いい感じに仮想メモリアドレスとファイルオフセットを変換するスマートポインタを作った
ファイルを mmap した仮想メモリアドレス空間の上でデータ構造の操作を行い、変更をそのままファイルへ保存したいと思ったことはありませんでしょうか。
面倒な点として、mmap されたファイルは、次回以降 mmap されたときに、同じ仮想メモリアドレスにマップされる保証がないため、連結リストのようなポインタを用いるデータ構造を保存する場合には、ポインタの値を仮想メモリアドレスから、ファイル内のオフセットに変換した上で、ファイルへ書き込む必要があります。
この変換は書き込みだけでなく、読み込みの場合はファイル内のオフセットから仮想メモリアドレスへ変換しなおす必要があり、実装が複雑化しやすいという問題があります。
今回は、そのような手間を省くために、変数の代入ごとに仮想メモリアドレスとファイルオフセットの変換を自動で行ってくれるスマートポインタを作ってみました。
ソースコードを GitHub で公開しておりますので、ご興味がありましたら是非お試しください。
解決したかった問題
例えば、mmap したファイルの上で、連結リストを実装することを考えてみます。
まず、mmap を実行すると、OS はファイルをマップした仮想メモリの先頭のアドレスをリターンします。今回は例として、仮想アドレス 0x8b3000 にファイルがマップされたとします。(実際は通常もっと大きな値になります。)
連結リストを実装する際には、以下のような構造体を利用すると思いますが、リストの先頭となる node ( list_head ) を 0x8b3000 に置いて、next へ次の node のポインタの値を設定することとします。
struct node { int val; struct node *next; }; struct node *list_head = 0x8b3000;
なんとなく、先頭の次の node は仮想メモリアドレス 0x8b3090 の領域に配置することにしました。
さて、この場合、リストの先頭の next の値 ( list_head->next ) には何を代入すべきでしょうか。
メモリ内だけで完結するプログラムであれば、以下のように、list_head->next には 0x8b3090 を代入することになると思われます。
struct node *new_node = 0x8b3090; list_head->next = new_node;
ですが、list_head がメモリマップトファイルの上に置かれている今回においては、問題が発生します。
メモリマップトファイルの上の数値は、そのままファイルに保存されます。その結果、次回、同じファイルを mmap した時に、別の仮想メモリアドレスへファイルがマップされた場合、新しい node ( new_node ) は 0x8b3090 とは別の仮想メモリアドレスに配置されてしまいます。
このような、メモリ領域の再配置へ対応できるようにするためには、以下のように、ポインタを仮想メモリアドレスではなく、ファイル内のオフセットとして保存しておくようにする必要があります。今回の場合では、new_node は、ファイルの先頭から 0x90 離れた場所にあるので、list_head->next へは、0x90 を代入しておくべきです。
struct node { int val; unsigned long next; // file offset }; struct node *list_head = 0x8b3000; struct node *new_node = 0x8b3090; list_head->next = (unsigned long) new_node - 0x8b3000; // 0x90;
このようにしておくと、例えば、次回 mmap によって、同じファイルが仮想メモリアドレス 0x8b3000 ではなく、0x9b3000 にマップされたとしても、new_node へは、ファイルがマップされた先頭のアドレス 0x9b3000 へ、list_head->next に保存されている 0x90 を加算することで、0x9b3090 に new_node があることがわかります。
void *addr = mmap(...); // 0x9b3000 struct node *list_head = addr; struct node *new_node = (unsigned long) addr + list_head->next; // 0x9b3000 + 0x90
以上のように、メモリマップトファイルの上にデータ構造を保存しようとする場合、せっかく仮想メモリ空間上でデータの操作ができるにもかかわらず、ポインタの値は毎度ファイル上のオフセットと、仮想メモリアドレスを変換しなければなりません。
各代入において値の変換を行うのは手間がかかり、実装の複雑性が高まってしまいます。
解決策:fmalloc pointer ( fm_ptr )
今回は、このポインタの値の変換にかかる手間を大幅に削減できる fm_ptr というスマートポインタをつくってみました。
メモリマップトファイル上のポインタの理想的な挙動は、
- プログラムが参照するときには仮想メモリアドレス
- ファイルへ書き込まれるときには、ファイル内のオフセット
であると思われます。fm_ptr はこの挙動を実現します。
実装については、C++ の演算子のオーバーロードを使っています。
大前提として、fm_ptr は、メモリ上にファイル内オフセットを保存します。
そして、参照される場合には、メモリマップトファイルのマップ開始アドレスを加算した値を返します。
また、値が代入される場合には、渡された値から、メモリマップトファイルのマップ開始アドレスを引いた値を、メモリ上に保存します。
これにより、プログラムが代入、参照、他にも加算や比較を行う場合には、仮想メモリアドレスを扱っているように見えます。
ポイントとして、演算子のオーバーロードの処理は、メモリコピーによって値が別の場所へコピーされる場合には実行されないという点があります。
メモリマップトファイルのメモリ上のデータは、メモリのコピーによって、ストレージデバイスへ移動されるため、メモリ上に保存されているファイルオフセットは、演算子オーバーロードによって仮想アドレスへ変換されることなく、ストレージデバイスへ送られます。
使い方
fm_ptr をポインタとして利用してリストを実装すると以下のようになります。
struct node { int val; fm_ptr<struct node> next; } __attribute__((packed)); static void list_append(struct node *head, struct node *newnode) { struct node *n = head; while (n->next) { n = n->next; } n->next = newnode; }
node のメンバの next がスマートポインタになっている以外は、普通のメモリ内で完結する連結リストの実装と同じになっています。
list_append の中では、next の値を参照、代入していますが、ここで特にファイルオフセットの値との変換を明記しなくてよいのは、
fm_ptr が内部的に自動で変換を行っているからです。
このように、fm_ptr によって、メモリ内で完結するデータ構造のプログラミングと近い形のまま、メモリマップトファイルへデータを保存することができるようになります。
使用の際には、メモリマップトファイルの先頭はスレッドローカルストレージ ( TLS )に設定することを想定しており、TLS 上の値を変更していくことで、複数のファイルを同時に扱えるようになっています。詳細は実装をご覧ください。
まとめ
メモリマップトファイル向けに、仮想メモリアドレスとファイルのオフセットを自動で変換するスマートポインタを作ってみました。
マルチコアでスケールするB木を書いてみた
Optimistic, Latch-Free Index Traversal (OLFIT) という手法を提案している、Cache-Conscious Concurrency Control of Main-Memory Indexes on Shared-Memory Multiprocessor Systems という論文を参考に、マルチコア環境でスケールするB木を書いてみました。
Optimistic Concurrency Control (OCC) (日本語では楽観的並行性制御)について勉強になったので記事にしてみようと思いました。
ソースコードを GitHub に置いておきましたので、ご興味がありましたら是非試してみてください。
B木の並列操作
B木はファイルシステムや、キーバリューストア (KVS) 、データベースでよく利用されるデータ構造です。キーとバリューのペアを効率よく保存できます。
最近のコンピューターではマルチコアが比較的一般的になっているので、多くのプログラムにとって、コアを増やすほど速くなる、というのが一つの大事な要件になっています。KVS 等においてもこの点は例外ではありません。
KVS 等のソフトウェアは、B木のようなデータ構造を元にデータを保存しますが、複数コアが並列でデータの追加、更新、探索を行う場合、B木等のデータ構造の操作自体が競合のポイントになりがちです。
