作り方について見ていきます。netmap では、先ほどの ioctl( ) によって確保したパケットバッファ用のメモリをアプリケーションにマップする用途で利用します。
サンプルプログラム ( kmod-test.c ) の中に以下のような箇所を見つけてください。引数の fd は、/dev/kmod への open( ) システムコールの戻り値であることに気をつけてください。引数に 10000 を指定することで、10000 バイト分の共有メモリを作成することをカーネルにリクエストします。
mem = mmap(0, 10000, PROT_WRITE | PROT_READ, MAP_SHARED, fd, 0);
mmap( ) システムコールが呼ばれると、カーネルモジュール内の以下の関数 kmod_mmap( ) へたどり着きます。これも、kmod_mmap( ) が kmod_fops ( file_operations 構造体 ) の中で、mmap が呼ばれた時に対応する処理として登録されているためです。
static struct vm_operations_struct kmod_mmap_ops = {
.fault = kmod_mem_fault,
};
static int kmod_mmap(struct file *filp, struct vm_area_struct *vma)
{
...
vma->vm_ops = &kmod_mmap_ops;
...
}kmod_mmap( ) の実装で重要なのが、vma->vm_ops = &kmod_mmap_ops の部分です。kmod_mmap_ops 変数は vm_operations_struct 構造体で、ページフォルト時に呼び出される関数が登録できます。上記の実装では、kmod_mem_fault( ) 関数が呼び出されることになります。
アプリケーションとの共有メモリを実装する方法は複数ありますが、netmap では、以下のようにページフォルトごとに、アプリケーションのメモリ空間にページをマップしていきます。
static int kmod_mem_fault(struct vm_area_struct *vma, struct vm_fault *vmf) { ... pa = virt_to_phys(priv->page_ptr[off / PAGE_SIZE]); ... pfn = pa >> PAGE_SHIFT; ... page = pfn_to_page(pfn); ... vmf->page = page; // ここにフォルトが発生したメモリ領域にマップするページのアドレスを代入します。 printk(KERN_INFO "mmap is done\n"); return 0; }
ioctl を使った複数の異なるカーネル機能の使い方
ioctl( ) では、引数に指定する命令によって、アプリケーションから複数の異なる機能へアクセスする手段として利用できます。netmap では、この機能を使って、ioctl( ) をインターフェースの登録とメモリ確保だけでなく、データ転送と受信のリクエストをカーネルへ送る用途でも利用します。
先ほどは、IOCREGMEM と名前をつけた命令に対して、カーネル空間にメモリを確保するように実装しました。今度は、共有メモリの機能を確認するために、共有メモリ上にアプリケーション側が用意した文字列をカーネル側で読み取る命令を IOCPRINTK という名前をつけた値を引数にして ioctl( ) の呼び出すことで実行できるようにしてみます。
サンプルプログラムのアプリケーションは以下のようにして、システムコールを呼び出します。これは、共有メモリの先頭から、9000 バイト進んだところに、"Hello world!" と書き込んでいます。
snprintf(&mem[9000], 1000, "Hello world!"); memset(&s, 0, sizeof(struct shared_struct)); s.len = strlen("Hello world!"); s.off = 9000; ioctl(fd, IOCPRINTK, &s);
カーネル側の処理は以下のようになります。switch 文で、IOCPRINTK に対応する処理として実装していきます。この中で、共有メモリの先頭に 9000 バイトのオフセットを追加したアドレスを取得する処理を実装し、実際に printk( ) 関数で dmesg に出力してみます。
static long kmod_ioctl(struct file *filp, unsigned int cmd, unsigned long data) { ... switch (cmd) { case IOCREGMEM: ... break; case IOCPRINTK: { ... /* 共有メモリ先頭から 9000 バイトのオフセットを計算して、buf に代入する処理 */ printk(KERN_INFO "%s\n", buf); } break;
アプリケーションを実行後、dmesg を確認すると、以下のように、カーネル側から、共有メモリ上にアプリケーションが書き込んだ "Hello world!" という文字列を読み取ることができていることがわかります。
[ 875.668895] off 9000, len 12 [ 875.668895] Hello world!
poll システムコールで待機処理を実装する方法
最後に、netmap は受信処理を poll( ) システムコールで待機できるようにしています。select, poll, epoll, kqueue 等のプロッキングによる待機を行わない場合、アプリケーションで busy ループを作ることになり、CPU リソースを大量に消費してしまいます。
アプリケーション側の実装は以下のようになります。以下のようにすると、poll( ) システムコールは、カーネル空間で2秒間待機したのちに、アプリケーションに処理を戻します。
pfd.fd = fd; pfd.events = POLLIN; printf("Start poll, wait 2 sec\n"); poll(&pfd, 1, 2000); // 2000 => 2秒間待機 printf("poll done\n");
これに対して、カーネル側では、 kmod_fops ( file_operations 構造体 ) で poll( ) が呼ばれた時に対応する処理として登録された kmod_poll( ) 関数が呼び出されます。この関数に引数として与えられる、file 構造体と、poll_table_struct 構造体に加え、以下のように init_waitqueue_head( ) 関数で初期化された、wait_queue_head_t オブジェクトを引数にして、poll_wait( ) 関数を呼び出すことで待機の機能を利用できます。
poll に対応する関数は戻り値が重要で、0 を返すと、対応するアプリケーションプロセスが実行すべき処理がないと判断して、待機の処理へ移行します。他には、POLLIN, POLLOUT, POLLERR を戻り値として設定が可能であり、POLLIN では読み取り可能データがあることをアプリケーションプロセスに伝えるために利用されます。これら、POLLIN, POLLOUT, POLLERR を戻り値として指定した場合には、待機処理へ移行せず、poll( ) システムコールはアプリケーションプロセスへ、すぐに処理を移行します。
wait_queue_head_t wq;
...