今回は、データ構造の並列操作に伴う競合による性能の低下を抑える手法の一つである Optimistic Concurrency Control (OCC) という仕組みを取り入れてB木を書いてみました。(厳密にはB+木を書きました。)
readers-writer ロックの問題点
並列性に配慮したプログラムで比較的よく利用されるロックに readers-writer ロックと呼ばれるものがあります。
このロックには、書き込みロックと読み込みロックの2種類があり、同じロックのオブジェクトについて、書き込みを行いたい場合、書き込みロックを、読み込みを行いたい場合は読み込みロックを取得します。
書き込みロックは、ほかに書き込みロックを取っているワーカーがおらず、かつ、読み込みロックを取っているワーカーもいない場合に取得できます。一方、読み込みロックは、書き込みのロックが取られていなければ取得できます。
これにより、同じデータの読み取りを行うワーカーが複数いたとしても、互いをブロックしないで同時に読み込みを行うことができます。
一見、readers-writer ロックには問題がないように見えるのですが、CPU のキャッシュが性能において重要になるB木のようなデータ構造では、キャッシュ効率の観点から性能が伸びない場合が多いようです。
readers-writer ロックの問題として、 書き込みロックだけでなく、読み込みロックも、書き込みロックが取られないように、現在読み込み中であることを示すために、メモリ上のロックのオブジェクトの値を更新する必要があるということがあります。
ある CPU によって更新されたメモリ上の値が他の CPU から参照される場合には、更新された値については 参照する側の CPU キャッシュが効かないため、ロックオブジェクトの値の読み込みには時間がかかります。
readers-writer ロックは多くの場合でマルチコアスケーラビリティを達成できる方法である一方で、CPU キャッシュが性能において重要なシステムでは問題になる場合があります。
Optimistic Concurrency Control (OCC)
OCC は CPU キャッシュを効かせやすい並列実行制御の方法として利用されることがあります。OLFIT の論文では、OCC を適用した B link Tree を提案しています。
OLFIT の特徴として、読み込み時にラッチ(ロック)を獲得しないという点があります。OLFIT では、ラッチとバージョン番号という2つのオブジェクトを使って並列操作の制御を行います。
OLFIT の論文に記述されている更新アルゴリズムは以下のようになります。
1. ラッチを取得する
2. コンテンツを更新する
3. バージョン番号を増加させる
4. ラッチを解放する
以下が読み込みアルゴリズムです。
1. バージョン番号を取得する
2. コンテンツを読み込む
3. ラッチが獲得されているかを確認する。もし獲得されていれば1に戻ってやりなおす
4. 再度バージョン番号を取得する。もし、取得したバージョン番号が1で取得した値と違った場合、1に戻ってやりなおす
以上が、基本的な操作の仕組みです。
ポイントは、読み込み操作にメモリ上のオブジェクトに対して書き込みが不要であるということです。readers-writer ロックと異なり、OLFIT では、読み込み操作は、書き込み操作をブロックしません。そのかわりに、バージョン番号を用いて変更を検出できるようにしておき、もし読み込み側が変更を検出した場合には、変更が検出されなくなるまで読み込みをやりなおす、という戦略を採用しています。
今回は、この仕組みを使って、並列操作が可能なB+木を実装してみました。
性能
1千万件のランダムな8バイトキーと8バイトのバリューを追加するベンチマークをしてみると以下のような結果になりました。
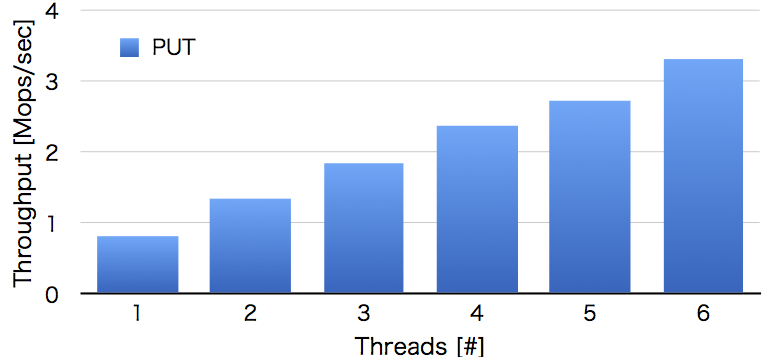
もっとうまく実装できればこれ以上に速くなると思うのですが、今回は完全にスケールするというところまではいきませんでした。ですが、スレッド数に合わせて線形に性能が伸びているのでそこまで悪くない結果だと思います。
その他の資料
マルチコアでスケールするツリー構造といえば Masstree が有名ですが、Masstree の設計は OLFIT に影響を受けているそうです。
fsync はなぜ時間がかかるのか
fsync について調べたことをまとめます。特に、最新の研究も含めて、ジャーナリングやメタデータの整合性について書いていこうと思います。
読んでいただけると、ファイルシステムが裏でどのようにデータを永続ストレージへ書き出しているかについての理解が少しだけ深まるかもしれません。
勉強していた時に、もう少し細かく挙動を説明してくれる資料があればいいなぁと強く思ったのを覚えていて、今回この記事を書いてみようと思いました。これから勉強される方の参考になればと思います。
いざ書き始めると前提とする情報があまりに多かったので、別の記事にして背景を最初にまとめることにしました。内容についてわかりにくいと思われましたら、適宜過去の記事を参照いただけましたら理解の助けになるかもしれません。
fsync
fsync は指定したファイルのデータの永続性を保証するために利用されるシステムコールです。
Linux の Man page of fsync によると、fsync は以下のように説明されています。
int fsync(int fd) fsync() は、ファイルディスクリプター fd で参照されるファイルの、メモリー内で存在する修正されたデータ (つまり修正されたバッファーキャッシュページ) を、ディスクデバイス(またはその他の永続ストレージデバイス) に転送 (「フラッシュ」) し、これにより、システムがクラッシュしたり、再起動された後も、変更された全ての情報が取り出せるようになる。「フラッシュ」には、ライトスルー (write through) や (存在する場合には) ディスクキャッシュのフラッシュも含まれる。この呼び出しは転送が終わったとデバイスが報告するまでブロックする。またファイルに結びついた メタデータ情報 (stat(2) 参照) もフラッシュする。
fsync は他のファイル入出力のシステムコールと比較して時間がかかり、ソフトウェア性能のボトルネックになりがちです。fsync が速くなると、設定によりますが、データベースのようなシステムは高速になるケースが多くあります。
今回は、内部で何が起きているため時間がかかるのか、ということについて見ていきます。
大まかなスピード
時間がかかる、というのがどの程度であるかということについて、ある程度の感覚をつかむために、簡単に実験をしてみました。
Linux 5.3 で、ext4 という Ubuntu 等でデフォルトで使われているファイルシステムについて、一般的なコスト重視の SSD Crucial SSD 240GB (CT240BX500SSD1Z) を使って fsync にかかる時間を測りました。
手元の環境では、ファイルに 4KB のデータを書き込んで fsync を呼ぶと約 638 us かかりました。
一方、4 KB を書き込む write システムコールは、1.14 us 程度でした。時間あたりの書き込み量や、書き込む位置によりますが、時間に関するスケール感でいうと、write システムコールは fsync と比べるとかなり短い時間で済みます。
機能が異なるので、fsync と write システムコールにかかる時間を比較することに特に意味はありませんが、スピードの感覚として、fsync は比較的時間のかかる処理であるということは言えるかと思います。
fsync の概観
以下の図は、ファイルの書き込み処理の流れをおおまかに示しています。図の詳細については、過去の記事を必要に応じてご参照ください。
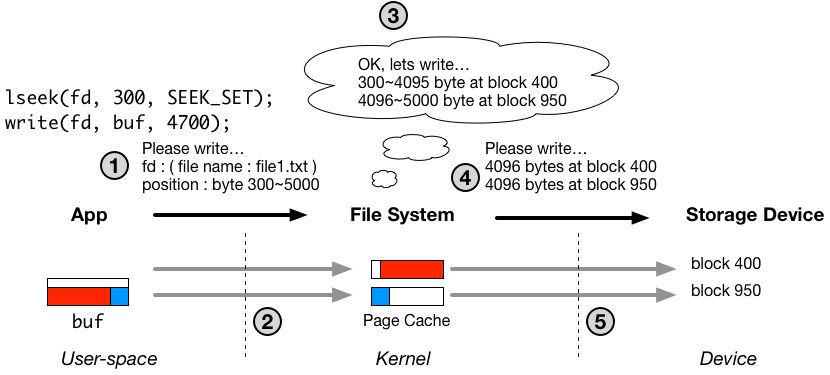
write システムコールが 1.14 us で完了できたのは、過去の記事にある通り、図中の1と2番の処理だけがシステムコール内部で行われ、3、4、5の部分は非同期なスレッドで行われるからです。番号1、2の処理は、主にユーザー空間からカーネル空間へのメモリコピーなので、そこまで時間はかかりません。
一方、fsync の実質的な機能は、明示的に、図中の3から5までの処理を行うように書き込みスレッドにリクエストする(もしくは自分で3から5までの処理を行う)ことです。fsync は、リターンするタイミングでファイルの永続性を保証するために、ディスクへの書き込みを含む3から5までの処理が完了するまで待機する必要があるため時間がかかります。
図では簡略化されていますが、3から5の間には複雑な処理が含まれており、この記事ではそこについて掘り下げていこうと思います。
ストレージデバイスにおける永続性の保証
fsync の速度はディスクのハードウェア特性、特に永続性に関する点に起因するところが多分にあります。
永続ストレージデバイス内の揮発性キャッシュメモリ
現在、一般的に広く使われている HDD や SSD は、永続的な保存領域とは別に、内部的に揮発性メモリでできたキャッシュを持っており、デバイスドライバを通じて送られてきたデータはまず、そのキャッシュに置かれます。それらのストレージデバイスは、キャッシュに置かれたデータを適宜、永続的なデータの保存領域へ移動させていきます。
一般的に、キャッシュへの書き込みは、デバイスの永続的な保存領域への書き込みに比べてかなり高速なため、キャッシュは書き込みの遅延を低減することに大きく貢献します。
しかし、想像がつかれたかと思いますが、ただデータがストレージデバイスのキャッシュに乗っただけでは、転送されたデータが永続的になるわけではありません。
データがキャッシュに乗った状態で、例えば停電が発生し、ディスクへの給電が止まった場合、キャッシュ上にあったデータは、キャッシュが揮発性メモリでできているため消えてしまいます。
永続領域への書き込み順の不確実さ
ディスクを扱うことの難しさの原因の一つに、キャッシュから永続的なデータ保存領域へのデータの移動が、データが転送されてきた順番によらないということがあります。
つまり、ディスクのブロック番号1、2、3番に向けて書き込むべきデータが、1、2、3の順番通りキャッシュに到着したとしても、ディスクは、必ずしも1、2、3、の順番で永続的な保存領域に移動させるとは限らないということです。
ディスクのキャッシュのフラッシュリクエスト
ディスクには、先述の通り2点、
- ディスクは内部にキャッシュを保持しており、ディスクのキャッシュに届いたデータがすぐに永続的になるわけではない
- ディスクがキャッシュから、永続的な保存領域へデータを移動させる場合の順番は、データがキャッシュに届いた順番と同じとは限らない
のような不確実性がハードウェアの特性としてあります。
HDD や SSD のようなストレージデバイスは、このような不確実さにソフトウェア側から対応が可能なように、デバイスのキャッシュ上のデータを、永続的なデータ保存領域へ移動させることを明示的にリクエストできる、フラッシュコマンドを実装しています。
重要な特性として、ストレージデバイス上のキャッシュから、永続保存領域へのデータの移動はとても時間がかかります。なので、フラッシュコマンド自体の発行から完了までの時間も必然的に長くなります。
実は、このフラッシュコマンドが、fsync に時間がかかる大きな要因となっています。以降、なぜ、ファイルシステムがディスクのキャッシュをフラッシュしなければならないのかについて書いていきます。
クラッシュ後の整合性
ファイルシステムにとって、クラッシュ後(例えば想定していない停電後)に、ディスク上に保存されたデータが破損しないということは最重要の機能要件の一つです。特に、そのためには、クラッシュ後のメタデータの整合性が重要になります。
なぜ、メタデータの整合性と fsync が関係あるのかというと、メタデータのディスクへの書き込みが fsync の中で行われるからです。
fsync の内部では、ディスクへの書き込み最中にシステムがクラッシュしてもメタデータの整合性が担保できるような書き込み方法を実装しています。
一般的に、データの整合性を担保する書き込み手法として、ジャーナリングもしくは、ファイルシステムのディスク上のレイアウトをログ構造にする、という2通りの方法が用いられています。
それらの仕組みでは、一つのデータをディスクに書き込むだけで、ストレージデバイス上のキャッシュのフラッシュリクエストを複数回発行する必要があり、そのフラッシュリクエストが fsync に時間がかかる主な要因になっています。
ジャーナリング
今回は、ジャーナリングという仕組みがどのようなもので、なぜストレージデバイスのキャッシュのフラッシュが必要なのかについて見ていきます。
メタデータのディスクへの書き出し
ファイルシステムは、ファイル自体のデータだけでなく、ファイルという抽象化のために必要な様々なメタデータをディスク上に保存しています。
以下の図は、メタデータの例として、あるファイルのディスク上のデータの位置を保持するためのB木です。以下の図の説明を含めたメタデータにつきましては、以前の記事で触れておりますので、よろしければご参照ください。
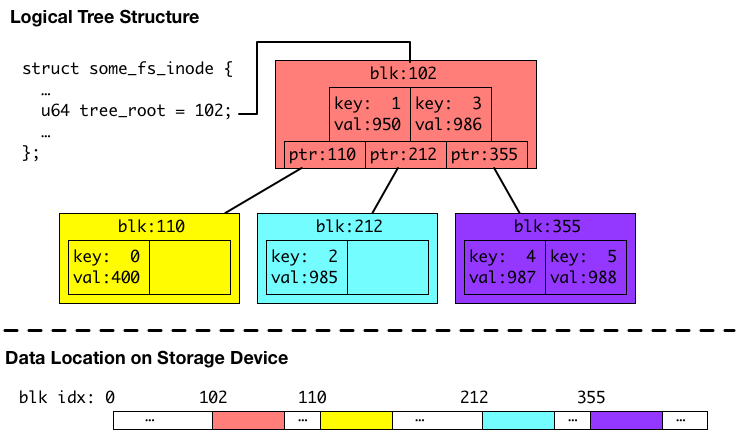
上の図の例のB木は、キーがファイル内のインデックスで、バリューがディスク上のファイルデータの位置のペアを保存しています。このB木の場合は、6つエントリーを保持していて、1エントリーあたり4キロバイトのブロックに対応しているので、24 KB のファイルのディスク上のデータの位置を保持している例になります。
ここでは、さらに4キロバイトファイルを(ファイル内のオフセット 24 KB ~ 28 KB にかけて)追記して、28 KB のファイルになった場合を考えます。この追記に関しては、通常の write システムコール等を通して行うことができます。
4キロバイトのデータがファイルへ追加されると、ファイル内の 24 KB ~ 28 KB (インデックス6)のデータがディスクのどこにあるかを保存するために、B木へ追加されます。ファイルシステムは、今回の例ではなんとなく、新しいデータをディスクの 989 番におくことにしたようです。
今ある B木にキー6、バリュー 989 を追加すると、B木の仕様によって、以下のように形が変わります。(今回の例では、一つの色つきブロック(ノード、リーフ)が2つしかエントリーを保持しませんが、実際は1つのブロックは4KB(もしくはその倍数)で、エントリーはブロックに収まるだけ保持されることにご注意ください。)
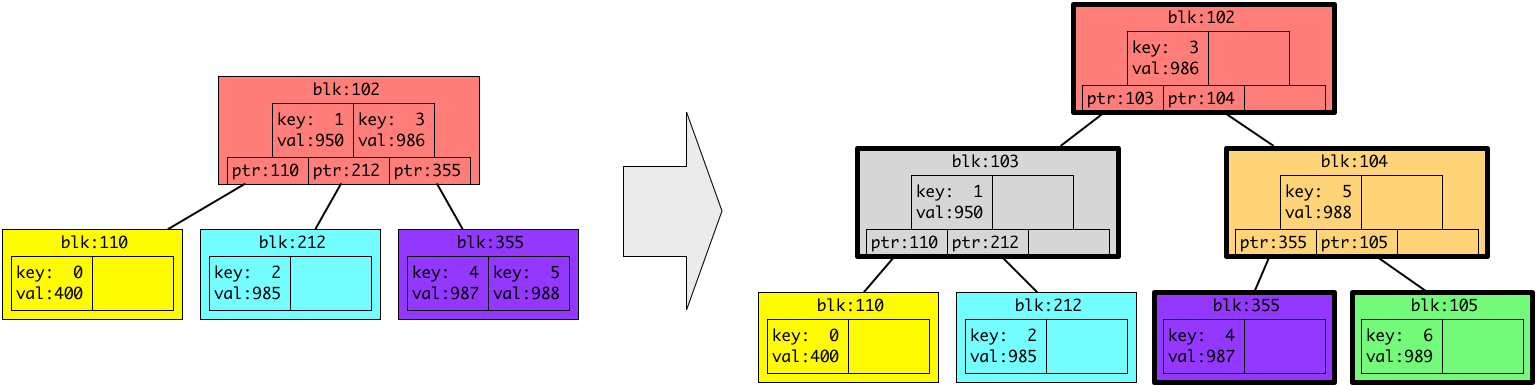
上の図では、新しいデータを保存するために、3つ新しい灰色、オレンジ、緑のブロック(ノード、リーフ)が追加されています。また、太い枠で囲われている色つきのブロックが新しく追加された、もしくは内容が変更されたブロックです。
これらの追加、変更されたB木(メタデータ)は、新しくファイルの 24 KB から 28 KB にかけて追記されたファイルのデータと一緒にディスクへ書き込まれる必要があります。
B木がディスクへ書き込まれる様子を図にすると以下のようになります。このメタデータのディスクへの書き込みは、非同期の書き込みスレッドの中で実行されます。また、fsync は、この書き込みが完了するまで待機します。(もしくは、fsync のシステムコールコンテキストで実行するように実装することもできます。)
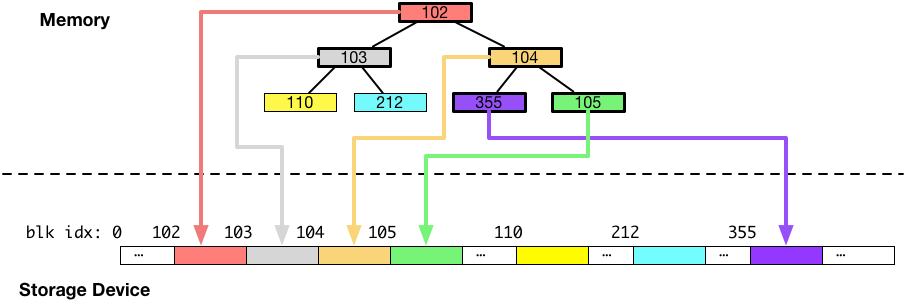
上図のように、ディスクをデータを書き込むことは一見簡単そうなのですが、書き込み中にシステムがクラッシュしてもB木のようなメタデータの整合性を失わないようにするには追加の配慮が必要になります。
回避したい状態
上図の例と同じB木の追加変更箇所をディスクに書き出している間に、システムがクラッシュすると、B木がどのような状態になる可能性があるかについて見ていきます。
今回は、ディスクのブロック番号 103 番に書かれるはずだったデータ(灰色のブロック)だけが、書き込みに失敗し、それ以外の部分が成功した例を考えます。書き込みに一部失敗した例を図にすると以下のようになります。
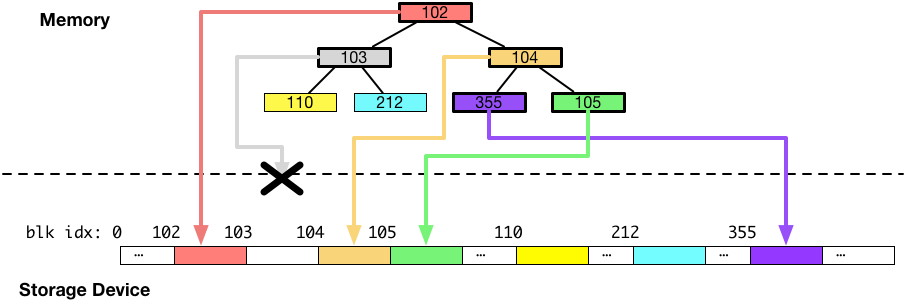
この状態で、システムを再起動すると、DRAM にあったデータは全て消えてしまっているので、ディスクの上にある情報だけでB木を再構成することになります。しかし、103 番に書かれるはずだったデータが書かれていないため、B木を再構成しようとすると以下のような状態になります。
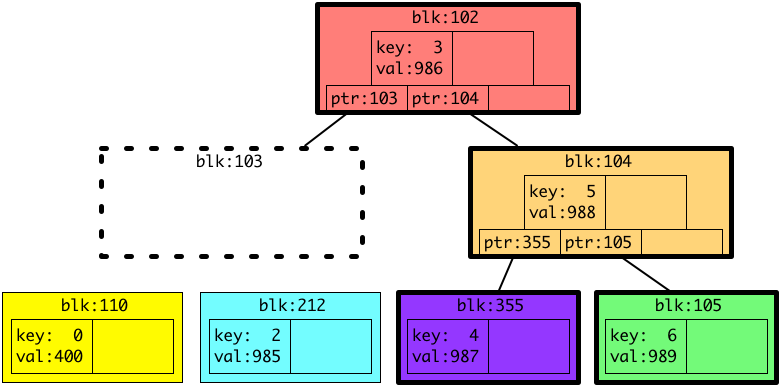
B木でデータを探索する場合には、ルートからリーフ(図では上から下)へ向けて探索を行いますが、リーフへのポインタを保持しているはずの 103 番のブロックに書かれるべきデータが書かれなかった結果、ディスクに書かれなかったキー1に対応するバリューだけでなく、黄色と水色のブロック(リーフ)へのポインタを失ってしまい、B木としては、キー0、1、2に対応するバリューへのアクセス方法を完全になくしてしまっています。
このように、システムのクラッシュは、メタデータの欠損を引き起こす可能性があり、結果として、保存されたファイルのデータへアクセスできなくなってしまうことがあります。
上の例では、ファイルを読み込もうとしても、インデックス0〜2(0 B ~ 12 KB目)までのデータは、B木が破損してディスク上のデータの位置がわからなくなってしまったので、読み取ることができません。
ジャーナリングによる整合性の担保
ジャーナリングは、上の例のような、書き込みが中断された結果発生する、データの不整合を回避するための仕組みです。
ジャーナリングによって達成する機能は、クラッシュ後に、書き込み対象の複数のデータブロックが、全て書き込まれる、もしくは、全て書き込まれない、という2通りのみの状態に制限することです。
上のような不整合の問題が起きるのは、書き込み対象の複数のデータブロック(上の例の場合では、B木の追加変更ノード・リーフ)の一部だけがディスクへ保存されることによって起こります。
例えば、クラッシュによって、書き込み対象の複数のデータブロック全てが一切ディスクに書き込まれなかった場合は、最新の書き込もうとしていたデータ自体は消えてしまいますが、メタデータとしての不整合は発生しません。上のB木の例であれば、24KB~28KB に追記したデータ自体の保存は失敗していますが、B木の整合性は壊れていないので、最初からあった 0 ~ 24 KB のデータの位置に関する情報を失うことはありません。