init_waitqueue_head(&priv->wq);
static u_int kmod_poll(struct file * filp, struct poll_table_struct *pwait) { struct kmod_priv *priv = filp->private_data; poll_wait(filp, &priv->wq, pwait); return 0; }
netmap では、この poll に対応する関数を netmap_poll( ) という名前で実装しており、受信データがなければ、0 をリターンして待機処理へ移行し、その後、待機中に NIC にパケットが到着した場合、NIC から受け取るハードウェア割り込み割り込みを起点として、再度 netmap_poll( ) 関数を実行し、POLLIN を返して、処理をアプリケーションプロセスへ、パケット受信からすぐに移行できるように実装されています。
netmap API を使ったプログラミングとデータ構造について
netmap を使ったアプリケーションで、パケットの送受信を行う方法について、netmap で利用されるデータ構造と一緒にまとめました。
netmap API を使ったプログラミング
netmap では socket と read( )/write( ) システムコールを使ったネットワーク通信が遅いという問題を解決するために、さらに効率の良い方法でアプリケーションからパケットを送受信できるようにしています。
その結果、高速なパケット I/O が実現される代わりに、これまで慣れ親しんだ socket ではなく、netmap 固有の API を使ってアプリケーションを書く必要があります。
このエントリーでは、netmap API を使ったプログラミングを GitHub に公開したサンプルアプリケーション*1を元に説明します。netmap のデフォルトの pkt-gen アプリケーションは、多くの機能が入っており、送受信の部分だけを理解する目的においては、見辛くなってしまうかと思い用意しました。
netmap 自体のインストール方法につきましては、過去のエントリー*2を参考にして頂ければと思います。
準備
- キャラクタデバイス /dev/netmap に対して open( ) システムコールを発行し、ファイルデスクリプタを取得する。
- 取得したファイルデスクリプタに、ioctl( ) システムコールを発行し、ネットワークインターフェースの登録を行う。
- 取得したファイルデスクリプタに、mmap( ) システムコールを発行し、アプリケーション空間に、カーネル空間との共有メモリを作成する。
これらの処理は煩雑ですが、実は、netmap/sys/net/netmap_user.h というヘッダファイルにラッパー関数が実装されており、アプリケーションでは、nm_open( ) という関数を呼び出すだけで、上記の処理を全て完了できます。
nm_open( ) の使い方は以下のようになります。
struct nm_desc *nmd = NULL; ... nmd = nm_open(ifname, NULL, 0, NULL);
nm_open( ) は、第一引数に生成するネットワークインターフェース名を取ります。引数の型は const char * で、具体的には、"vale0:foo" などのインターフェース名の文字列へのポインタとなります。
仮想インターフェースの生成をリクエストする場合には、インターフェース名が "仮想スイッチ名:インターフェース名" のフォーマットで指定される必要があることに注意が必要です。また、仮想スイッチ名は vale から始まる必要があります。
nm_open( ) の他の引数は、NULL と 0 を入れるだけで使えます。仮想インターフェースのリングの数を変更したい場合などには、これらの引数を変更することで、カーネルモジュールにリクエストをすることができます。
nm_open( ) の戻り値は、netmap/sys/net/netmap_user.h で定義されている nm_desc 構造体で、この構造体はアプリケーションが netmap を使ってパケットの送受信を行う際に必要な情報が格納されます。
アプリケーション側からの共有メモリ上オブジェクトへのアクセス
パケット送受信の準備が完了した後の共有メモリの状態は以下のようになります。
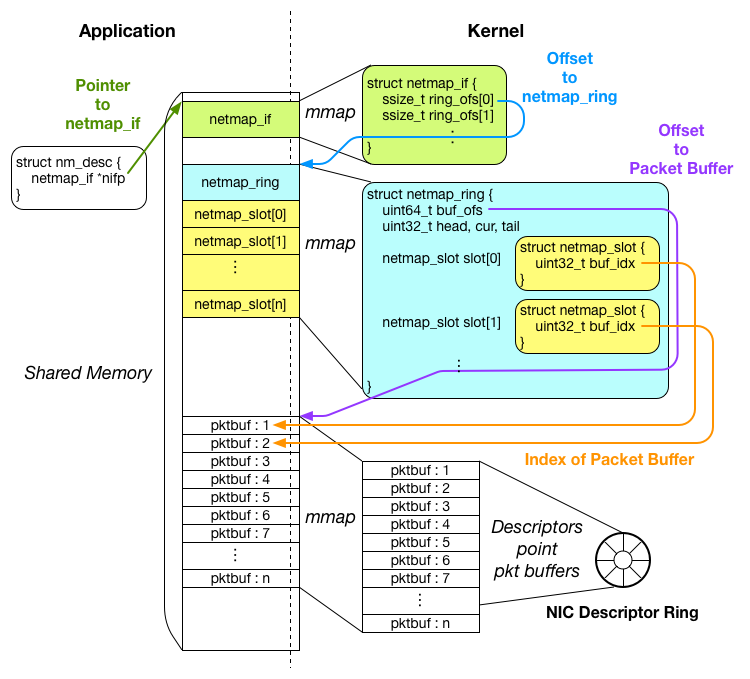
共有メモリのおかげで、アプリケーションはカーネルのメモリ空間内部のオブジェクトにアクセスできるようになりますが、正しくオブジェクトにアクセスするには、どのオブジェクトがどこにあるのかを知っている必要があります。
ですが、アプリケーションが mmap( ) システムコールを実行した際に得られるのは、戻り値として共有メモリの一番先頭のアドレスが返ってくるのみで、パケットバッファがどこにあるか等を知ることはできません。
そこで、netmap では、カーネルとアプリケーションで同じ構造体を共有し、アプリケーション側からオフセットをもとにしたオブジェクトへのアクセスを行えるようにします。
具体的には、netmap_if, netmap_ring, netmap_slot 構造体が共有されています。