このように、fsync が完了するまでは、write システムコールで書き込んだデータが消えてしまう可能性は、ジャーナリング等の機能を持ってしても拭いきれないものであるということにご留意ください。
ジャーナリング等の仕組みは、複数のデータブロックの書き込みが全て成功するか、失敗するかの2パターンに絞ることで、メタデータの破損を防ぎ、すでに保存されたはずのデータが、システムのクラッシュによってアクセスできなくなる、ということを回避することを目的としています。
ジャーナリングの実装
ジャーナリングの基本的なアイデアは、2回同じデータをディスクへ書き込むことです。なぜ2回データを書き込むことで不整合が回避できるのかについて書いていきます。
ジャーナリングを採用したファイルシステムは、ディスク上にジャーナル領域という、専用の領域を用意します。
ジャーナリングファイルシステムは、メタデータ(例えば、B木のノードやリーフ)のような、複数のデータブロックに分かれていて、かつ、一度にディスクに書き込みたいデータをディスクに書き出す際には、最初にそれらを全て一度、ジャーナル領域に書き込みます。図にすると以下のようになります。(下図の例では、ジャーナル領域はブロック番号 30 周辺です。)
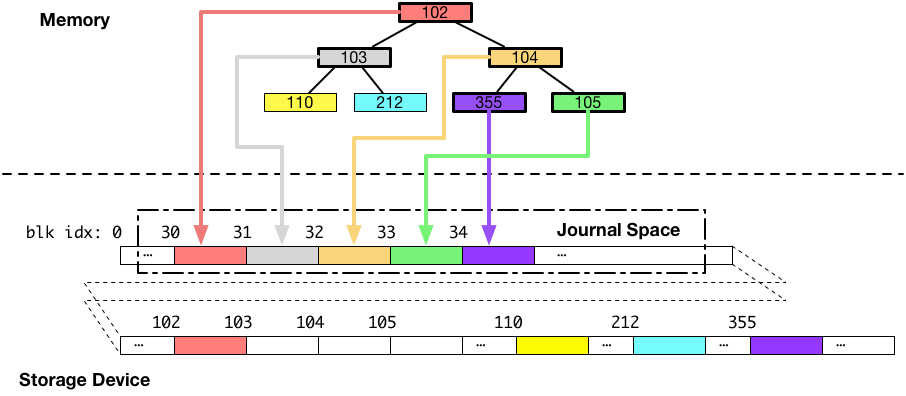
次に、ジャーナル領域へのデータの書き込みが完了した後に、同じデータを本来書き込みたいと思っていた場所に書き込みます。図にすると以下のようになります。
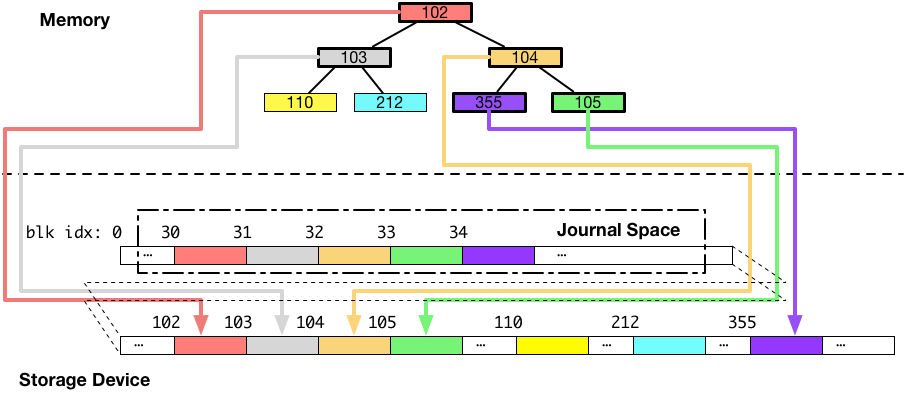
以上がジャーナリングを採用したシステムのデータの書き込みの流れです。次に、書き込み途中でシステムがクラッシュして、書き込みが中断された場合について考えます。
クラッシュからの回復
パターン1
まず、一つ目のパターンとして、ジャーナル領域への書き込み途中にクラッシュが発生して、ブロック 103 番(灰色のブロック)へ書き込まれるはずだったデータが書き込まれなかったとします。以下の図は、そのような場合、データがどのような状態になるかを示しています。
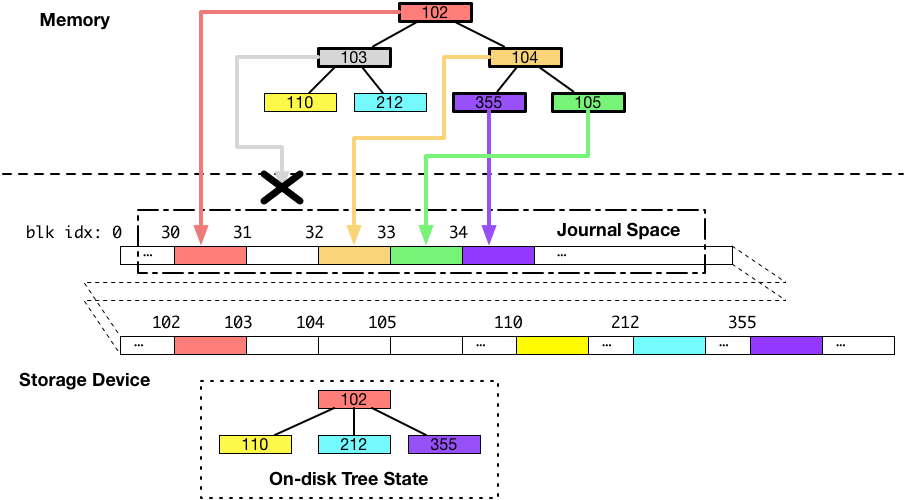
上の図では、B木本体のデータを保存しているディスク上のブロックに対して一切の書き込みがされていないことがポイントです。この場合が、複数のブロックをディスクへ書き込もうとしていたけれど、全ての書き込みに失敗した、パターンになります。
ご覧の通り、B木は古い状態のままで、整合性が保たれています。
この場合、クラッシュ後にファイルシステムはジャーナル領域のデータを破棄するだけで、通常通り動き始めることができます。
パターン2
次のパターンは、ジャーナル領域への書き込み完了後に、実際に書き込みたいと思っていた書き込み先にデータを書き込もうとしている時にクラッシュが発生した場合です。同じく 103 番に書こうとしていたデータが書かれなかった場合について考えます。以下の図が、その場合の状態を示しています。
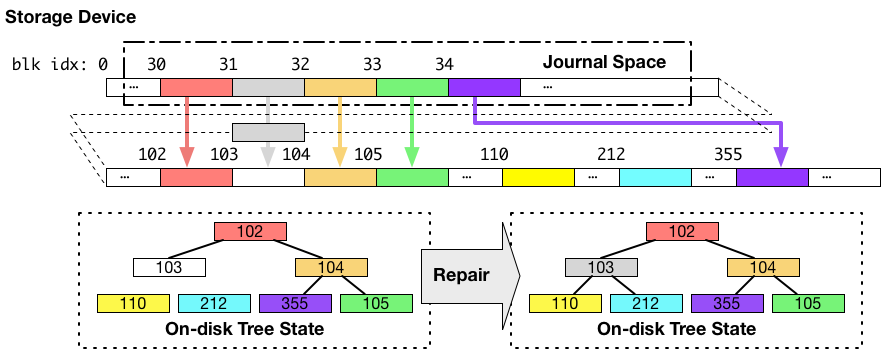
再起動の直後のB木の状態は、上図左下のようになっており、不整合な形になっています。この段階では、データブロック番号 110、103、212 にあるはずのデータへのアクセスが失われています。
ですが、この時に、全ての書き込まれるべきデータはジャーナル領域に保存されています。
なので、システムの再起動後、ファイルシステムはジャーナル領域から、本来データを書き込みたかった場所へコピーすることで、書き込み対象だった全てのデータブロックを目的の宛先に書き込んだ状態にします。この場合は、書き込み対象のデータブロックの書き込みが全て成功したパターンになります。
この再起動後のジャーナル領域からのデータコピーの結果、上図の右下のように、整合性のとれたB木がディスクに現れます。
省略箇所
省略した点として、実装によりますが、書き込みを始める際には、デスクリプタブロックと呼ばれるブロックを先頭として、続けて書き込み対象データブロックを書き込んだのち、コミットブロックと呼ばれるジャーナル領域への書き込み完了を示すブロックを最後に追記するようになっています。このコミットブロックによって、ジャーナル領域の完全性を判断し、不完全であれば、クラッシュ後はジャーナル領域のデータを破棄、そうでなければジャーナル領域のデータを、本来書き込みたかった先へコピーします。ジャーナル領域から、本来コピーされるべきだったディスクの位置については、先頭におかれるデスクリプタブロックに書かれます。
ジャーナリングにおける書き込み順番保証の必要性
かなり長くなってしまいましたが、なぜジャーナリングに永続ストレージデバイスのフラッシュコマンドが必要か書いていきます。
だいぶ上の方に書いてある「ストレージデバイスにおける永続性の保証」というところを思い出していただきたいのですが、ディスクには、データを送りつけただけでは、データはキャッシュに乗るだけでいつ永続的になるかわからない、かつ、キャッシュに置かれたデータがどの順番で永続領域へ移動されるかも不確定です。
今回の記事のポイントは、上記のジャーナリングの仕組みを適切に実装するためには、キャッシュ上のデータが永続領域へ移動される順番を制御する必要があるという点にあります。
書き込みの順番が制御されない状態で、ジャーナリングを実行し、クラッシュが発生した場合どのような状態になる可能性があるかについて、以下のような例を考えます。
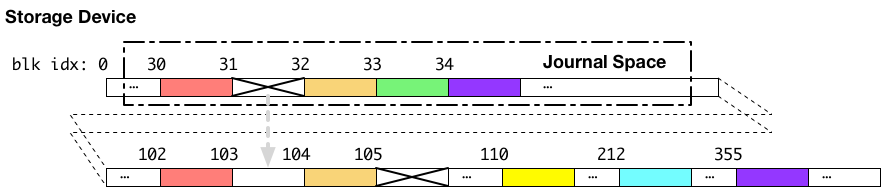
上記の例では、ジャーナル領域への書き込みが完了し、書き込み順序の制御を行わないまま、続けて本来書き込みたかった場所へ書き込んでいる最中にクラッシュが発生した場合の例です。この例では、ジャーナル領域のデータと、本来書き込みたかった書き込み先へ向けたデータの両方が、ストレージデバイス内部のキャッシュに乗った状態でクラッシュを経験しています。結果として、ジャーナル領域のブロック番号 31 に置かれるべきだった、ブロック番号 103 へ書かれるべきデータと、ブロック番号 103 に書かれようとしていたデータの2つの書き込みに失敗したとします。
この場合には、見て明らかな通り、ジャーナル領域のブロック番号 31 から、ブロック番号 103 番へデータをコピーしてもB木は復元できません。ジャーナル領域のブロック番号 31 への書き込みが失敗しているからです。
なぜこのようなことになるかというと、ジャーナル領域のデータが永続領域へ移動される前に、本来のデータ部への書き込みを開始してしまったからです。なので、本来の書き込みたかった場所へデータ書き込むのは、必ず、対応するジャーナル領域のデータが、ストレージデバイスのキャッシュから、永続領域へ移動された後である必要があります。
つまり、ジャーナル領域のデータと、本来書き込みたいデータについて、ストレージデバイスの永続領域へ書き込まれる順番の制御が必要になります。
ジャーナリングファイルシステムは、この書き込み順の制御のために、先述のフラッシュコマンドを利用します。
具体的には、ジャーナル領域へのデータ書き込みの後に、フラッシュコマンドをディスクに対して発行し、フラッシュの完了通知を受け取った後、本来のデータ領域への書き込みを行います。このフラッシュは、書き込みバリアとも呼ばれます。またさらに、ファイルシステムは、そのデータの書き込みの後にもう一度永続性の担保のためにディスクのキャッシュのフラッシュを行います。
このように、ストレージデバイスのキャッシュのフラッシュにはただでさえ時間がかかるにもかかわらず、1度の fsync に対して複数回実行されなければならない、という点が fsync に時間がかかる理由でした。
fsync を高速化する研究
ファイルシステムの研究コミュニティでは、ストレージデバイスのキャッシュのフラッシュに起因する遅延をなんとかして fsync を速くしようとする仕組みが提案されています。今回の記事が論文を読む時の理解の助けになれば嬉しいです。
- Barrier-Enabled IO Stack for Flash Storage FAST'18
- Optimistic crash consistency, SOSP'13
- Consistency Without Ordering, FAST'12
ext4 の fsync がどのようになっているかは、"Barrier-Enabled IO Stack for Flash Storage" の論文の 2.3 Analysis: fsync() in EXT4 の章を読むとわかるかもしれません。
その他参考資料
- Explicit volatile write back cache control Linux のストレージデバイスのキャッシュのフラッシュについての資料。
- Ext4 Filesystem 3. Options の barrier のマウントオプションの箇所には、書き込みバリア(フラッシュ)を有効、無効にする設定と、その効果が書いてあります。
- 詳解 Linuxカーネルには ext3 のジャーナリングに関する記述があります。
- ジャーナリングファイルシステムの構造を利用した非同期リモートミラーリングの高速化, 情報処理学会論文誌コンピューティングシステム 2005 年:fsync の速度に重点をおいた研究ではありませんが、ジャーナリングの実装に関して日本語の解説があります。
追記
まとめ
fsync になぜ比較的長い時間がかかるのか?
ファイルシステムのメタデータについて
ファイルシステムのメタデータについて調べたことを書いてみようと思います。
勉強のためにファイルシステム関連の資料を見ていると、メタデータの種類に関して列挙しているものはたくさん見つかったのですが、それらがどのように保存されるかについての記述をあまり見つけられず理解に苦しんだ覚えがあるので、そこについて書いていこうと思います。
ファイルのデータの位置
今回は、具体的な例から始めたいと思います。
以下は、ファイルの読み込み処理の流れの図です。この図についての詳細については、以前の記事に書いてありますので必要に応じてご参照ください。
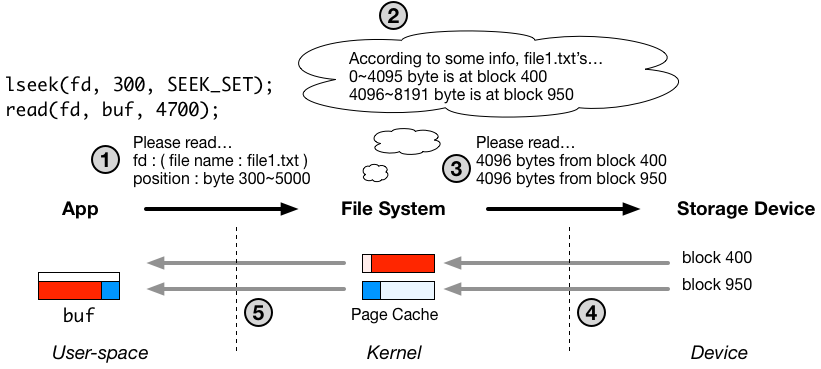
上記の例では、アプリケーションが、read システムコールを通じて、file1.txt というファイルの 300 バイト目から 5000 バイトにかけて読み込もうとしています。
ファイルシステムは、このリクエストを受け、ディスクからそれらのデータを読み出して、アプリケーションへ渡してあげます。
ポイントとして、ファイルシステムは、file1.txt というファイルの 300 バイト目から 5000 バイトにかけてのデータがディスクのどこにあるか、を知っている必要があります。
この位置に関する情報がメタデータの一例になります。メタデータと呼ばれるものには、ファイルのパスや、作成日時も含まれますが、今回は、このファイルデータの位置に関する情報について、特にわかりやすいと思ったので掘り下げていきます。
以前の記事にもあるとおり、多くのファイルシステムは、ファイルを4キロバイトごとに区切ってページ単位で管理します。ファイルデータのディスク上の位置についても、各4キロバイトのブロックごとに位置を記録されることが多いと思います。
また、ファイル内のブロックは、よく4キロバイトで分割したインデックス番号で表現されます。
このようなファイルデータのディスク上の位置に関する情報はテーブルとして表現できます。例として、図中の file1.txt のデータは以下のようなマッピングで保持されているとします。
今回は、ディスクの1ブロックを4キロバイトとしています。
| ファイル内のインデックス | ディスク上のブロック番号 |
|---|---|
| 0: (0KB~4KB) | 400 |
| 1: (4KB~8KB) | 950 |
| 2: (8KB~12KB) | 985 |
| 3: (12KB~16KB) | 986 |
| 4: (16KB~20KB) | 987 |
| 5: (20KB~24KB) | 988 |
上記のテーブルを参照すると、システムコールでリクエストされた 300 バイトから 5000 バイトまでのデータのうち、300 バイトから 4KB まで(インデックス0)はディスク上のブロック番号 400 に、4KB から 5000 バイトまで(インデックス1)はブロック番号 950 の位置にあることがわかります。
図の例では、位置を取得した後に、デバイスドライバを通じて、対応するデータをページキャッシュに読み込んでいます。
メタデータの保存について
このような、データの位置に関するようなメタデータはどのように保持されているかを見ていきます。
ポイントは、ファイルシステムは、ファイルのコンテンツのデータだけでなく、このテーブルもディスクに一緒に書き込んで保存しておく必要があるということです。メモリ( DRAM )上のデータは、コンピューターの電源が切れると消えてしまうため、再起動しても保存したファイルのコンテンツにアクセスできるようにするためには、このディスク上のデータの位置に関する情報を保持するテーブル自体もディスクの上に書いておかなければなりません。
ディスクの上で、テーブルのようなキーとバリューのペアを保存する場合には、よくB木のようなデータ構造が利用されます。B木自体の詳細については他の資料をご参照ください。
以下に、ディスク上に保持されるB木の例を図にしました。実際には、色つきの四角いブロックのサイズは、4キロバイト(もしくは4キロバイトの倍数)で、かつ図では各ブロックに2つしかエントリーがありませんが、実際は4キロバイトいっぱいに収まるだけエントリーが入ることにご留意ください。
図のB木は、上記のテーブルの内容を反映したものになっています。図中のツリーは、キー(ファイル内のインデックス)0〜6と、対応するバリュー(ディスク上のブロック番号)を保持しています。
ディスクの上にB木のようなデータ構造を保存する際には、メモリ上で完結するデータ構造のプログラミングと異なる点があります。通常メモリ上で完結するツリーであれば、ノードやリーフへのポインタは仮想アドレスですが、ディスク上に保存されるツリーの場合には、ポインタをディスク上のブロック番号として保存する必要があります。
図の例では、まず inode が、ツリーのルートが保持されているディスク上のブロック番号を保持しています。(この inode 自体もメタデータとして、また別途ディスクの上に保存されています。)
(例の図では、inode に木のルートのポインタを紐付けるように書いてありますが、実際はルート自体を inode に含めてしまう実装のほうが多いかもしれません。)
例えば、テーブルを参照してインデックス0(ファイルの 0 KB目から 4 KBまで)のデータがディスクのどこにあるか知りたい場合には、まずはじめにルートの保存されているディスク上のブロック(今回は 102 番、 赤色のブロック)からデータをメモリに(まだメモリにロードされていなければ)読み出します。
次に、ルートに保存されている情報を見ると、B木の仕様から、キー1より小さいキー0に対応するバリューを得るにはディスク上のブロック番号 110 に保存されているノード(リーフ、黄色のブロック)をたどる必要があることがわかります。その次には、ブロック番号 110 に保存されているデータをメモリへ読み込み、その中を見ていきます。今回の例では、探していたキー0に対応するエントリーが含まれていたのでここで探索を終了し、結果として、バリュー 400 を取得します。
このように、ディスク上のデータ構造は、ポインタが仮想アドレスでなく、ディスク上のブロック番号になっているのが特徴です。連続的なデータブロックの集合であるディスクの上にデータの配置を図示すると、上図の点線以下の部分のようになります。
このように、ファイルシステムは、ファイルのコンテンツのデータ以外にこのようなB木のようなデータ構造をいくつもディスクに書き込んで保存しています。そのようなデータは総称してメタデータと呼ばれています。
その他のメタデータ
他には、典型的に inode やファイルのパスの情報はメタデータとして取り扱われます。ファイルのサイズ、作成時間等については inode の構造体自体に含まれることが多いと思います。
他に重要なものとして、ディスクのどの箇所が使われているかという、ディスクの仕様状況に関する情報もメタデータに含まれます。こちらはビットマップとして表現されることが多いかもしれません。
ポイントとして、それらのようなメタデータも、B木やリストのようなデータ構造を通して紐付けられ保存されます。
ファイルのディスク上のデータの位置は inode から辿れるようになっていますが、ファイルシステム全体の例えば inode を含むメタデータは、(多くの場合パーティションの最初に位置する)スーパーブロックを起点として辿れるようになっています。
実際のファイルシステムではどうなっているか
今回見ているファイルのディスク上のデータ位置に関する対応は、例えば、Linux で広く利用されている ext4 ファイルシステムでは、extent tree というB木っぽいデータ構造で管理されています。主に、extent tree では、ファイル内、ディスク上両方で連続的に保持されているブロックの範囲を保持するようになっています。これにより、位置を記憶するために必要なディスク上の領域が削減できます。
例えば、今回の例としているテーブルは6ページ(24 キロバイト)分のデータのマッピングを保持するために6つテーブルにエントリーが必要ですが、extent tree であれば、以下のようにエントリーは3つで済みます。
| ファイル内のインデックス | ディスク上のブロック番号の開始位置 | 範囲 |
|---|---|---|
| 0: (0KB~4KB) | 400 | 1 |
| 1: (4KB~8KB) | 950 | 1 |
| 2~5: (8KB~24KB) | 985 | 4 |
この最適化は、大きなサイズのファイルを扱う時に、メタデータのサイズが大きくなり、ファイルのコンテンツのデータ自体の保存領域を圧迫しないようにするために重要です。
まとめ
メタデータは、ディスクの上に保存されることを想定したデータ構造を用いて、スーパーブロックから辿れる形で保存されます。
そのようなディスク用のデータ構造は、ポインタの値が仮想アドレスではなくてブロック番号であることが特徴としてあげられます。
ファイルシステムについてざっくり理解する
ファイルシステムについて勉強したことについて書いてみようと思います。
今回は、概観について、ふわっと理解できるような資料になるように書いていきたいと思います。 読んでいただくと、read、write システムコールの裏側で何が起きているか若干想像がつくようになるかもしれません。
これから勉強をしてみようと思われる方の参考になれば幸いです。
ファイルシステムの概観
ファイルシステムについて見ていく時には、3つの層を考えると良いと思われます。
カーネル空間のファイルシステムが、ユーザー空間のアプリケーションと永続ストレージデバイス(ディスク)の間にたって、ファイルという抽象化を提供するというのが大まかな構成になります。
以後、簡単のため、永続ストレージデバイスについては、ディスクと書きます。
インターフェース
次に、各層の間でのコミュニケーションのインターフェースについて考えます。
アプリケーションとファイルシステム間のインターフェース
アプリケーションとファイルシステムは、主に read、write システムコールを通じてやりとりを行います。
read と write システムコールの定義は、以下のようになっています
ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t count);
上記のシステムコールはそれぞれ3つ引数があり、fd はファイルデスクリプタ、buf はユーザー空間のメモリアドレス、count は読み書きのバイト数です。
システムコール自体の定義は上のようになっていますが、アプリケーションはシステムコールを通じて、
あるファイルの、ある箇所を、N バイト読み書きしてください
ファイルシステムとディスク間のインターフェース
ファイルシステムを含む OS の視点からは、ディスクは連続的な固定サイズのデータブロックの集合として見えます。ディスクは、通常、データブロックに対してブロック(セクター)番号をもとに読み書きのアクセスが行えるようになっています。
ファイルシステムの役割
重要なのは、ディスク自体は、上記の番号ベースのインターフェースのように、言われた通りにデータを指定された場所へ読み書きすることしかできないので、ファイルという概念を認識できないことです。
言い換えると、アプリケーションが、あるファイルを読み込んでくださいというリクエストをディスクに対して直接送りたくても、ディスクからするとデータはあるけど、どれがファイルのどの部分かわからないということになります。
指定されたファイルの指定箇所からデータを読み取る、ということをするためには、ディスクという連続的なデータブロックの、どこに要求されたデータがあるか、という位置に関する情報が必要となります。
ファイルシステムの主な仕事は、まさにその、ディスク上のどこになにが置いてあるかを記録しておき、アプリケーションの要求に応じてデータを読み出す、もしくは書き込む、ということになります。
読み書きの流れ
上記の点を踏まえて、ファイルシステムの読み書きの大まかな流れを図にしてみました。
図中の番号については、ざっくりした処理の順番なのですが、処理の順番が時と場合による部分が多分にあるため、図示されている番号は全ての場合に適応されるわけではないことにご留意ください。
書き込み処理
まず、書き込みから見ていきます。
図は、アプリケーションが write システムコールを通じて、file1.txt という名前のファイルの 300 バイト目から 5000 バイトにかけて、4700 バイトの書き込みを行うときの例を示しています。
図中の fd は file1.txt というファイルのファイルデスクリプタであると思ってください。