netmap_user.h には以下のようなマクロが用意されており、これを使って、アプリケーションは共有メモリ上の netmap_ring やパケットバッファにアクセスしていきます。
#define _NETMAP_OFFSET(type, ptr, offset) \ ((type)(void *)((char *)(ptr) + (offset))) #define NETMAP_TXRING(nifp, index) _NETMAP_OFFSET(struct netmap_ring *, \ nifp, (nifp)->ring_ofs[index] ) #define NETMAP_BUF(ring, index) \ ((char *)(ring) + (ring)->buf_ofs + ((index)*(ring)->nr_buf_size))
まず、アプリケーションの準備の段階で得られた、nm_desc オブジェクトが、メンバ変数 nifp に、共有メモリ上の netmap_if オブジェクトへのポインタ(図中では緑色の矢印)を保持しています。
アプリケーションは、この nifp を起点に、各オブジェクトへのポインタを計算します。
netmap_if 構造体は、メンバ変数 ring_ofs に netmap_ring オブジェクトまでのオフセットを保持しています。
上のマクロの中で、NETMAP_TXRING を見てみてください。このマクロは転送用の netmap_ring へのポインタを取得するために利用されます。
このマクロによると、転送用の一つ目の netmap_ring は、nifp + ring_ofs[0] の場所に用意されています(図中では青い矢印)。ring_ofs が配列になっているのは、一つのインターフェースが複数のリングを保持できるようにするためです。
netmap_ring 構造体は、内部に netmap_slot 構造体の配列をメンバ変数として保持しています。ですので、netmap_slot へは、以下のようにアクセスできます。
struct netmap_ring *ring; struct netmap_slot *slot = &ring->slot[0];
パケットバッファは、それぞれ一意のインデックス番号を保持しており、それぞれの netmap_slot オブジェクトから、buf_idx というメンバ変数によって、インデックス番号をもとに参照されています。
マクロのリストの中にある、NETMAP_BUF を見てみてください。このマクロは以下のように、パケットバッファのポインタを得る際に利用されます。
struct char *pktbuf = NETMAP_BUF(ring, slot->buf_idx);
このマクロによれば、インデックス番号 N のパケットバッファは、「netmap_ring のあるアドレス」+「パケットバッファ開始位置までのオフセット:図中紫色の矢印」+「N × パケットバッファ一つの大きさ:図中オレンジの矢印」に位置しています。
以上のように、アプリケーション側からの各オブジェクトへのアクセスは、カーネル側が設定した各構造体に格納されるオフセットの値をもとに行われます。
パケット送信
パケット送信を行うには、アプリケーションは以下の処理を行う必要があります。
- パケットのデータを適切な位置のパケットバッファに書き込む。
- netmap_ring オブジェクトのメンバ変数 head, cur を更新する。
- インターフェースからのデータ送信をカーネル側へ ioctl( ) もしくは poll( ) システムコールを使ってリクエストする。
サンプルプログラムの中では transmit_packets( ) という関数に送信の部分が実装されています。
1. 適切なパケットバッファへのデータ書き込み
データ書き込みを行うべきパケットバッファの位置は、nm_desc オブジェクトの nifp メンバ変数から辿ります。まず、転送用 netmap_ring のポインタを取得します。
struct netmap_ring *tx_ring; // nmd は nm_desc 構造体、引数 0 は一つ目の転送用リングのアドレスを取得するために指定 tx_ring = NETMAP_TXRING(nmd->nifp, 0);
次に、目的のパケットバッファを参照している netmap_slot オブジェクトを取得します。
netmap_ring は、以下のように netmap_slot をリング状にまとめており、各 netmap_slot がインデックス番号 ( buf_idx ) で参照しているパケットバッファのデータが順番に転送されていきます。
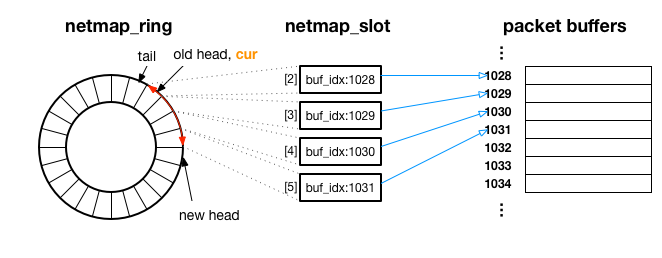
次にどの netmap_slot が参照しているパケットバッファのデータが転送されるか、という情報は、netmap_ring 構造体の cur メンバ変数(図中オレンジ)が保持しています。
cur は netmap_ring 構造体が保持する netmap_slot 配列のインデックスとして利用します。具体的には、以下のようにすることで、次に書き込むべきパケットバッファを参照している netmap_slot のアドレスを取得できます。