また、図中の lseek は、書き込みの開始位置をファイルの 300 バイト目に指定していることを明示するために書いてあります。
まず、write システムコールは、ファイルシステムの視点からは、file1.txt への 300 バイト から 5000 バイトまでの書き込みリクエストに見えます(図中番号1)。
write システムコールによって、処理のコンテキストがカーネル空間に切り替わると、まず始めに、ページキャッシュと呼ばれるカーネル空間内のメモリ領域に、アプリケーションが書き込みをリクエストしている引数 buf で指定されたデータをコピーします。この処理は、図中番号2の部分にあたります。
ここで一つポイントは、ファイルシステムは多くの場合、4キロバイト (厳密には 4096 バイト) 単位でファイルのコンテンツデータを管理しています。これは、OS がメモリを4キロバイトごとに区切ったページと呼ばれる単位を元に管理していることに起因しているように思われます。
今回の例では、一つ目のページキャッシュのページは 300 バイト目から、4095 バイト目までを保持(赤い部分)、二つ目のページは、4096 バイト目から 5000 バイト目にかけてのデータ(青い部分)を保持します。このとき、アプリケーション側では、4キロバイトのアラインメントに対して配慮する必要はありません。
ここまでが write システムコールで行われる処理で、図中の番号3以降は、実装次第ですが、必ずしもシステムコールの中で実行されません。
図中の1と2番の処理に関しては、アプリケーションとファイルシステム間のやりとりですが、3番以降は、ファイルシステムとディスク間のコミュニケーションです。
図中番号3以降のファイルシステムとディスクとのやりとり、特に書き込みは、多くの場合、アプリケーションとは独立した、カーネルスレッドで実装され、アプリケーションの処理とは非同期でディスクの書き込みが行われます。ディスクへの書き込みは一般的にとても時間がかかるため、書き込みを外部のスレッドへ任せることで、アプリケーションへのディスク書き込みの遅延の影響を抑えようとする意図があります。
書き込みスレッドは、定期的に(例えば30秒ごと)、もしくはページキャッシュが新しい書き込みデータでいっぱいになってしまった場合に OS によって書き込みを始めるように促されます。そのときに、初めて図中3番の処理が開始されます。
書き込みスレッドがまず始めにすべきことは、新しいデータをディスクのどこに書き込むか決めることです。この書き込み位置の決定はファイルシステムの設計において非常に重要で、性能や機能に大きく影響があります。 (詳細は別途記事を書く予定です。)
今回の図の例では、ファイルシステムは、なんとなくページキャッシュの1ページ目、300 バイトから 4095 バイト目まではディスク上のブロック番号 400 へ、2ページ目は 950 へ書くことにしたようです。
ここで重要なのが、ファイルシステムは、この、file1.txt の1ページ目(最初の4KB)がブロック番号 400、2ページ目(4キロバイトから8キロバイトにかけて)がブロック番号 950 に書かれている、という情報も保持しなければならないということです。このような情報はメタデータと呼ばれ、メモリ( DRAM ) 上のデータが消えてしまった再起動後にもアクセス可能なように、ファイルのコンテンツがディスク書き込まれるときに、一緒に書き込まれます。このメタデータの管理は、ファイルシステムの設計において非常に重要で難しい部分になります。(詳細は複雑なので、こちらも別の記事として書こうと思っています。)
書き込み先を決定したら、次は、デバイスドライバを通じて、ページキャッシュ上のデータをディスクへ書いてもらうようにリクエストを送信します(図中番号4)。
その後、リクエストに応じて、データが指定したディスク上の位置に書き込まれます(図中番号5)。
ここまでがおおまかな、ユーザー空間のデータがディスクまで送り届けられるまでの流れです。
省略した点として、図の write システムコールの例は、ページの一部にしか書き込みを行わないため、実際は、データがページキャッシュになかった場合、0 〜 299 バイト目と、5000 〜 8191 バイト目までをページキャッシュへロードするために、図中番号1と2の処理の間にディスクからの読み込みが行われます。ファイルサイズが0で対応するデータがディスク上にないことが明らかな場合はこの限りではありません。もしくは、書き込み前のファイルサイズが1ページに収まっていた場合は、読み込みは最初の1ページのみだけになります。また、今回の例のように書き込みがページの一部ではなく、1ページ全体を上書きする場合には、この読み込みは不要になります。
読み込み処理
次に、読み込み処理を見ていきます。
今度の例では、アプリケーションが read システムコールを使って、先ほど file1.txt へ書き込んだ 300 〜 5000 バイト目までのデータを読み込みます。最初の段階ではページキャッシュにデータがないと思って見てください。
まず、読み込みをリクエストするためにアプリケーションは read システムコールを発行します。(図中の番号1にあたります。)
実行コンテキストがカーネル空間へ移行し、ファイルシステムは、対応するデータがどこにあるかについて考えます。当たり前ですが、データはファイルシステムが自分で書き込んだ場所にあります。書き込み側の例では、300 〜 4095 バイト目までは、ディスク上のブロック番号 400 番に、4096 〜 5000 バイトにかけてはブロック番号 950 に書き込みました。この位置に関する情報は、ファイルシステムがメタデータとして保持しており、このように、読み込みの際には参照されます。(保持の形式等については別の記事に分ける予定です。)
メタデータを参照することによって、ファイルシステムは file1.txt の 300 〜 4095 バイト目までは、ディスク上のブロック番号 400 番に、4096 〜 5000 バイトにかけてはブロック番号 950 にあることがわかりました。これが図中2番です。
データの場所がわかったので、デバイスドライバを通じて、ディスクからの読み出しをリクエストします(図中3番)。このとき、メモリ上の読み出し先としてページキャッシュを2ページ分新たに確保しておきます。
ディスクからの読み出しリクエストの結果、データは、ページキャッシュへ読み出されます(図中4番)。
最後に、ファイルシステムは、ページキャッシュに読み込まれたデータを、read システムコールの引数 buf で指定されたユーザー空間のメモリにコピーします(図中5番)。
これによって、アプリケーションは、ディスクに保存されたデータを取り出すことができました。
もう少しだけ厳密な読み込みの流れ
もう少しだけ厳密に読み込み処理の流れを書くと以下のようになります。

ポイントとして、ページキャッシュに前回の読み込みもしくは書き込みによって、すでに必要なデータがあった場合には、read システムコールはページキャッシュからデータをユーザー空間へコピーするだけで完了します。この場合、read システムコールの中で、ディスクからの読み取りは不要なので、ディスクへデータを読み取りに行った場合と比べてかなり遅延が短縮されます。
物理メモリのサイズが大きいほど、ページキャッシュも多く用意できるため、大きい容量のメモリを購入すると、ファイルからの読み込みの時間が短縮できる場合が増える可能性があります。 特に、ディスクが遅いほど効果が高そうです。
その他の情報
ふわっと理解するプロセススケジューラ実装のコンセプト
OS のプロセススケジューラの実装について調べました。
UNIX や Linux のような洗練された OS のスケジューラの実装はとても複雑で理解するのが大変ですが、スケジューラ実装の根本的なコンセプト自体は、少し単純化して表現できそうに思いました。
今回は、実装のコンセプトをつかむために、大幅に単純化した 60 行程の疑似コードを書いてみました。これからスケジューラのコードを読もうとされる方の参考になれば幸いです。
導入
汎用 OS は複数のプロセス(プログラム)を並列で実行することができます。この機能のおかげで、1つのパソコンで、音楽プレイヤーソフトで音楽を聞きながら、オフィスソフトで仕事ができます。
並列実行は、1つの CPU で実行するプログラムを高速に切り替えることで実現されます。この切り替えは、OS のプロセススケジューラが行っています。
不思議なこと
通常、プログラムは概ね以下のように、そのプログラムのロジックだけを記述し、ループを回していると思います。
while (1) { // application logic }
上のプログラムの中に、プロセススケジューラや、別のプログラムへ処理を移行する処理は記述されていません。
にもかかわらず、不思議なことに、OS はプロセススケジューラの処理を実行し、プロセスを適宜切り替えることができます。
タイマ割り込み
上記のような、閉じたループから、スケジューラの処理へ移行するためには、CPU に備わるタイマ割り込みの機能を使います。
ソフトウェアは、CPU に対して、タイマ割り込みハンドラと呼ばれる関数を設定できます。
タイマ割り込みが設定された場合、CPU は一定時間ごとに、現在実行されているプログラムの処理を停止して、タイマ割り込みハンドラへ処理をジャンプさせます。
多くの OS では、タイマ割り込みハンドラにプロセスの切り替え処理の入り口を実装します。
プロセス切り替え以外の仕事
スケジューラは、プロセスを切り替えるだけではなく、プロセスを、いつ、どれだけ実行するかを決定します。
疑似コード
上記のような、タイマ割り込みを入り口にして、プロセスの切り替えを行うスケジューラの実装を、簡略化した疑似コードにしてみました。
- 疑似コードでは、1CPU のみで実行されることを想定しています。
- 各プロセスは、一定時間実行されたら次のプロセスへ切り替えられるような実装を意図しています。
- 疑似コードなので、厳密ではないことに注意してください。
struct task { struct list_head _l; // キュー用のリストに紐付けるための構造体 uint64_t sum_exec_time; // 実行された合計時間を保存 }; struct runqueue { struct task *curr; // 現在実行中のプロセス struct list_head queue; // キュー用のリスト }; struct runqueue *rq; void enqueue_task(struct task *p) { list_add_tail(&p->_l, &rq->queue); // プロセス構造体をキューの最後へ入れる } void dequeue_task(struct task *p) { list_remove(&p->_l); // プロセス構造体をキューから取り外す } struct task *pick_next_task(struct task *prev) { struct task *next = list_first_entry(&rq->queue); // キューの先頭を取得 enqueue_task(prev); dequeue_task(next); } void switch_to(struct task *prev, struct task *next) { // architecture dependent } void schedule(void) { struct task *prev, *next; prev = rq->curr; next = pick_next_task(prev); rq->curr = next; switch_to(prev, next); } static uint64_t prev_interrupt; void timer_interrupt_handler(void) // 定期的に実行される { struct task *curr = rq->curr; uint64_t now, delta_exec; now = TIMER_NOW(); // 現在時刻を取得 delta_exec = now - prev_interrupt; // 経過時間を取得 prev_interrupt = now; // 次回のために現在時刻を保存 curr->sum_exec_time += delta_exec; // 経過時間を加算 if (curr->sum_exec_time > IDEAL_RUNTIME) schedule(); }