j = tx_ring->cur;
...
struct netmap_slot *slot = &tx_ring->slot[j];
これで、次に書き込むべきパケットバッファのインデックスを知ることができます。以下のようにすることで、変数 txbuf に、転送パケットの書き込み先のアドレスが取得できます。
char *txbuf = NETMAP_BUF(tx_ring, slot->buf_idx);
書き込み先がわかったので、データを書き込みます。netmap ではパケットバッファ上のデータがそのまま送信されるため、イーサーネットや IP、UDP ヘッダもアプリケーションで用意します。サンプルプログラムの中では、make_packet という関数の中でヘッダをつける処理をしています。
パケットの準備が完了したら、netmap_slot オブジェクトのメンバ変数 len に、パケットのデータの長さを代入します。
/* Make a ethernet packet * - Prepare ether, IP and UDP headers * - Copy payload into the packet buffer */ pkt_len = make_packet(txbuf, payload, strlen(payload)); ... /* Set packet length to slot->len */ slot->len = pkt_len;
以上で、パケット1つ分の用意が完了しました。続けて次のパケットを用意する場合には、以下のようにして、次の netmap_slot の配列内でのインデックスを取得して、ここまでと同じ処理を繰り返していきます。
// j には、次の netmap_slot の配列内でのインデックスが入ります j = nm_ring_next(tx_ring, j);
2. netmap_ring の head, cur のアップデート
アプリケーション側で、ペイロードの書き込みが完了しましたが、次は逆にアプリケーションが、どこまでペイロードを書き込んだかをカーネル側に伝える必要があります。
この情報のカーネル側への引渡しは、アプリケーション側でデータ書き込みが完了したスロットの最後尾の netmap_slot のインデックスを、netmap_ring 構造体のメンバ変数 head, cur に代入することで行います。プログラムは以下のようになります。
/* Upadte head and cur indexes of netmap_ring */
tx_ring->head = tx_ring->cur = j;
カーネルは、netmap_ring の head の値を見て、tail から head にかけてのパケットを送信します。
上の図は、netmap_ring のメンバ変数 head が old head から、new head にアップデートされた例で、赤い矢印の部分の netmap_slot が参照しているパケットバッファ(インデックス 1028 ~ 1031 まで)が、カーネル内の処理によって転送されます。
3. カーネル側へデータ発信リクエストを送る
ペイロードの書き込みが完了し、カーネル側へ転送してほしいペイロードの場所を伝える準備もできました。
いよいよシステムコールを発行して、カーネル空間へ移り、データ転送の処理を行います。カーネルに転送をリクエストするには、ioctl( ) もしくは poll( ) システムコールが使えます。
以下のようにすると、これまで用意してきたパケットが実際に送信されます。
/* Packets will be transmitted in this ioctl syscall */ // nmd は nm_desc 構造体、NIOCTXSYNC は転送リクエストです ioctl(nmd->fd, NIOCTXSYNC, NULL);
パケット受信
受信側は以下の処理の繰り返しになります。
- パケット受信を poll( ) システムコールで待つ。
- 届いたデータを読む。
- netmap_ring オブジェクトのメンバ変数 head, cur を更新する。
1. poll( ) システムコールによる受信待機
アプリケーションはパケットの受信を poll( ) システムコールを使って待つことができます。サンプルプログラムでは、以下のようにして、poll( ) システムコールを使っています。
// nmd は nm_desc 構造体 struct pollfd pfd = { .fd = nmd->fd, .events = POLLIN }; while (!do_abort) { ... ret = poll(&pfd, 1, 1000); ... receive_packets(nmd); }
パケットが届く、もしくは設定したタイムアウト(上の例では1秒間)した場合に、poll( ) システムコールから処理がアプリケーションへ戻ってきます。poll( ) の中で待機している間は、CPU リソースを手放すことができるので、ビジーループを作らず、CPU リーソス的に、電力的に効率がよくなります。
インターフェースがパケットを受信した場合、poll( ) システムコールは、受信したパケットの最後尾まで、受信用 netmap_ring の tail が更新されます。これは、アプリケーションに、netmap_ring の head から、更新された tail までのデータがアプリケーション側から読み込み可能であることを伝えるために行われます。
2. 受信したデータの読み取り
アプリケーション内部でのパケットの受信処理は、サンプルでは receive_packets 関数に実装されています。
データの読み取りに関してのポイントは、どこにデータが届いたかを知ることですが、これは転送の場合と同じ要領で行えます。以下のプログラムでは、変数 rxbuf に受信したデータの先頭のアドレスが代入されます。
struct netmap_ring *rx_ring; unsigned int j, n; // NETMAP_RXRING マクロを使って受信用 netmap_ring のアドレスを取得 rx_ring = NETMAP_RXRING(nmd->nifp, 0); j = rx_ring->cur; ... while (n-- > 0) { // 読み込むべきパケットバッファを参照している netmap_slot を取得 struct netmap_slot *slot = &rx_ring->slot[j]; // netmap_slot の buf_idx をもとに、受信データがあるパケットバッファのアドレスを取得 char *rxbuf = NETMAP_BUF(rx_ring, slot->buf_idx); ...
次に、ペイロードの位置を取得します。アプリケーションからは、イーサーネットヘッダや IP ヘッダを含むパケットの全体像が見えており、また rxbuf はパケットの先頭のアドレスを指しているため、ペイロード自体のアドレスを得るには、これらのヘッダのオフセットを足す必要があります。
サンプルの送信側では、UDP ヘッダを追加しているため、イーサネット、IP、UDP ヘッダの合計サイズを rxbuf から進めたところが今回のサンプルコードで受信されるペイロードの位置になります。プログラムで書くと以下のようになります。
char *payload = (char *)((unsigned long) rxbuf + sizeof(struct ether_header) + sizeof(struct ip) + sizeof(struct udphdr));
やっと受信したペイロードに辿り着けました。NF アプリケーション等を作る際には、このデータに対して処理を行っていくことになると思います。
nm_ring_space(rx_ring) で受信されたパケットの個数がわかりますので、以下のように nm_ring_next( ) 関数でスロットを進めて同じ処理を続けていくと、全ての受信したデータに対して読み込み処理を行えます。
n = nm_ring_space(rx_ring); while (n-- > 0) { struct netmap_slot *slot = &rx_ring->slot[j]; ... j = nm_ring_next(rx_ring, j); }
3. 受信用 netmap_ring の head, cur を更新
最後に、アプリケーション側から、カーネル側へ、どこまでデータを読み終えたかを伝えるために、受信用 netmap_ring の head, cur をアップデートします。これにより、カーネルは、新しく届くパケットのデータを head の位置まで上書きしてよいことを知ることができます。逆に、head の位置を更新しなければ、head 以降が新しいデータで上書きされません。
/* Upadte head and cur indexes of netmap_ring */
rx_ring->head = rx_ring->cur = j;
上記の処理を行ったら、また最初の poll( ) で待機を行うループへ戻ってきます。poll( ) システムコールでは、新しくアップデートされた head の位置をカーネル内に反映する処理を行った後、次のパケットが届くまで、再度待機を継続します。
netmap で Network Function アプリケーションを動かしてみる
netmap のサンプルアプリケーションの bridge と、FreeBSD の IP ファイアーウォールのユーザー空間実装である netmap-ipfw を動かしてみます。
netmap bridge を動かす
netmap bridge は netmap レポジトリの apps/bridge ディレクトリにあります。
この実装は二つのインターフェースに対して netmap を有効にして、片側のインターフェースから受信したパケットを反対側のインターフェースにフォワードします。
様々な NF アプリケーションの基本となるような挙動の実装方法が示されています。
実際に試していきます。
netmap のカーネルモジュールをインストールした状態で以下を試してください。netmap のインストール方法は以前のエントリー*1に書いてありますので、そちらも参考にしてください。
まず、clone してきた netmap のディレクトリへ移動します。
$ cd netmap
次に、bridge アプリケーションのディレクトリへ移動して、make を実行してコンパイルを行います。