データ構造
スケジューラが扱うデータ構造は主に2種類で、プロセスに対応する構造体と、実行キューに対応する構造体です。
疑似コードの中では、プロセスに対応する構造体は、struct task で、キューに対応するのは、struct runqueue です。
実行キューは、プロセスのキューとなっており、enqueue_task、dequeue_task でそれぞれエンキュー、デキューを実装しています。
プロセスに対応する構造体は、fork システムコールが実行されたときに生成され、実行キューにエンキューされます。また、プロセスが終了した場合と、スリープや入力待ちのために待機する場合に、対応するプロセス構造体は実行キューから取り外されます。プロセスが待機状態から、イベントを受け取って実行可能状態に戻ると、再度、実行キューに入れられます。
処理の流れ
1. プロセスの実行時間を計測
タイマ割り込みハンドラ( timer_interrupt_handler)の中で、現在実行中のプロセスが、どれだけの間実行されているかを計測します。以下のように、前回の割り込みからの経過時間を、プロセス構造体に紐付いた変数に足していきます。
now = TIMER_NOW(); // 現在時刻を取得 delta_exec = now - prev_interrupt; // 経過時間を取得 prev_interrupt = now; // 次回のために現在時刻を保存 curr->sum_exec_time += delta_exec; // 経過時間を加算
2. プロセスが実行された時間が、意図した時間を超過したか確認する
この前のステップで、プロセスの実行時間が更新されました。次に、その実行時間が意図した時間を経過したかを確認します。疑似コードの中では、意図した時間は IDEAL_RUNTIME という値で表現されています。
もし、プロセスが、意図した時間より長く実行されていた場合、プロセスの切り替えを行うために schedule 関数を実行します。もし、そうでない場合は、そのままプロセスを切り替えずにリターンします。
if (curr->sum_exec_time > IDEAL_RUNTIME)
schedule();
IDEAL_RUNTIME の設定に関する実装次第で、プロセスの切り替え頻度やタイミングが調整できます。
3. プロセスの切り替え
プロセスの実行時間が意図した長さを超過し、プロセスの切り替えが開始される場合を見ていきます。 以下の schedule 関数へ入ったコードパスです。
void schedule(void) { struct task *prev, *next; prev = rq->curr; next = pick_next_task(prev); rq->curr = next; switch_to(prev, next); }
3.1. 次に実行すべきプロセスを選択する
疑似コードでは、次に実行すべきプロセスは、pick_next_task という関数で取得します。
この関数はシンプルで、実行キューの先頭のプロセス構造体を返します。
struct task *pick_next_task(struct task *prev) { struct task *next = list_first_entry(&rq->queue);
3.2. これまで実行していたプロセスを実行キューに戻す
これまで実行していたプロセスを、実行キューの一番最後に入れます。これにより、各プロセスが順番に実行されるようになります。
struct task *pick_next_task(struct task *prev) { struct task *next = list_first_entry(&rq->queue); enqueue_task(prev); // prev を queue の最後に入れる
もし、ここで、これまで実行していたプロセスだけを、実行キューの最後ではなく、先頭に近いところに入れると、このプロセスは他のプロセスよりも頻繁に実行のチャンスを得られるようになります。
3.3. 次に実行するプロセスを実行キューから外す
これから実行するプロセスが prev になってこの処理に戻ってくるときのために実行キューから外しておきます。
struct task *pick_next_task(struct task *prev) { struct task *next = list_first_entry(&rq->queue); enqueue_task(prev); dequeue_task(next); // next をキューから外す }
実行中のプロセスをキューから外すかは実装次第で、実行中のプロセスはキューの先頭に置いておいたまま、プロセス切替時に後ろへ移動するという実装もあります。
3.4. CPU コンテキストスイッチ
pick_next_task から、次に実行するプロセスのプロセス構造体を取得しました。次に、switch_to 関数を実行して、CPU の状態を切り替えます。switch_to 関数の詳細は複雑なので、今回は割愛しますが、CPU の実行環境がそれまで実行していたプロセスのものから、次に実行されるプロセスのものに切り替わったと思ってください。
void schedule(void) { struct task *prev, *next; prev = rq->curr; next = pick_next_task(prev); rq->curr = next; switch_to(prev, next); // prev から next へコンテキストスイッチ }
ここまでが、タイマ割り込みに起因したプロセス切り替えの一連の流れです。
タイマ割り込み以外からのプロセス切り替え
上記の処理が、スケジューラの主な流れですが、タイマ割り込み以外からもプロセス切り替えが発生することがあります。
例えば、プロセスが read や poll のようなシステムコールを実行し、入力を待機する場合には、そのプロセスは実行の機会を手放し、そのプロセスが利用可能だったはずの実行時間は、他の CPU を利用したいプロセスに割り当てられます。
Linux のプロセススケジューラ実装との比較
Linux のプロセススケジューラの実装は、ソースコードの中で、linux/kernel/sched 以下にあります。
以下は、今回の疑似コードとの簡易な機能面での対応表です。対象の Linux のバージョンは 5.3 です。詳細な箇所の実装の意図は、疑似コードと大きく異なる場合があるため注意してください。
| 疑似コード | Linux | Linux での実装ファイル |
|---|---|---|
| struct task | struct task_struct | include/linux/sched.h |
| struct runqueue | struct rq | kernel/sched/sched.h |
| enqueue_task | enqueue_task | kernel/sched/core.c |
| enqueue_task | enqueue_task_fair=>rb_insert_color_cached | kernel/sched/fair.c |
| dequeue_task | dequeue_task | kernel/sched/core.c |
| dequeue_task | dequeue_task_fair=>rb_erase_cached | kernel/sched/fair.c |
| pick_next_task | pick_next_task | kernel/sched/core.c |
| pick_next_task | pick_next_task_fair=>rb_first_cached | kernel/sched/fair.c |
| switch_to | __switch_to_asm | arch/x86/entry/entry_64.S |
| schedule | schedule | kernel/sched/core.c |
| timer_interrupt_handler | scheduler_tick | kernel/sched/core.c |
| timer_interrupt_handler | task_tick_fair=>entity_tick=>check_preempt_tick | kernel/sched/fair.c |
- 疑似コードは、Completely Fair Scheduling (CFS) スケジューラを参考にしました。
- CFS の実装では、キューがリストではなく、ツリーになっています。
- Linux のキューの実装では、CFS には struct cfs_rq が用意されており、struct rq のメンバとなっているものを利用します。
- Linux ではキューの対象のプロセス構造体は、直接的には task_struct ではなくて、CFS 用には、そのメンバの struct sched_entity が使われます。
- 実際の実装における実行時間の計測はさらに複雑です。
- CFS の check_preempt_tick では、直接 schedule 関数を呼ばずに、resched_curr で schedule が必要であることを示すフラグだけを立てて、以降の切り替え処理は割り込みコンテキストからのリターン前に行われます。
- wate や wake のような、タイマ割り込み以外からのプロセスの切り替えについては、activate_task、deactivate_task のような関数の実装について見ていくと良さそうに見えます。
仮想 I/O 高速化手法まとめ
仮想 I/O の高速化手法についてまとめました。特にネットワーク I/O の高速化について調べました。
デバイスの仮想化
仮想マシンが利用するネットワークカードは多くの場合、QEMU のようなエミュレータによってエミュレーションされており、物理的なネットワークカードとのやりとりはホスト上で動作する仮想スイッチを介して行われます。*1以下に構成を図示します。
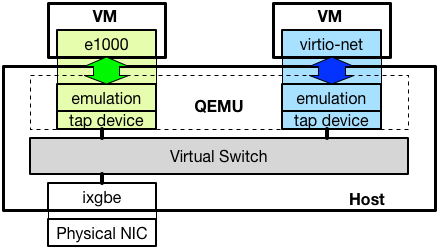
エミュレートされるデバイスは Intel の 1Gbps NIC 等、実際に存在するネットワークカードと、virtio-net のような、物理的なハードウェアが存在しないインターフェースがあります。
仮想化技術は大きく「完全仮想化」と「準仮想化」に分類されます。*2
完全仮想化によってゲストへ提供される環境は、ゲストからは、現実に存在する物理ハードウェアと全く同じように見えるようエミュレートされます。結果として、ゲスト OS は、仮想化された環境で動作していることを考慮することなく、物理ハードウェア上で動作するのと同じプログラムを実行できます。
具体的には、広く利用されている、Intel の NIC のような物理デバイスを仮想デバイスとしてエミュレートしてゲストへ提供した場合、ゲストは、多くの OS が標準的に実装している Intel NIC のデバイスドライバを、そのまま仮想ネットワークインターフェースのためのデバイスドライバとして利用できます。
これに対し、準仮想化環境では、ゲストが準仮想化環境へ対応するためのプログラムを実装している必要があり、既存のプログラムだけでは利用できないことがあります。例えば、virtio-net のような仮想デバイスは、専用のデバイスドライバが必要になります。
性能の観点では、準仮想化デバイスは、完全仮想化デバイスに比べ、エミュレーションコストを低く抑える工夫を取り入れやすいことから、性能を向上しやすいと言われています。一方で、完全仮想化デバイスは、ゲスト OS が既に実装しているデバイスドライバを利用することができるため、可搬性が高いと言われています。
仮想 I/O 実行方式
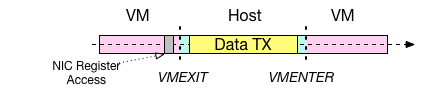
仮想デバイスの I/O は、VMEXIT のハンドラで実行される方式と、I/O スレッドによって実行される方式が考えられます。VMEXIT は、Intel VT-x の仮想化支援機構を用いて実装される仮想化環境で、実行コンテキストが仮想マシンからホストへ切り替わるときに発生します。仮想マシンが、ホスト側のエミュレーションが必要な命令を実行したり、外部からの割り込みをハンドルする際に発生するそうです。*3
前者の挙動を以下の図に示します。この方式は、Intel 1Gbps NIC ( e1000 ) 等の完全仮想化デバイスに多く採用されています。I/O のエミュレーションが、VMEXIT が発生した CPU で実行され、その間、仮想マシン自体の処理が中断されているという特徴があります。
もう一方の I/O スレッドによる仮想 I/O の図を以下に示します。こちらは、Xen の netfront/netback や、QEMU/KVM の virtio/vhost-net 等の準仮想化デバイスで多く採用されている方式です。最新の高速化手法も、この実行形式に則っているものが多いです。
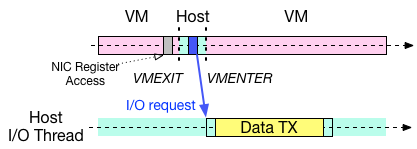
この方式においても基本的に、仮想マシンは、I/O をリクエストするために VMEXIT を発生させる必要がありますが、リクエストの完了後には、I/O の完了を待たずに仮想マシンのコンテキストへ戻ります。代わりに、リクエストを受けた I/O スレッドが仮想マシンのために I/O を実行します。
この方式では、仮想マシンと、I/O をそれぞれ別のスレッドで並列して実行することができるため、CPU が2つ以上ある場合には、並列化の恩恵により性能の向上が期待できます。具体的に、仮想マシン上で動作する Web サーバーを例にすると、仮想マシンのコンテキスト(図中ピンク色の部分)で、サーバーアプリケーションが HTTP のリクエストをハンドルする処理を行うのと同時に、ホストの I/O スレッドで HTTP レスポンスデータの送信処理(図中黄色の部分)を行うことができます。
一般的に利用されている仮想 I/O 機構
ハードウェア機能による I/O 仮想化 : SR-IOV
Xen の標準仮想ネットワーク機構 netfront/netback の論文 : Reconstructing I/O (University of Cambridge, Technical Report 2004)
QEMU/KVM virtio の論文 : virtio: Towards a De-Facto Standard For Virtual I/O Devices (ACM SIGOPS OSR 2008)
Xen 仮想 I/O 最適化
2005~2010 年には、Xen の仮想 I/O 機構である netfront/netback の性能を改善する論文が発表されています。
Optimizing Network Virtualization in Xen (USENIX ATC’06)
Bridging the Gap between Software and Hardware Techniques for I/O Virtualization (USENIX ATC’08)
Achieving 10 Gb/s using safe and transparent network interface virtualization (VEE’09)
VMEXIT を削減する
ELI: Bare-Metal Performance for I/O Virtualization (ASPLOS’12)
仮想デバイスはデータ送受信の際に、VMEXIT を発生させる必要があり、その VMEXIT による性能劣化が指摘されていました。
ELI の論文では、仮想マシンへの割り込みを、VMEXIT を発生させることなく、直接仮想マシンへ届ける手法 "Exit-Less Interrupt" を提案し、仮想化環境でも非仮想化環境と遜色ない性能を達成できることを示しています。
ELI の論文の詳細は、以下の解説がとても参考になりました。
constellation.github.io
Efficient and Scalable Paravirtual I/O System (USENIX ATC’13)
Efficient and ScaLable para-Virtual I/O System ( Elvis ) は ELI を採用した準仮想化 I/O 機構です。特徴として、仮想 I/O のために占有の CPU を用意して、複数の仮想マシンの I/O の処理をまとめて同じ CPU で行うことが挙げられます。図にすると以下のようになります。
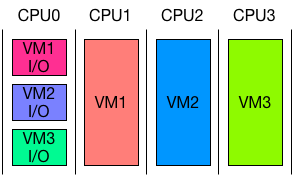
これにより、ホストのコンテキストで実行される仮想 I/O が常に、仮想マシンが動いている CPU と別の CPU で処理されるため、実行中の仮想マシンが、ホストの仮想 I/O の処理によって中断されることを避けることができ、結果として VMEXIT を削減しています。ELI と併用して、1NUMA ノードあたり、1コアを I/O のために割り当てるだけで、十分な性能が達成できるそうです。
Paravirtual Remote I/O (ASPLOS’16)
Paravirtual Remote I/O ( vRIO ) では、仮想 I/O を実行するためのホストを新たに用意し、仮想マシンと SR-IOV 経由でやりとりを行います。
仮想スイッチの最適化
Hyper-Switch: A Scalable Software Virtual Switching Architecture (USENIX ATC’13)
Hyper-Switch はネットワーク I/O がドライバードメイン(ホスト)を経由する必要があることについて、スケーラビリティの観点から問題があると指摘し、解決策として、仮想スイッチを Xen ハイパーバイザーの中へ実装するを提案しています。これにより、ドライバードメインを経由しない I/O を実現することができ、特に仮想マシン間通信の性能が向上できると述べられています。
Speeding Up Packet I/O in Virtual Machines (ANCS’13)
上の論文では、既存の仮想デバイスはそのままに、割り込みエミュレーションの実装部分への最適化と、仮想スイッチを高速なもの置き換えることで性能を向上しています。
NFV プラットフォーム向け仮想 I/O
高速パケット I/O フレームワーク登場以後、仮想マシンとパケット I/O フレームワークを組み合わせた NFV プラットフォームが複数提案されました。これらの特徴として、高速な仮想スイッチを適用することと、そのスイッチに適した仮想デバイスを実装していることが挙げられます。
QEMU/KVM + netmap = ptnetmap
Virtual device passthrough for high speed VM networking (ANCS’15)
Flexible Virtual Machine Networking Using Netmap Passthrough (LANMAN’16)
ptnetmap は、netmap の物理 NIC ポート、もしくは仮想ポートを仮想マシンに接続できるようにする技術です。ゲスト用のptnetmap デバイスドライバが用意されており、これを利用することで、ゲスト上で動作する netmap アプリケーションは、ホスト側で用意された netmap ポートを透過的に利用できます。
チュートリアルのスライドが以下の URL で見つかりました。
QEMU/KVM + DPDK
NetVM: High Performance and Flexible Networking using Virtualization on Commodity Platforms (NSDI’14)
Xen + netmap
ClickOS and the Art of Network Function Virtualization (NSDI’14)
Xen + netmap / QEMU/KVM + netmap
HyperNF: building a high performance, high utilization and fair NFV platform (SoCC’17)
HyperNF の論文では、Network Function アプリケーションを動かす仮想マシンを1つの物理サーバーへ集積する場合にむけた、リソース効率の高い仮想 I/O の実行手法ついて議論しています。特に、I/O スレッドによる仮想 I/O のモデルは、仮想 CPU と、仮想 I/O スレッドに別々に CPU リソースを割り当てる必要があり、それぞれへのリソース配分比率が性能に影響を与えることと、ワークロードごとに最適な比率が異なることを指摘しています。
以下のグラフでは、仮想 CPU と仮想 I/O のために、合計で 100% の CPU が割り当てられた仮想マシンの上で、ファイアーウォールを実行した場合の、仮想 CPU と仮想 I/O への CPU 割り当て比率ごとの性能の変化をプロットしています。
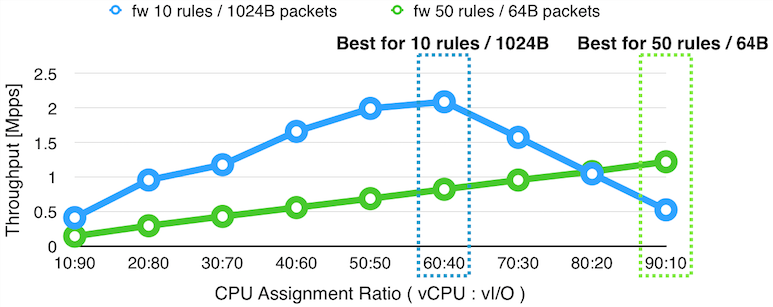
上のグラフの結果によると、50 のフィルタリングルールが入ったファイアーウォールを実行し、64 バイトのパケットをフォワードする場合(緑の線)には、仮想 CPU に9割、仮想 I/O に1割の CPU を割り振ると最大の性能が発揮されますが、10 のフィルタリングルールが入ったファイアーウォールを実行し 1024 バイトのパケットをフォワードする場合(青い線)には、仮想 CPU に6割、仮想 I/O に4割のリソースを割り当てたときに最高の性能が発揮されます。また、片側の場合で最大性能が達成される場合には、もう片方の場合で、最高性能と比較して約半分から4分の1まで性能が低下しています。
論文では、これらのことと、Network Function のコストと、パケットサイズが動的に変化することから、仮想 CPU と仮想 I/O の CPU リソースを固定的に割り当てることは、仮想マシンに割り当てられたリソースを使って最大性能を発揮するために適切ではないと主張しています。
また、仮想 CPU と仮想 I/O を別々の CPU で実行した場合には、ある CPU で実行されるスレッドが、同時に別の CPU のリソースを利用できないことから、CPU リソースが固定的に分割されるのと同じであることも指摘しています。
これらの問題の解決策として、論文では、仮想 I/O をハイパーコール*4のコンテキストで実行することを提案しています。CPU のリソース配置は Elvis と比較して、以下の図のようになります。
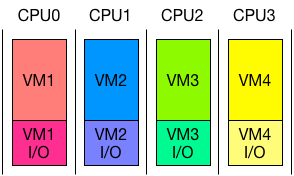
この実行形式では、仮想 CPU と仮想 I/O が常に同じ CPU で実行され、結果として、CPU リソースが仮想 CPU と仮想 I/O へ、常に最適な比率で配分されます。さらに、スケジューラーは、仮想 CPU と仮想 I/O をまとめて一つのスレッドとして扱うことができるため、標準的に実装されている Xen の resource cap/weight のようなリソース配分の仕組みを、より正確に適用することができます。
コンテナ + DPDK
OpenNetVM: A Platform for High Performance Network Service Chains (HotMiddlebox'16)
Flurries: Countless Fine-Grained NFs for Flexible Per-Flow Customization (CoNEXT'16)
これらの NFV 向け仮想 I/O 機構は、仮想マシンだけでなくコンテナに適用する研究も行われています。OpenNetVM と Flurries は NetVM を開発したグループによって発表されました。
参考資料
Reading the Paper, "ELI: Bare-Metal Performance for I/O Virtualization"
ハイパーバイザの作り方~ちゃんと理解する仮想化技術~ 第1回 x86アーキテクチャにおける仮想化の歴史とIntel VT-x
ハイパーバイザの作り方~ちゃんと理解する仮想化技術~ 第11回 virtioによる準仮想化デバイス その1「virtioの概要とVirtio PCI」
*1:物理デバイスを直接仮想マシンへ接続するデバイスパススルーという技術を利用した場合には、物理デバイスは、ホストを介することなく仮想マシンによって制御されます。
*2:https://syuu1228.github.io/howto_implement_hypervisor/part11.html
*3:https://syuu1228.github.io/howto_implement_hypervisor/part1.html
*4:仮想マシンがハイパーバイザーの機能へアクセスする仕組みで、システムコールと同じように、割り込みを起点に仮想マシンからハイパーバイザーへのコンテキスト切り替えが行われます。