$ cd apps/bridge $ make
ディレクトリに bridge という名前のアプリケーションができていれば成功です。
実際にアプリケーションを実行してみましょう。
$ ./bridge -i vale0:foo -i vale1:bar
上記のコマンドを実行すると、二つの仮想インターフェースが生成され、bridge アプリケーションはそれらのインターフェースに対して受け取ったデータをフォワードします。
以前のエントリー*2で試した pkt-gen アプリケーションを使って、パケットの転送を確認してみましょう。
新しいターミナルを開いて、pkt-gen のプログラムのあるディレクトリまで移動したのち、以下のようなコマンドを実行して受信側の pkt-gen を立ち上げてみてください。
$ ./pkt-gen -i vale1:rx -f rx
次に、またもう一つ新しくターミナルを開いて、下記のようなコマンドで、送信側の pkt-gen を実行してください。
$ ./pkt-gen -i vale0:tx -f tx
受信側でパケットが受信されたら成功です。
また、受信側の pkt-gen がパケットを受信していることを確認したら、bridge アプリケーションを停止してみてください。受信側の pkt-gen でパケットが受信されなくなるはずです。
このようにコマンドを実行すると、トポロジーは以下の図のようになります。
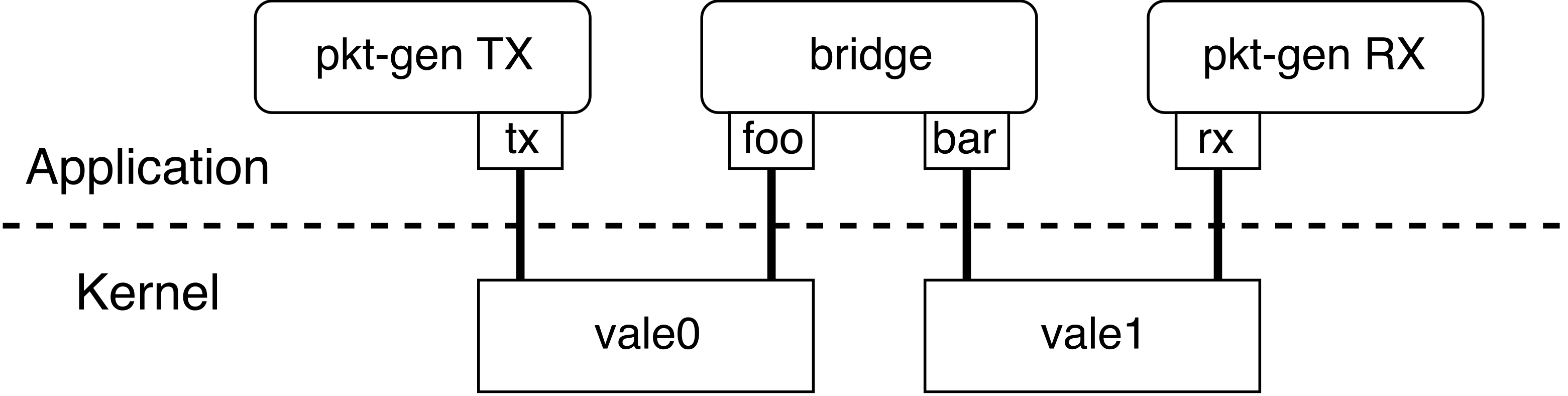
bridge と pkt-gen のアプリケーション起動時に指定する -i オプションの組み合わせによって、このような設定を行っています。
まず、最初の bridge アプリケーションのために foo と bar という仮想インターフェース(VALE ポート)が作成されるのと一緒に、同時に指定した vale0, vale1 という名前の別々の VALE スイッチがカーネル空間に作られます。
次に、受信 pkt-gen アプリケーションは、rx という名前の仮想インターフェースを持つように指定し、さらにそれは vale1 と名前のついた VALE スイッチに接続されます。
送信 pkt-gen の仮想インターフェースには、tx という名前を指定し、vale0 という名前の VALE スイッチにつながります。
送信側の pkt-gen から転送されたパケットはまず、vale0 VALE スイッチへ送られ、vale0 VALE スイッチは、同じスイッチに繋がっている foo というインターフェースへ向けて、受信したデータをフォワードします。
vale0 からフォワードされたパケットは、bridge アプリケーションへたどり着き、bridge アプリケーション内部で foo から bar インターフェースへのパケットフォワードを行います。
この段階で、パケットをチェックしてフォワードしない、もしくはパケットの中身を一部変更する等の処理を追加することで、オリジナルな NF アプリケーションが実装できます。
bar インターフェースから送信されたパケットは vale1 VALE スイッチへ送られ、vale1 は同じスイッチに接続されている rx インターフェースへ向けてパケットをフォワードします。
こうして、受信側の pkt-gen アプリケーションへ送信側 pkt-gen が生成したパケットが到着します。
netmap-ipfw を試す
bridge アプリケーションは、ただ受け取ったパケットをフォワードするだけでしたので、次は実際に使われるようなファイアーウォールを動かしてみます。
netmap-ipfw*3 は FreeBSD に実装されているファイアーウォール実装をユーザー空間へポートした上で、netmap API への対応が追加されています。
実際にダウンロードして、ビルドしてみます。
make コマンドを実行する際に、netmap のディレクトリ内部にある sys というディレクトリまでのパスを NETMAP_INC に指定する必要があります。
$ git clone https://github.com/luigirizzo/netmap-ipfw.git $ cd netmap-ipfw $ make NETMAP_INC=/netmapのディレクトリ/sys
コマンド実行後に、kipfw というバイナリができていれば成功です。
実行してみましょう。トポロジーは、bridge のサンプルと同じになるようにします。
ipfw の起動。
$ ./kipfw vale0:foo vale1:bar
受信側 pkt-gen の用意。
新しくターミナルを開いて、pkt-gen のディレクトリまで移動の後、以下のコマンドを実行してください。
$ ./pkt-gen -i vale1:rx -f rx
送信側 pkt-gen も同じく、新しく開いたターミナルで、pkt-gen のディレクトリまで移動の後、以下のコマンドを実行してください。
$ ./pkt-gen -i vale0:tx -f tx
bridge の時と同じように、受信側でデータが受け取れたら成功です。
netmap-ipfw は FreeBSD の ipfw と同じコマンドでルールが追加可能です。
pkt-gen アプリケーションは UDP パケットを生成するので、UDP パケットを通さないルールを netmap-ipfw を追加してみましょう。
ルールの追加と削除をするには netmap-ipfw/ipfw 以下にある、ipfw コマンドを使います。
netmap-ipfw のディレクトリに移動したのち、以下のコマンドを実行してみてください。
$ ./ipfw/ipfw add 100 deny udp from any to any
受信側にパケットが届かなくなったのではないでしょうか。
$ ./ipfw/ipfw delete 100
先ほど追加したルールを削除してみます。
再度パケットが受信側に届き始めたら成功です。
高速パケット I/O フレームワーク netmap 使ってみる
netmap の使い方について、学術的なコンセプトと一緒にまとめました。
インストールの方法から、基本となるパケット生成アプリケーションである、pkt-gen の使い方までについて書きました。
何ができるのか?
高速にパケット I/O を行うアプリケーションを作ることができます。
詳細は著名な国際学会の一つ USENIX ATC'12 で発表された論文*2に記載されていますが、 ひとつの主な想定アプリケーションはネットワーク機能の仮想化( NFV : Network Function Virtualization )です。
NFV はネットワーク機能を汎用なハードウェアで実装するコンセプトです。これまで専用ハードウェアとして実装されていた、例えばファイアーウォールやルーターなどを汎用サーバーの上で実行可能なソフトウェアとして実装することによって、一つの汎用ハードウェアを複数用途で利用することが可能になり、導入、運用のコストを低下させる目的で利用できると言われています。
netmap が解決している問題
Linux や FreeBSD 等の汎用 OS を用いて、NFV アプリケーションを実装する際には、アプリケーションからのネットワーク通信(パケット I/O)が遅いという問題がありました。具体的には、アプリケーションはパケットの送受信に際して、socket のファイルデスクリプタに read( )/write( ) のシステムコールを実行する必要があり、この通信に関する API が遅い*3ということや、ペイロードのアプリケーションからカーネル空間へのコピー、パケットバッファの確保等の処理に時間がかかってしまうということが挙げられます。
つまりは、汎用 OS の socket API を使って NFV アプリケーションを作ろうとすると高い性能が発揮できないという問題がありました。
netmap で採用されている高速化手法
基本的なアイデアは、カーネル空間にあるパケットバッファを、直接、アプリケーションのメモリ空間にマップすることです。
カーネル空間のパケットバッファは、ネットワークカード ( NIC ) が直接参照しており、送信に際しては、アプリケーションはマップされたパケットバッファへ、ペイロードを書き込むだけでよく、あとは NIC のドライバが転送開始の命令を送るとパケットが送信されます。netmap はアプリケーションから NIC ドライバの転送開始命令までの処理へたどり着くための高速なパスを実装しており、それがこれまでにパケットが通らなければならなかったカーネル内部の処理( UDP パケット処理等 ) を迂回することになるので、”カーネルバイパス”という技術の一つとして位置づけられています。(アカデミアの領域では、カーネルバイパスネットワーキングに関するワークショップ*4が SIGCOMM'17 の併設で開催されたりとホットなテーマの一つのようです。)
受信側についても同じく、パケットバッファがアプリケーションのメモリ空間にマップされているため、受信パケットが NIC に辿り着いた時には、既にアプリケーションから受信ペイロードが見えるようになっています。ですが、アプリケーションは、マップされたパケットバッファのどこに新しいデータが着いたのかを知らないため、受信場所についての情報はカーネル側から提供してもらう必要があります。netmap の API はこの受信場所を効率良くアプリケーションへ伝えるための実装がなされています。
試してみる
今回は、Linux を使ってサンプルを動かしてみます。
手元では、仮想マシン上の Ubuntu 17.04 を使いました。カーネルのバージョンはデフォルトのまま 4.10.0-19 です。
下準備
Ubuntu 等をインストールした状態では、カーネルモジュールのビルドに必要なヘッダファイル等が不足しており、ビルドに失敗してしまうことがあります。
以下のようなパッケージをインストールすることで、ビルドが成功するはずです。
カーネルのバージョンは環境に合わせてください。
$ apt-get install linux-headers-4.10.0-19
ソースコードのダウンロード
$ git clone https://github.com/luigirizzo/netmap.git
ビルド
$ cd netmap $ make
上記のコマンドを実行すると、対応可能な NIC のドライバのソースコードをダウンロードして、必要なパッチを当てた上で、netmap 自体のカーネルモジュールをビルドしてくれます。
netmap は NIC のドライバのパケット入出力周辺に変更が必要なため、デフォルトのドライバにパッチをあてて、そのドライバを netmap のカーネルモジュールと一緒にインストールする必要があります。
コマンド実行完了後、netmap.ko というファイルが生成されていれば成功です。
モジュールのインストール
insmod netmap.ko
NIC に対して netmap を有効にできるようにするためには、パッチのあたった NIC ドライバのモジュールをロードしなおす必要があります。
パッチのあたったモジュールは netmap のディレクトリの内部に見つかるはずです。
今回は、NIC は使わずに、仮想ポートを使ってサンプルプログラムを動かします。
注意事項
netmap を使うと、輻輳制御等関係なくパケットをバーストできます。
結果、学校や会社のネットワーク機器に多大な負荷をかけ、障害を起こすことができる可能性があります。インターネットとの疎通のために利用しているインターフェースに対しては netmap を使わない方が良いかもしれません。
例えば、1Gbps NIC e1000 でインターネットにつないでおり、10 Gbps NIC ixgbe をテストに使う場合などのように、インターネットと繋がっているインターフェースの NIC のドライバがテスト用 NIC のドライバと異なる場合は、e1000 ドライバを netmap のパッチが当たったものと交換しないことで、意図しないパケットの放出を回避できると思います。
pkt-gen アプリケーションを試す
pkt-gen アプリケーションは netmap を使ってパケットを送受信できるプログラムです。
今回は NIC からのパケット転送ではなく、仮想ポートを使ったパケット送信を試します。
仮想ポートは、netmap では、netmap API の上で動作する VALE スイッチに接続される VALE ポートとなります。
VALE スイッチはとても高速なスイッチで、カーネル内部でパケットをフォワードしてくれます。
VALE の詳細については、国際学会 CoNEXT'12 で発表された論文*5に書かれています。
アプリケーションをビルドします。
$ cd apps/pkt-gen $ make
受信側アプリケーションを実行します。
ターミナルで以下のコマンドを実行してください。
$ ./pkt-gen -i vale0:rx -f rx
送信側アプリケーションを実行します。
新しくターミナルを開いて、以下のコマンドを実行してください。
秒間に1パケットずつ、送信側から受信側へ送信されます。
$ ./pkt-gen -i vale0:tx -f tx -R 1
以下のような表示が受信側で見られたら成功です。
218.693791 main_thread [2494] 1.000 pps (1.000 pkts 480.000 bps in 1001100 usec) 1.00 avg_batch 1023 min_space 219.695181 main_thread [2494] 1.000 pps (1.000 pkts 480.000 bps in 1001390 usec) 1.00 avg_batch 1023 min_space 220.695994 main_thread [2494] 1.000 pps (1.000 pkts 480.000 bps in 1000814 usec) 1.00 avg_batch 1023 min_space
簡単にオプションの説明をします。
-i vale0:rx
-i では、pkt-gen のアプリケーションで利用するポートを指定します。
表記は "仮想スイッチ名":"仮想ポート名" となり、重要なのは、VALE スイッチに接続する場合は、必ず仮想スイッチ名は vale で始まる必要があります。
valex, valey, valez は問題ありませんが、valx, valy, valz はアプリケーションの起動に失敗します。
これは netmap の内部実装に起因します。
-f rx
-f では、機能を指定します。tx, rx で転送、受信を指定できます。
ping, pong 等も実装されており、遅延の評価ができます。
-R 1
-R では、秒間の転送パケット数を指定できます。
1を指定したので、1秒に1パケットが送られたはずです。
このオプションを指定しない場合には、できるだけ高速にパケットが送信されます。
もう一つ、今回は試していませんが、NIC に対して、同じく pkt-gen のアプリケーションでパケットの送受信をしたい場合は、この -i オプションで netmap:"物理 NIC 名" のように指定します。物理 NIC 名は eth0 のような ifconfig で確認できるものです。
eth0 から pkt-gen でデータを受信したい場合は、以下のようになるはずです。(パッチのあたった NIC のドライバをロードしたのち試してみてください。)
$ ./pkt-gen -i netmap:eth0 -f rx
最後に、-R オプションを外して送受信を行ってみてください。
十数 million packet / sec の性能がでるはずです。
pkt-gen のアプリケーションはパケットの長さ、送受信のMACアドレスの指定等、多くのオプションをサポートしているので、ヘルプをみて他にも是非試してみてください。